ビッグデータとは? 基礎知識から分析手法、活用事例をわかりやすく解説

IT技術が発展した現代では、あらゆる情報がデータとして日々生成されています。そんななかで注目を集めているのが、多種多様なデータを大量に蓄積した「ビッグデータ」です。ビッグデータを分析し、得られた知見をビジネスにおける意思決定に生かすことで、企業活動の効率化を図る組織が増加しています。この記事では、ビッグデータに関する基礎知識や分析の手法、活用事例などを詳しくご紹介します。
ビッグデータとは何か?
ビッグデータとは、「多種多様かつ巨大なデータ群」です。文章だけでなく、画像、動画、音声などのさまざまな形式のデータ群を指し、日常生活のなかで絶えず生成されています。
ビッグデータの特徴は、「データ量(Volume)」「多様性(Variety)」「処理速度(Velocity)」の「3V」と呼ばれる要素を高いレベルで備えていることだとされています。
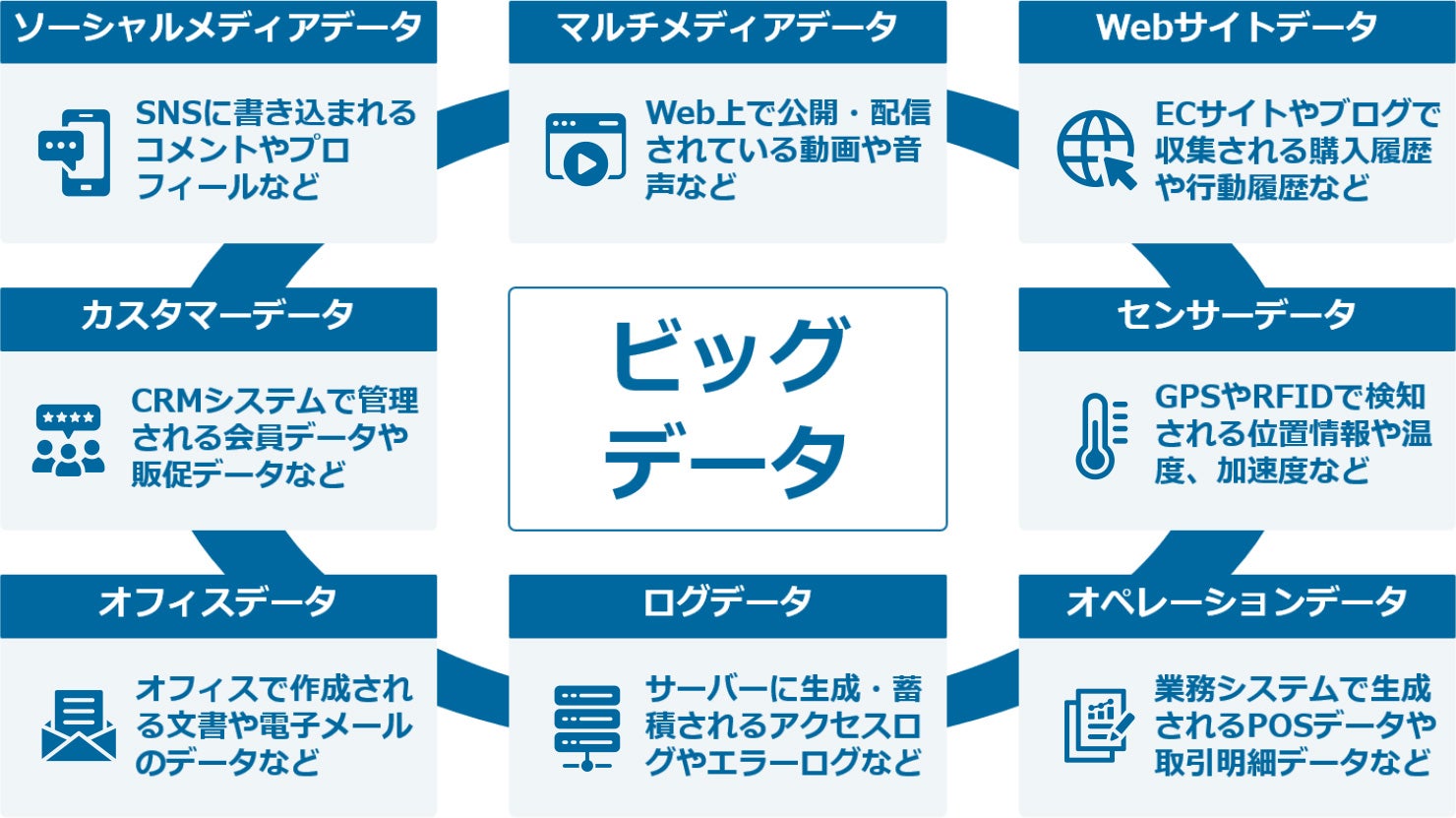
参考:情報通信審議会ICT基本戦略ボード「ビッグデータの活用に関するアドホックグループの検討状況」資料内・ビッグデータを構成する各種データ(例)を基に作成
ビッグデータにおける3Vとは
ビッグデータにおける「3V」とは、具体的には以下のような3つの特徴を表します。
| ビッグデータの3つの特徴 | |
|---|---|
| Volume(データ量) | 数テラバイトからペタバイト規模の膨大な容量を持つ。異なる性質を持つデータ同士を組み合わせての分析も可能。 |
| Variety(多様性) | CSV形式などの行と列によって表現可能な規則性のある構造化データだけでなく、画像や位置情報などの、多様な非構造化データも含む。 |
| Velocity(処理速度) | POSデータや交通系ICカードの乗車履歴データなど、データの発生速度や頻度が高く、リアルタイムな処理が必要。 |
ビッグデータという名称から、その膨大な「量」に目が行きがちですが、多様性や処理速度といった要素も、企業の事業推進に生かす上では欠かせません。なお、最近では新たに「Value(価値)」「Veracity(真実性)」の2つを加えて「5V」とする考え方も一般的になりつつあります。
Valueは、データそのものが価値を有していること、もしくは分析によって何らかの価値を生み出させることを示します。Veracityは、取り扱うデータの正確性を意味します。不要なノイズやデマ情報に注意して、信ぴょう性のあるデータかどうかを吟味することも大切です。
ビッグデータの身近な例
ビッグデータには、具体的にどのようなものがあるのでしょうか。身近な例を挙げると、スーパーマーケットや飲食店などの売上データであるPOSデータがその一つです。各店舗における日別や商品別の売上データが詳細に収集されており、商品開発や在庫管理、マーケティングなどに生かすことができます。
そのほか、ECサイトにおける顧客の購入履歴や商品の閲覧行動、WebサイトやSNS上に記載されている製品やサービスについての口コミ、スマートフォンなどのGPSで収集される位置情報もビッグデータにあてはまります。
ビッグデータが注目されている背景
「ビッグデータ」という言葉が現在のような意味合いで広く知れ渡ったのは2010年ごろからですが、それ以前からデータの解析自体は行われ、さまざまな分野で活用されてきました。なぜ近年になってビッグデータが注目されているのか、その要因をご紹介します。
データ量の増加
近年ビッグデータが注目されている要因として、インターネットの普及によるデータ量の爆発的な増加が挙げられます。
1990年代後半から各家庭にPCが急速に普及。2010年代からはスマートフォンが普及し始め、今や年代を問わず日常生活に欠かせない社会的なインフラの一つになりました。
インターネット利用人口の増加に伴い情報通信技術も飛躍的に発展し、現在では日々膨大な量のデータがやりとりされています。世の中全体のデータ量が増加したことで、ビッグデータの持つポテンシャルが注目を集めるようになりました。
PC性能の進歩
PCやIoT関連機器などの技術の進歩も、ビッグデータが注目されるようになった大きな要因です。
世界中のデータ量が増え、ビジネスに活用できる優れたアイデアが出てきたとしても、それら膨大なデータを収集し、正確かつ迅速に処理できる技術がなければ、データは活用できません。
現在、スーパーコンピューターに代表されるように、PCの性能は絶え間なく向上し続けており、かつては不可能と思われていた膨大な量のデータも低コストで処理できるようになっています。データ処理の技術が向上したことで、ビッグデータの収集や蓄積、分析に焦点が当たるようになったといえます。
AIの発展
ビッグデータが注目されている背景には、AI(人工知能)の発展もあります。
中でも、機械学習の一種である「ディープラーニング(深層学習)」と呼ばれる技術の発展によって、動画や音声など、規則性を持たないために分析が困難とされていた「非構造化データ」の分析精度と処理スピードが飛躍的に向上しました。
この影響で、これまでに企業が蓄積してきたビッグデータを効率よく分析し、事業にとって有用なデータを抽出・活用できるまでになりました。AI技術は今もなお目覚ましいスピードで発展し続けており、ビッグデータへの注目もより高まっています。

総務省が定義するビッグデータの分類
ここまでの内容をふまえ、ビッグデータとはどういうものなのか、定義や分類を改めて詳しく整理していきます。ビッグデータの定義や分類にはさまざまな考え方がありますが、総務省の「平成29年版 情報通信白書」では、「個人」「企業」「政府」を主体とするデータに着目し、4種類に分けています。ここでは、その4種類についてご紹介します。
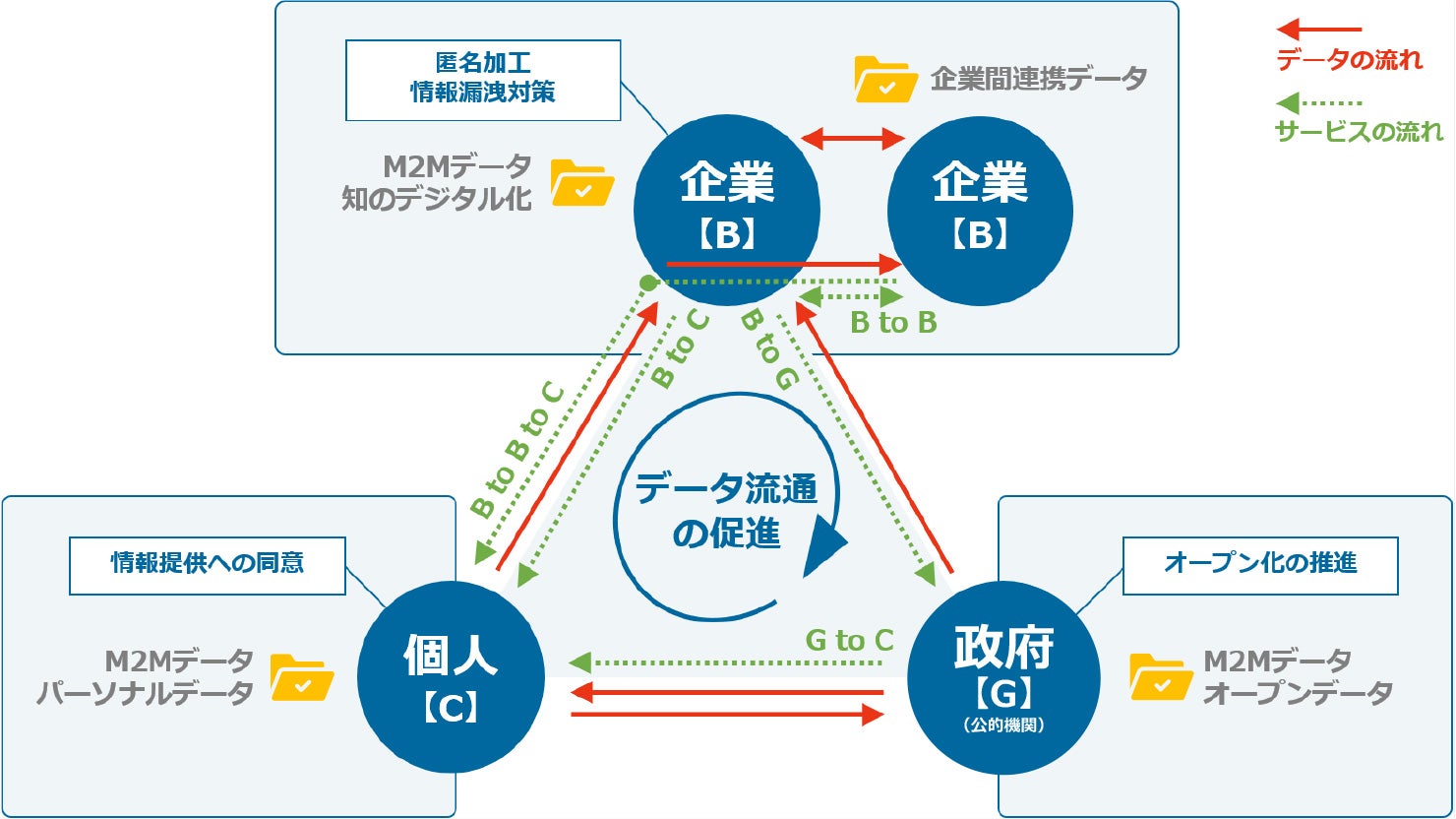
参考:株式会社三菱総合研究所「安心・安全なデータ流通・利活用に関する調査研究の請負 報告書」 資料内・データ主導社会におけるデータの位置付け・定義を基に作成
オープンデータ
オープンデータとは、国や地方公共団体がインターネット上に公開している統計データや公共情報のことで、許可された範囲内でなら誰でも自由に利用可能です。行政の透明性・信頼性の向上や、官民共同での公共サービス・民間サービスの創出を促進する目的があります。
なお、オープンデータに取り組むことは、「官民データ活用推進基本法」で国や地方公共団体に義務付けられており、経済の活性化や国際競争力の強化に向けて政府主導で活用を推進しています。
知のデジタル化
知のデジタル化とは、農業やインフラ管理、ビジネスなど、あらゆる産業や企業が得てきた暗黙知(ノウハウ)をデジタルデータ化・構造化して蓄積することです。
後述する「パーソナルデータ」を除き、身の回りに存在する人間の考え方や経験を蓄積することで、次世代へと成功体験を引き継ぐことを目的としています。高齢化などにより後継者不足が不安視される産業においては、知のデジタル化で得られるデータの活用が特に期待されます。
M2M(Machine to Machine)
M2M(Machine to Machine)とは、モノ同士が人手を介さずに通信し、機器の制御やデータのやりとりを行う技術のことです。
M2Mデータには例えば、工場などの生産現場におけるIoT機器から収集されるデータ、橋などの施設に設置されたIoT機器からのセンシングデータなどがあります。知のデジタル化で得られたデータとM2Mデータを合わせて「産業データ」と呼びます。
パーソナルデータ
パーソナルデータとは、法律で定義されている「個人情報」よりも広い意味を持つ用語で、個人に関連するあらゆる情報が含まれます。例えば、ウエアラブル機器から収集された個人の属性情報や、移動・購買履歴などのデータが挙げられます。
また、ビッグデータの適正な活用に向けて「改正個人情報保護法」で「匿名加工情報」の制度が設けられたことを踏まえ、特定の個人が識別できないように加工された人流情報(人が移動する流れに関するデータ)などもパーソナルデータに含まれます。
ビッグデータの種類
ビッグデータは、規則性の有無や表形式への変換が可能かどうかによって、「構造化データ」「非構造化データ」「半構造化データ」の3種類に大別されます。
なお、ICT技術の発達によって多様な情報が収集可能な現在では、「非構造化データ」と「半構造化データ」がビッグデータの多くを占めています。

構造化データ
構造化データとは、あらかじめ標準化された定義づけがなされ、効率的にアクセス可能な特定の表形式で整えられたデータのことです。名前や住所などを含む顧客情報の管理、製品の在庫管理の最適化など、企業活動の改善に活用できます。
構造化データには、以下のようなものがあります。
- Excelファイル
- POSデータ
- SQLデータベース
現在では、機械学習のアルゴリズムを用いた構造化データ分析によって、顧客の嗜好需要の予測が可能となり、マーケティング戦略の立案に役立っています。
非構造化データ
非構造化データとは、規則性を持たず構造化されていないデータのことです。現代の企業が生み出しているデータの大半は、構造化されていない非構造化データに該当します。
非構造化データには、以下のようなものがあります。
- テキストファイル
- 動画ファイル
- 音声ファイル
- SNSの投稿
こういった規則性のないビッグデータは従来の分析手法では扱いづらく、処理に膨大な時間が必要とされてきました。しかし、近年では、AIを中心とする技術の発展によってビッグデータの分析手法が劇的に進化したことで、非構造化データの積極的な活用が加速しています。
半構造化データ
半構造化データとは、構造化データと非構造化データの中間に位置するデータのことです。形式はあらかじめ完全に定められていないものの、ある程度の手を加えれば構造化が可能な状態のデータを指します。
半構造化データには、以下のようなものがあります。
- Webファイル
- JSON
- 電子メール
このようなデータは、構造化データより自由度が高く、非構造化データよりも容易に処理できるという性質を持つため、さまざまな分野で活用されています。例えば、HTMLからデータを抽出してWebサイトの改善点を検討したり、顧客の購買活動データを含むXMLファイルを分析して、製品の販売戦略の立案に役立てたりしています。
ビッグデータを活用するメリット
ビッグデータを活用すると、どのようなメリットがあるのでしょうか。ここでは、ビジネスにおいてビッグデータを活用する主なメリットを3つご紹介します。
高精度なデータ分析ができる
ビッグデータを活用するメリットの一つが、データ分析精度の向上です。従来、顧客の属性やニーズを把握するための分析材料は、アンケートなどでしか集めることができず、非常に限られた範囲の情報しか得られませんでした。しかし、膨大な数の製品とともに生み出され続けるビッグデータを活用することで、以前とは比べものにならないほど高精度なデータ分析が可能になり、より正確にユーザーのニーズを把握できるようになりました。
リアルタイムで現状を詳しく把握できる
ビッグデータは、生産速度や処理速度が非常に速いため、データをリアルタイムで処理し、現状の詳しい把握に役立てることができます。迅速な対応が求められる意思決定でも、経験や感覚ではなくデータに基づいた論理的な判断が可能になります。
意思決定の質が向上する
ビッグデータを活用することで、ビジネスにおける意思決定の質を高めることができます。ここまでにご紹介したとおり、ビッグデータを分析すると現状の把握や将来の予測を正確に行えるようになり、客観的なデータに基づいた意思決定をすることが可能になります。従業員の勘や経験に頼らない質の高い経営判断で、企業活動の効率化を図れます。
ビッグデータの活用に潜む問題点
ビッグデータの活用には大きなメリットがありますが、注意すべき点があることも忘れてはいけません。
ビッグデータには個人情報や機密情報といった重要データが含まれる場合が多いため、不正アクセスなどで情報漏洩が起こることのないよう、セキュリティ対策に細心の注意を払うことが重要です。社員に対するセキュリティ教育はもとより、不正な攻撃を検知する監視システムの導入なども検討する必要があります。
また、ビッグデータを活用するには、高度なスキルを持った人材を確保しなければなりません。そもそもの課題を把握する論理的思考力や分析手法の取捨選択をする洞察力、データ分析をする際のプログラミングスキルや、分析手法にまつわる深い知識など、高度なデータサイエンス技術が必要といえます。ただし、求められる技能を持つ人材は限られているため、積極的な教育や外部人材の登用による補強も大切です。
なお、ビッグデータを扱う上で、保守・運用コストがかかることも忘れてはいけません。セキュリティ対策の施された高性能なネットワーク機器やサーバーに加え、膨大なデータを扱うための大容量のストレージも必須です。データの収集や分析結果を保持するための運用管理も含めて、作業時間や費用面のコストを抑える視点も必要になってきます。
ビッグデータ活用におけるIoT・AIとは?
ビッグデータの活用に関して、よく取り上げられるのが「IoT」「AI」との関係性です。ビッグデータの収集にはIoT技術が欠かせず、また、蓄積したデータの分析・活用にはAI技術が必要になってきます。
IoTとは
IoT(Internet of Things)とは、身の回りのあらゆるモノをインターネットに接続して相互に情報をやりとりする仕組みのことで、「モノのインターネット」とも呼ばれます。
例えば、家電製品や自動車、工場の工作機械などのIoTデバイスに備えられたセンサーによって、それぞれのモノの役割に応じた多様なデータをリアルタイムに取得します。そうして収集した膨大なデータがクラウド上に蓄積され、ビッグデータとして活用されていきます。
AIとは
IoTの技術などによって収集・蓄積されたデータ群を扱いやすいかたちに処理して分析を行い、役立つ情報を抽出する役割を担うのが、AI(人工知能)です。
なお、AIが高精度な判断をするためには、膨大なデータによる事前学習が必須です。例えばAI搭載の顔認証システムでは、はじめに顔の画像データを大量に読み込ませることで、その中から顔の特徴やパターンを学び、次第に正確な顔認証が可能となっていきます。
近年ではAIの活用領域がさらに広がっており、インターネット上の膨大なデータをあらかじめAIに学習させることで、質問に対して自然な文章を出力するなど、文章や画像、音声などを自動生成できる「生成AI」が広く活用されるようになりました。資料作成や文章作成、情報収集、問い合わせ対応など、特定用途に限らず、さまざまな業務の効率化に活用されているのが特徴です。
IoT技術などによって収集されるビッグデータは、AIの精度向上に欠かせず、一方で、ビッグデータを効率よく分析するためにはAIの技術が欠かせません。ビッグデータとAIは、互いに補い合う関係性にあるといえます。

ビッグデータの分析手法
ビッグデータは、やみくもに収集するだけでは役立ちません。収集したデータを適切な方法で分析して初めて、企業の事業推進に役立つ知見を導き出すことが可能です。ここでは、ビッグデータの分析によく用いられる4種類の手法をご紹介します。

クロス集計
クロス集計は、複数の変数を同時に分析し、変数同士の傾向を明らかにするための分析手法です。
例えば、「ソロキャンプに興味があるか?」というアンケートをとり、その結果を年代ごとに集計すれば、年代別のソロキャンプへの興味の強さが把握できます。手法そのものはシンプルで理解しやすく、最も基本的な分析手法といえます。
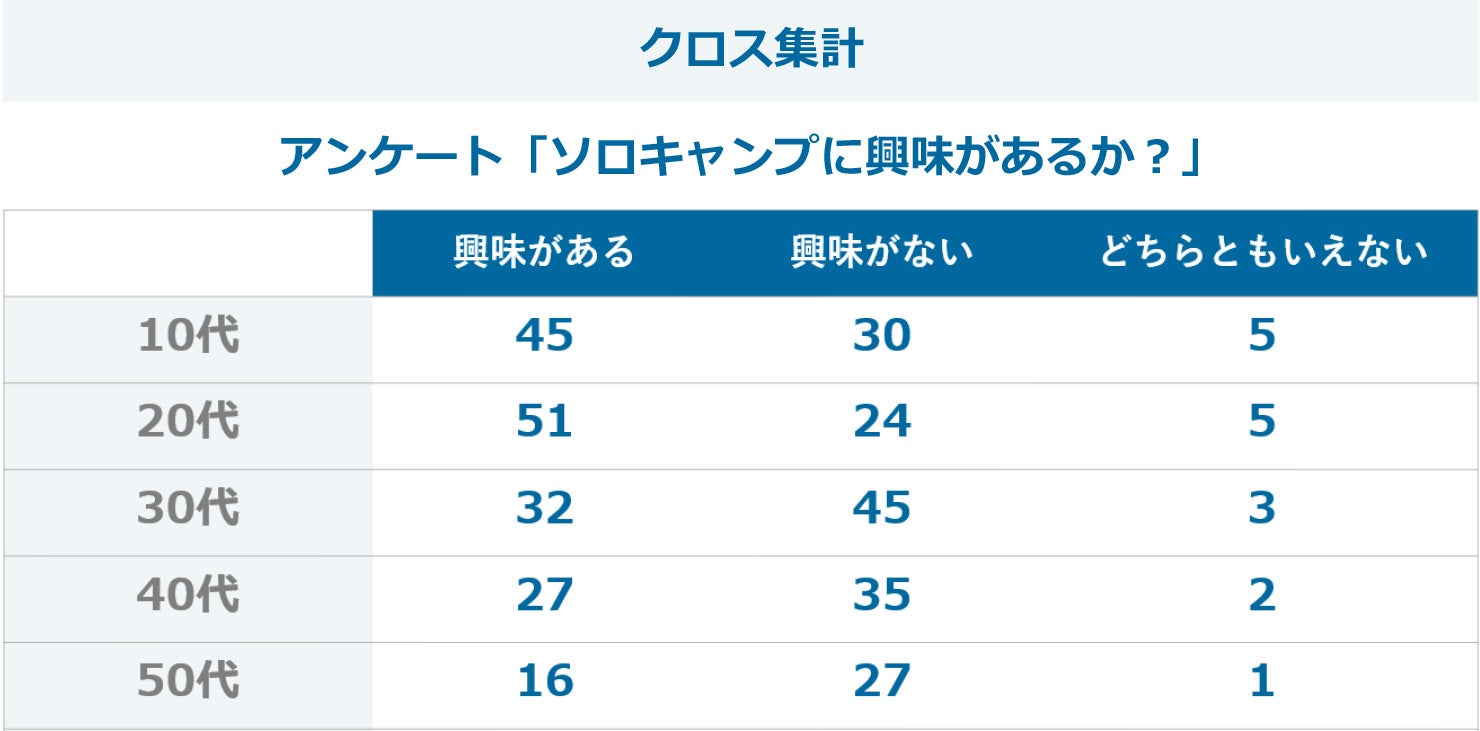
ビッグデータの場合、この変数が多岐に及びます。例えば飲食店やコンビニなどのPOSデータには、「商品名」「商品価格」「購入時間」「購入場所」「購入者の年齢層」「購入者の性別」など、さまざまな変数が含まれています。
各変数は相互に複雑な関係性を持つため、人力での分析は極めて困難です。ビッグデータのクロス集計分析では、膨大な変数に対して機械的な処理を施すことで、複雑な計算を用いることなく価値のあるデータが得られます。
ロジスティック回帰分析
ロジスティック回帰分析とは、ある特定の事象が起こる確率を求める手法です。複数の要因(説明変数)から「2値の結果(目的変数)」が起こる確率を予測します。既知の過去データを学習させる「教師あり学習」の一種で、それぞれの要因が結果に及ぼす影響の大きさを表す「回帰係数」を求めることで分析します。
なお、2値の結果とは、試験の合格 / 不合格のように、どちらか2つに限られる値を指します。分析によって得られるのは確率であるため、1(発生する)と0(発生しない)との間の数値です。
例えば、以下のような分析が考えられます。
- 予測したいこと:Aさんが40歳までに糖尿病に罹患する確率
- 複数の要因:1週間の運動時間 / 肥満か(BMIが25以上か) / 1日の飲酒量
- 2値の結果:糖尿病に罹患する / 罹患しない
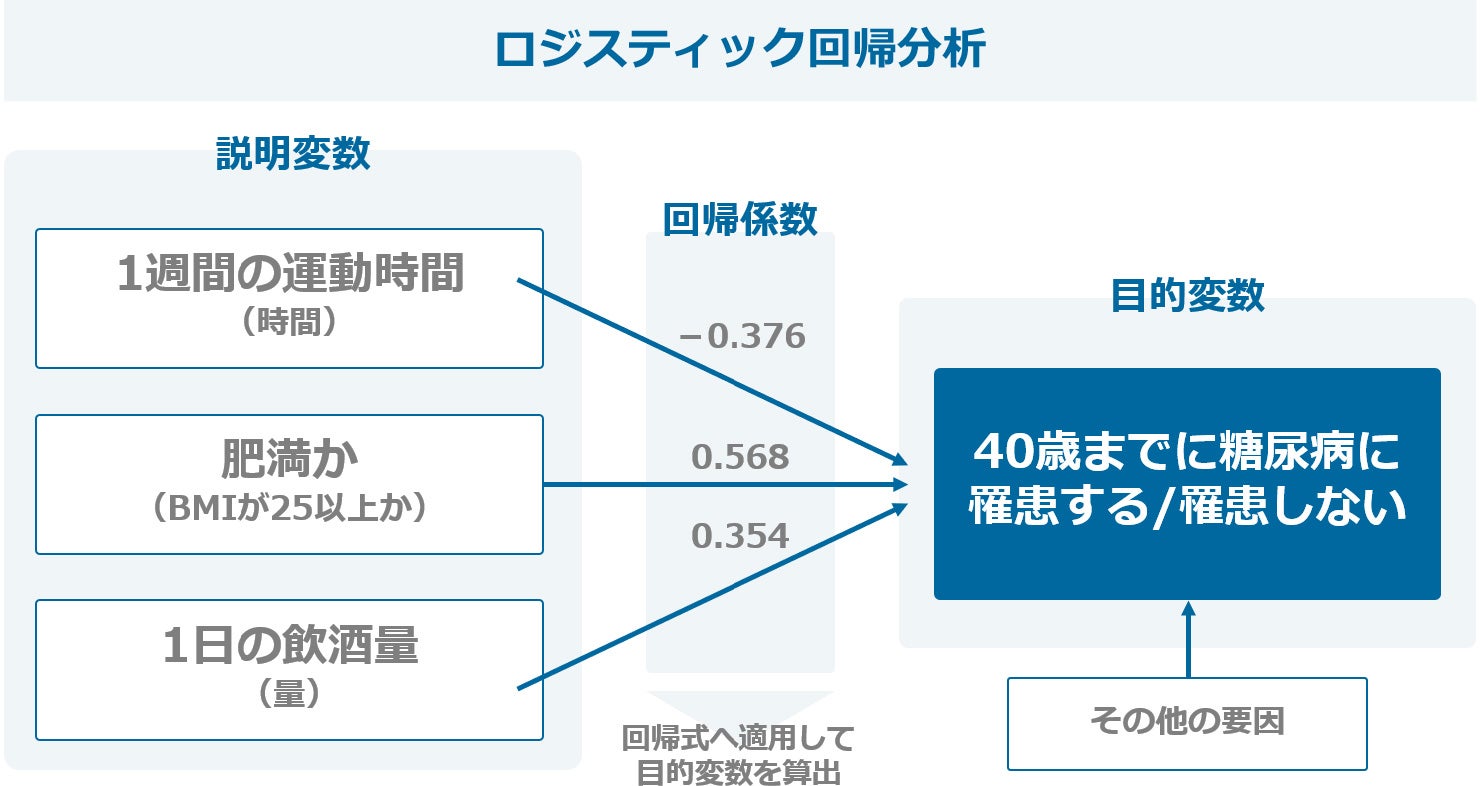
主な活用事例として挙げられるのは、マーケティングにおける顧客の購買行動予測や、保険会社の営業活動における契約の継続確率の予測などです。膨大な数の属性が複雑に絡み合っているビッグデータに対して適用することで、従来では考えられなかったような相関関係が見えてくる可能性も期待できます。
アソシエーション分析
アソシエーション分析とは、一見すると関係性の薄そうなデータ間に類似性を見つけることで、「AであればBだろう」といった因果関係(アソシエーションルール)を見いだそうとする分析手法です。
アソシエーション分析の有名な例として、「ビールとおむつの関係性」が挙げられます。ドラッグストアを対象にした分析で、「おむつを購入した男性の多くがビールも同時に購入している」という事実が判明したため、両者の商品棚を近づけて売り上げを伸ばすことに成功した、という事例です。
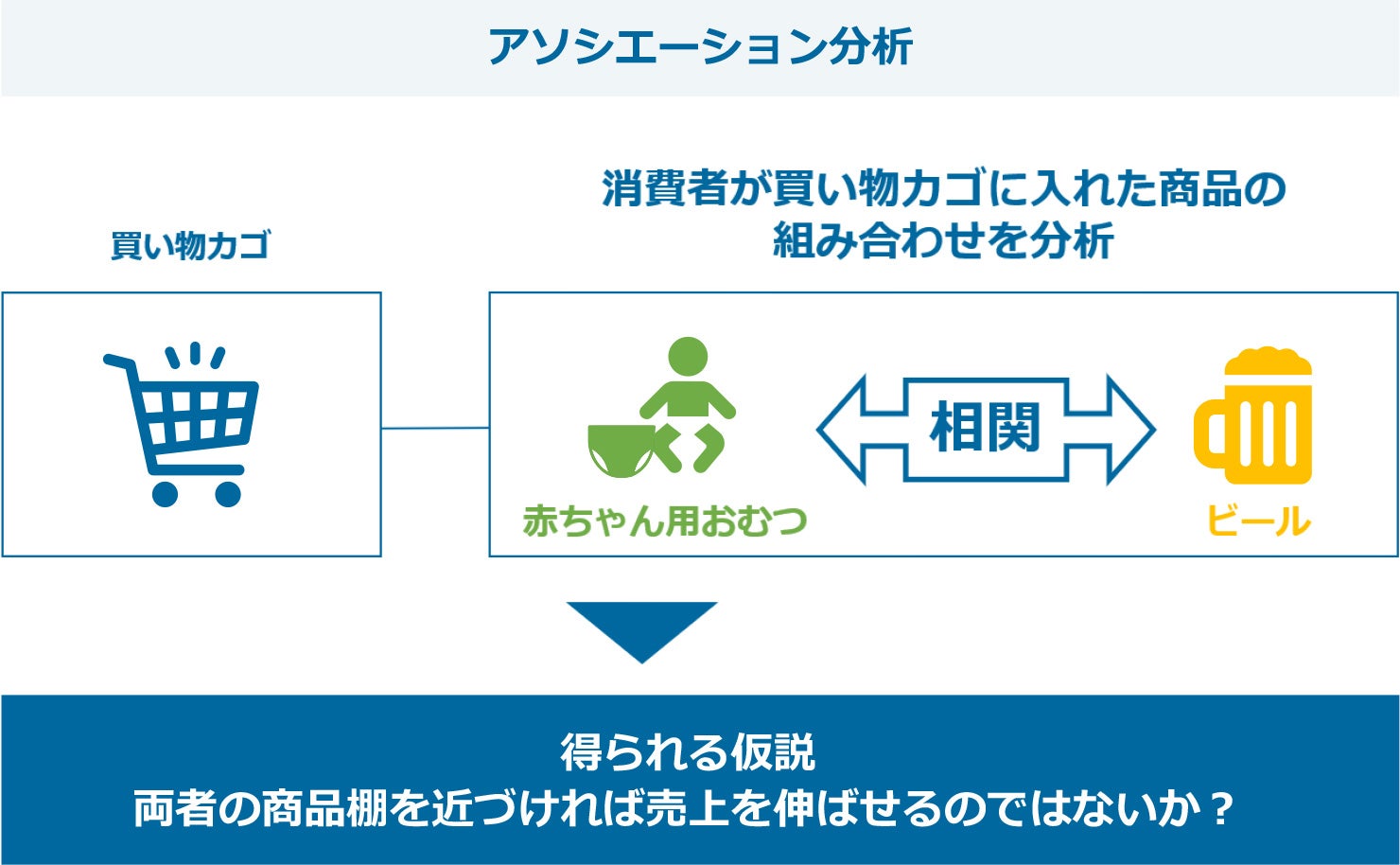
より具体的には、以下の手順でアソシエーションルールが生成できます。
- 3つの指標(支持度、信頼度、リフト値)を導出する
- 一定の支持度で線引きする
- 信頼度とリフト値で絞り込む
- 本当に正しいか、現場で活用可能かを確認する
支持度=「商品Aと商品Bが併せて買われる割合」を示す指標
信頼度=「商品Aと商品Bを同時に購入する人の割合」を示す指標
リフト値=「商品Aと商品Bを併せて購入した顧客の数」が「商品Bだけを購入した顧客の割合」に比べてどの程度高いかを表す指標
なお、AmazonなどのECサイトでよく目にする「この商品を買った人はこちらの商品もチェックしています」といったレコメンドにも、こうした分析手法が利用されています。
クラスター分析
クラスター分析とは、異なる性質を持つデータの中から「類似性」を基にクラスター(集団)をつくって分類し、その特徴を分析する手法です。なお、年齢や性別のような明確に分類できる「属性」ではなく、あくまでも明確に分類しきれない「類似性」を用いるのがポイントです。
例えば、製品のポジショニング分析や、顧客や商圏のセグメンテーションなど、マーケティングの現場で大量のデータを単純化して考察するためによく使われます。
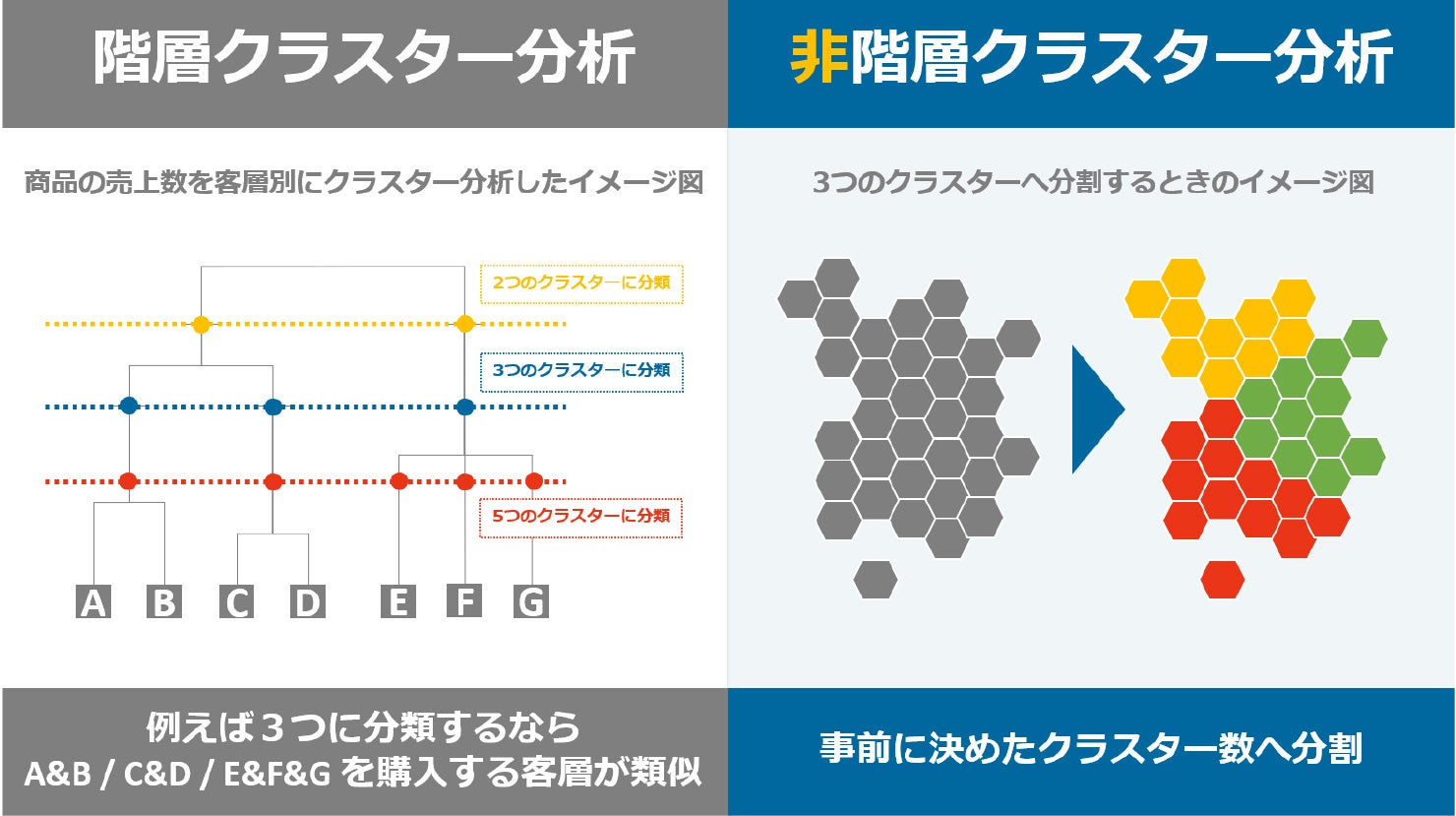
クラスター分析の手順は、大まかに以下のとおりです。
- 「分析の種類」を選択
- 分類の基準となる「類似度の定義」を選択
- 分析の種類・目的・仮説に適した「クラスターの形成方法」を選択
分析方法は、大きく分けて「階層クラスター分析」と「非階層クラスター分析」の2種類あります。階層クラスター分析では、類似度を基に階層構造を構築し、データのグループ分けを行います。非階層クラスター分析では、あらかじめグループ数を決めておき、類似度に応じて各データをグループに分類します。
なお、クラスター分析の注意点として、必ずしも明瞭に分類できるとは限らず試行錯誤が必要であること、各クラスターが持っている意味は自分自身で考察する必要があるため、結果に分析者の主観が入ることなどが挙げられます。
ビッグデータの活用事例【業界別】
マーケティング分野におけるビッグデータ活用の広がりは目覚ましく、さまざまな業界で役立てられています。ここでは、主要な業界のビッグデータ活用事例をご紹介します。
小売業のビッグデータ活用事例
小売業は、特にビッグデータ活用が広がっている業界です。例えば、「来店客の属性データ」「店舗ごと・商品ごとの売上データ」などから陳列する商品の種類や数を決定するなど、販売方法の改善に生かすことで利益の増加につなげられます。
またオンライン店舗でも、閲覧履歴や購入履歴を基に、個々の顧客の好みに合わせた商品を提案することが可能です。
農業のビッグデータ活用事例
農業でも、徐々にビッグデータの活用が進んでいます。気温や降水量、湿度などのデータをセンサーで取得する手法のほか、ドローンで空撮した畑の全体像をAIで解析し、害虫が発見された箇所への農薬散布を効率的に行うような手法も生まれています。
また、収穫に適した時期の作物を自動で収穫するロボットの運用や、照明センサーなどの各種IoT機器とAIを組み合わせてビニールハウス内の環境を自動制御するサービスの活用も始まっています。
製造業のビッグデータ活用事例
製造業では、工場内の設備管理や製品の品質管理など、ビッグデータの活用が飛躍的に進んでいます。例えば、生産ラインに備えたセンサー機器によって設備の老朽化を検知したり、生産効率・品質の低下を特定したりすることが可能です。
また、製造業ならではの問題として挙げられるのが、熟練者の技術を承継する難しさです。指導者不足を補いノウハウを継承するために、熟練者の目の動きをリアルタイムで追跡するアイトラッキング技術などの活用も進められています。
運輸業のビッグデータ活用事例
運輸業でも、これまで業界が慢性的に抱えていた問題の解決などを目的に、ビッグデータ活用が積極的に進んでいます。例えば、交通系ICカードの利用で収集されるデータは、電車の運行本数や運行頻度の調整に役立てられます。
また、荷物の配達については、出荷状況や気象条件などのデータを基に費用対効果の高い配送経路の選択が可能になっています。さらには、航空機のセンサーから得られるエンジンの回転数などをデータ解析することで、部品に不具合が起こる前に交換して事故を防ぐこともできます。
教育関連のビッグデータ活用事例
教育関連のビッグデータ活用では、「EdTech(エドテック)」という言葉が知られています。これはEducation(教育)とTechnology(テクノロジー)を組み合わせた造語で、教材としてタブレット端末を利用するなど、先端技術を用いた教育支援のあり方を表す言葉です。
例えば、個別指導塾や大手予備校などの学習支援業界でも、AIが学習履歴や試験結果などの情報を分析し、学生一人ひとりのレベルに応じて教材や学習の進め方を提案するサービスが活用されています。文部科学省でも、このような教育におけるビッグデータの活用を推進しており、研究が進められている最中です。
医療・福祉のビッグデータ活用事例
医療・福祉の現場では、患者の健康状態に合わせた個別のケアが絶えず求められるため、医療関係者の人手不足や心身の負担の大きさが深刻な問題となってきました。
ビッグデータを活用することで、患者の健康上の問題を早期に発見し、本格的な介護が必要になる前段階で食生活や運動習慣を見直すなどの対策が可能になりました。また、職員のスキルや就業状況データの活用により、医療現場における人材配置やシフト管理の最適化も期待できます。
さらに、新薬の開発サイクルを短縮したり、患者の健康状態や生活習慣に関するデータから将来の重大疾病への罹患を予測することも可能になっています。
ビッグデータに関する今後の展望
ここまでご紹介したように、すでにビッグデータはあらゆる領域で多大な恩恵をもたらし始めており、今後もますますの発展が見込まれています。
通信技術やIoT技術がさらに発達・普及すれば、より多くのビッグデータをスムーズに取得できるようになると考えられます。こうした技術の発達と併せて、国全体で「デジタル戦略」が推進されれば、今まで活用しきれていなかったビッグデータの掘り起こしも期待できます。
また、収集・蓄積されたデータの活用は、「BIツール」と呼ばれる支援ツールの進化によって誰もが簡単にできるようになりつつあります。BIとは「Business Intelligence」の略で、BIツールとは、企業が保有するビッグデータを集約・分析して経営判断を支援するためのツールです。
高度なデータサイエンス技術を持つ人材の需要は今後も尽きないと予想されますが、分析のハードルが下がることで、ビッグデータの活用はより一層身近なものになっていくと考えられます。
まとめ
ここまで、ビッグデータの定義や特徴、分析手法や活用の仕方などについてご紹介しました。AIやIoT技術の発達、通信の高速化によって、ビッグデータは今後ますます身近なものとなることが予想され、小売業や教育、医療など、あらゆる分野での活用が期待できます。
データ活用が企業の発展に大きく影響する現在、あらゆるデータを収集・蓄積し、可視化や分析などに利活用する仕組みづくりと、データの管理・統制が重要になっています。Sky株式会社は、コンサルティングやマネジメント、構築、活用支援など、さまざまなフェーズでお客様のデータ活用をご支援します。ビッグデータのビジネス活用をご検討の際には、ぜひSky株式会社までご相談ください。
データ活用に関するお問い合わせはこちら
お問い合わせ
関連コラム

