

前回の記事
今回構築したファイルサーバーはいろいろな技術を使って成り立っていますので、1つ1つ紹介させていただきます。
連載予定は以下のとおりで、今回は⑥を紹介いたします。
連載予定
①:フェールオーバークラスター
②:クラスター共有ボリューム
③:記憶域スペース
④:記憶域スペースダイレクト
⑤:入れ子になったミラー加速パリティ
⑥:データ重複除去 【今回の記事】
⑦:シャドウコピー
⑧:BitLockerの解除キー(ADとリカバリキー)
番外編:DFS名前空間
⑥データ重複除去
物理サイズを超えてデータを格納できる技術です。
※100GBのディスクに200GBのデータを入れることが可能になるようなイメージ
今回構築したサーバーでは内部のファイルの種別にはよりますが、平均で「全データの40%」、多いところで「全データの70%」のディスク消費容量削減に成功しています。
仕組みとしては、 ファイル内にある同じデータの羅列 を見つけてまとめちゃおう! というシンプルなものです。
※といっても、これをファイルシステムレベルでできるのはすごいと思います。
イメージはこんな感じです。
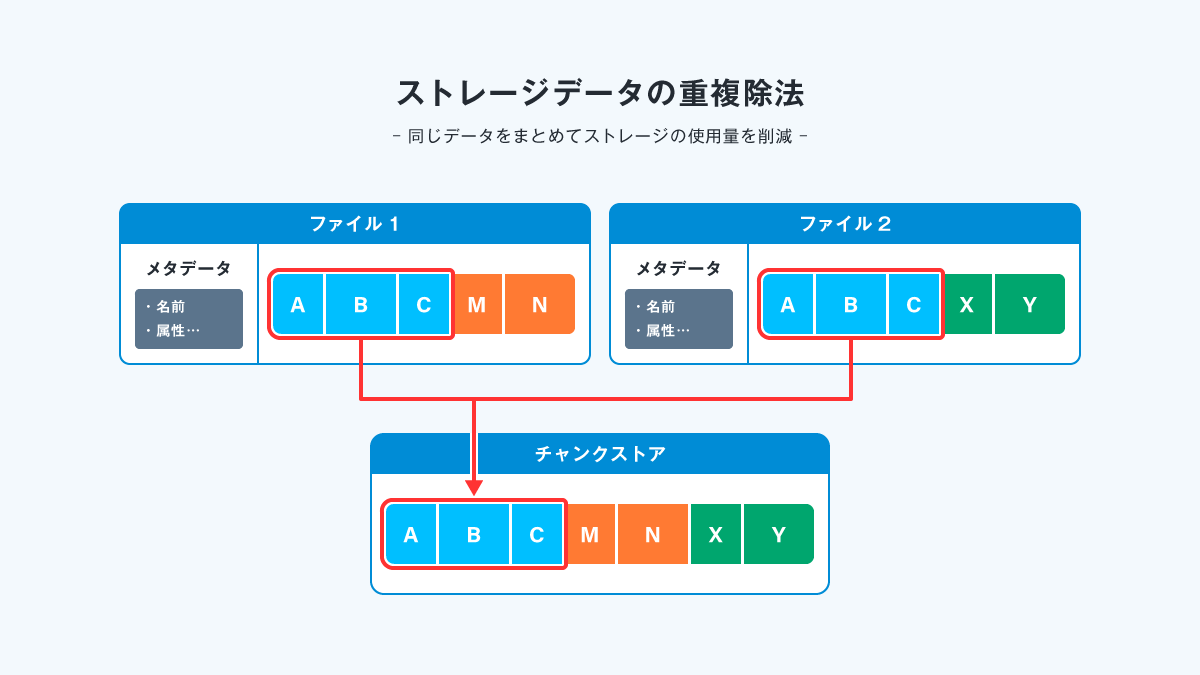
この機能は、データ書き込み時に動的に行われるものではなく
定期的に、 全データの中から同じような部分を見つけて、 まとめることで実現しています。
その仕組みはこんな感じです。
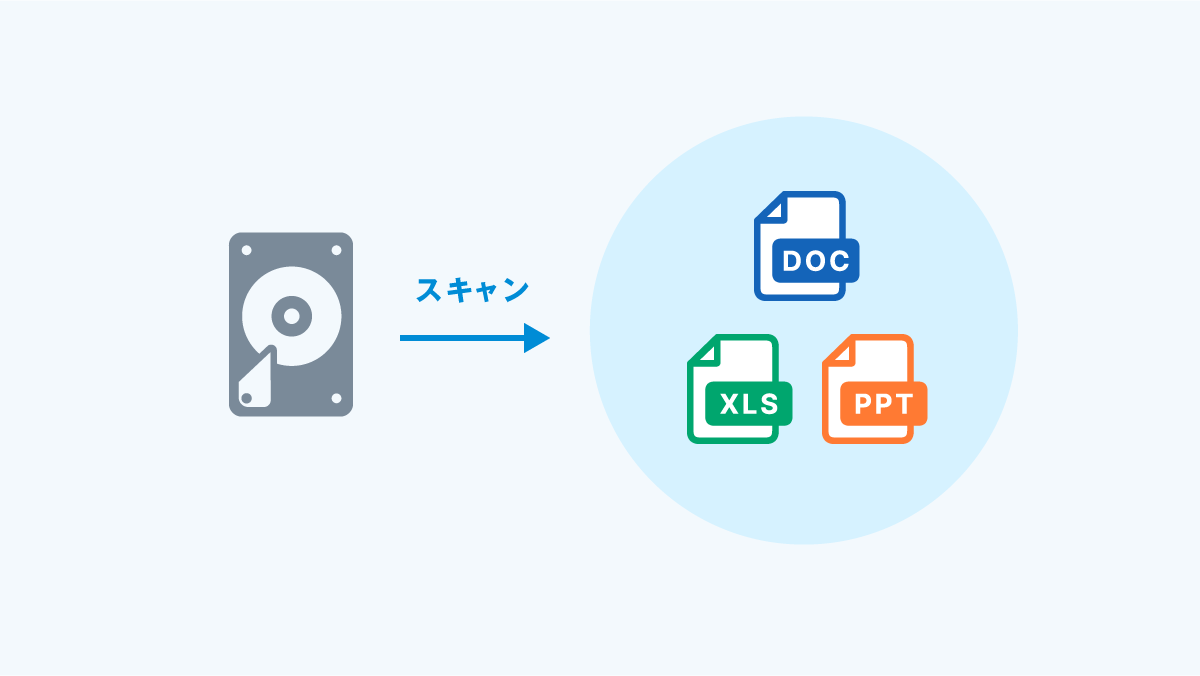
1. 条件を満たすファイルについて、ファイルシステムをスキャンします。
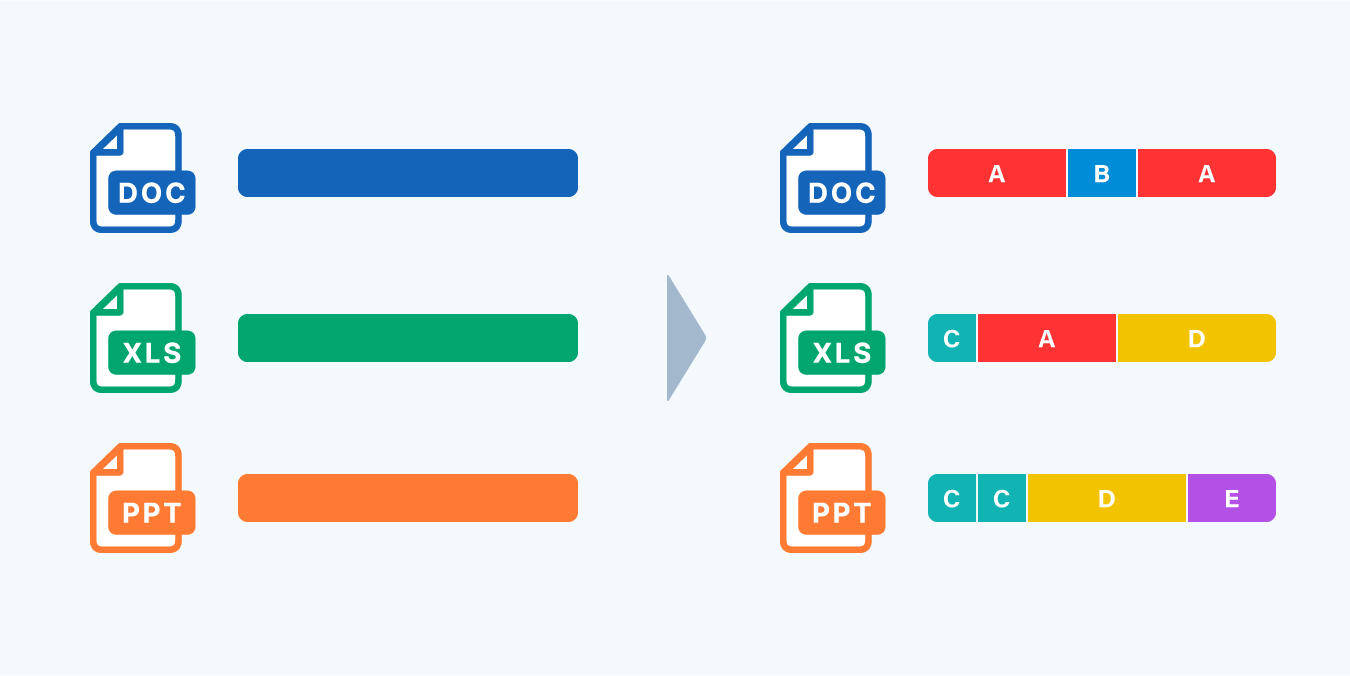
2. ファイルをさまざまなサイズのチャンク(塊)に分割します。
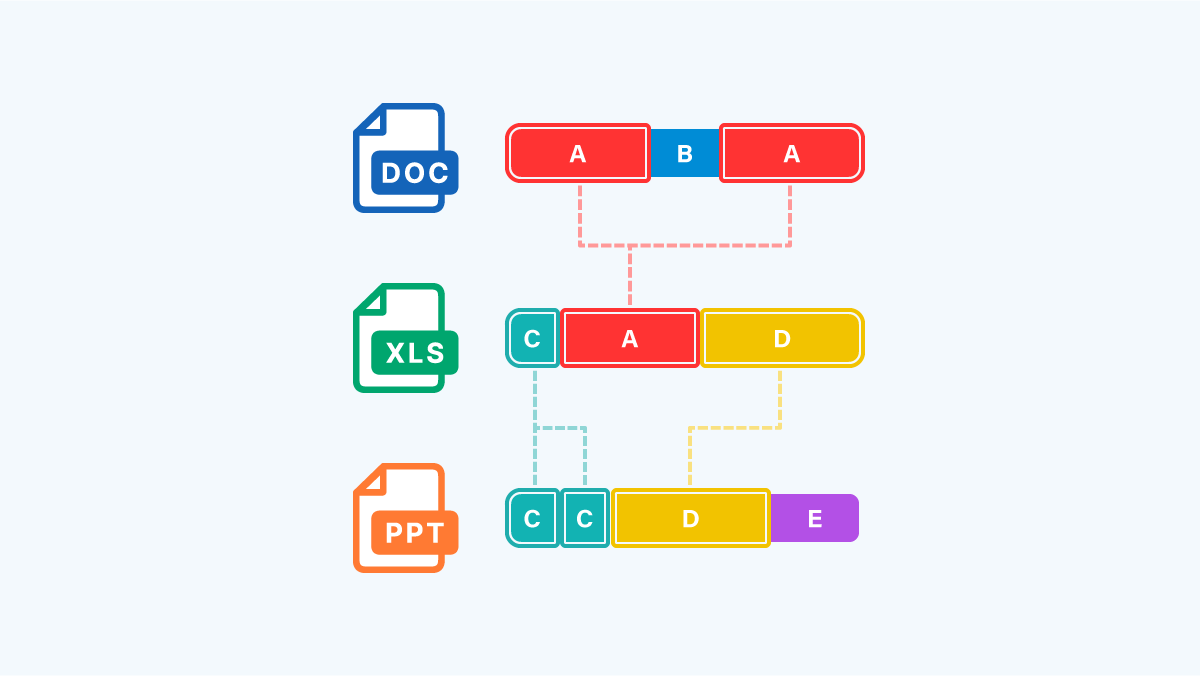
3. まったく同じデータのチャンク(塊)を探して名前をつけます。
4. チャンク(塊)をチャンクストア(ディスク上の整理済み塊領域)に配置し、必要に応じて圧縮します。
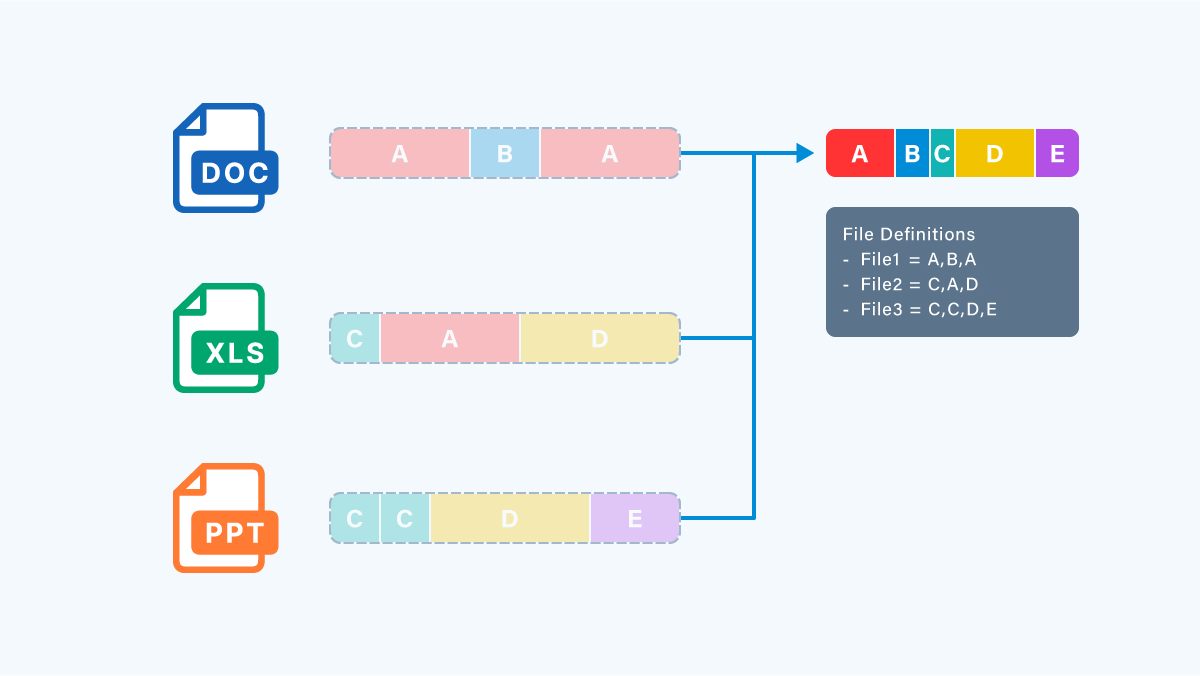
5. ファイル情報として、チャンク ストア(ディスク上の整理済み塊領域)のデータの組み合わせで元のデータとなるように、いい感じに記憶(再解析ポイント(RP)作成)します。
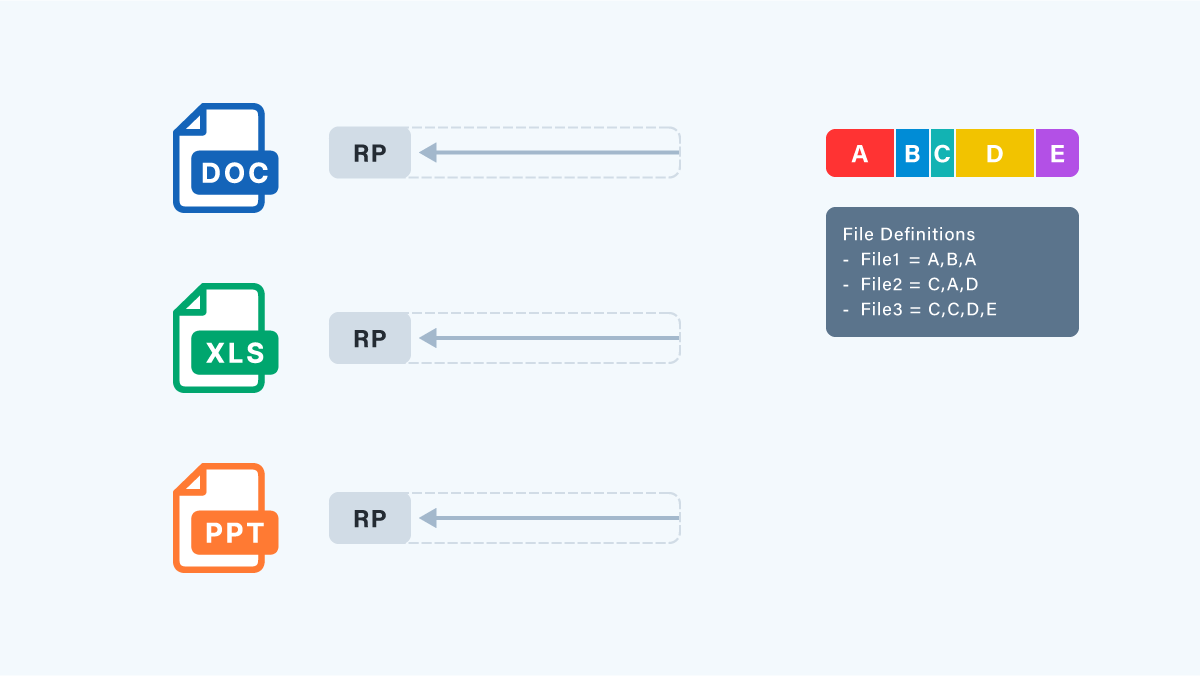
なんかファイルアクセス遅くなりそうと思われがちですが
物理ディスクから読み出すデータ量が減ったりすることもあるので本機能でファイルアクセスが遅くなることは、ほぼありません。
むしろちょっと早くなることもあるようです。
特に仮想環境のVHDなんかはかなりの効率でデータ重複除去できるのでオススメです。
というところで、今回はここまでです。
ありがとうございました。
