

前回の記事では、SKYPCEでの名刺のデータ化に活用している自社開発のAI-OCRについて紹介しました。
前回の記事
本日はAI-OCR紹介第2弾として、AI-OCRで使用しているVision & Languageモデルのさまざまな活用について紹介します。
概要
次に紹介する3つの活用は、OSSで公開されている Deep Learning の Vision & Language モデルをベースとして、一部をカスタマイズし、名刺データを用いて End to End の学習を行ったものです。 入力を「名刺画像」としている点は共通ですが、出力に相当する「最終データ」の形式をそれぞれの実現したいことに変更して学習しています。
活用事例
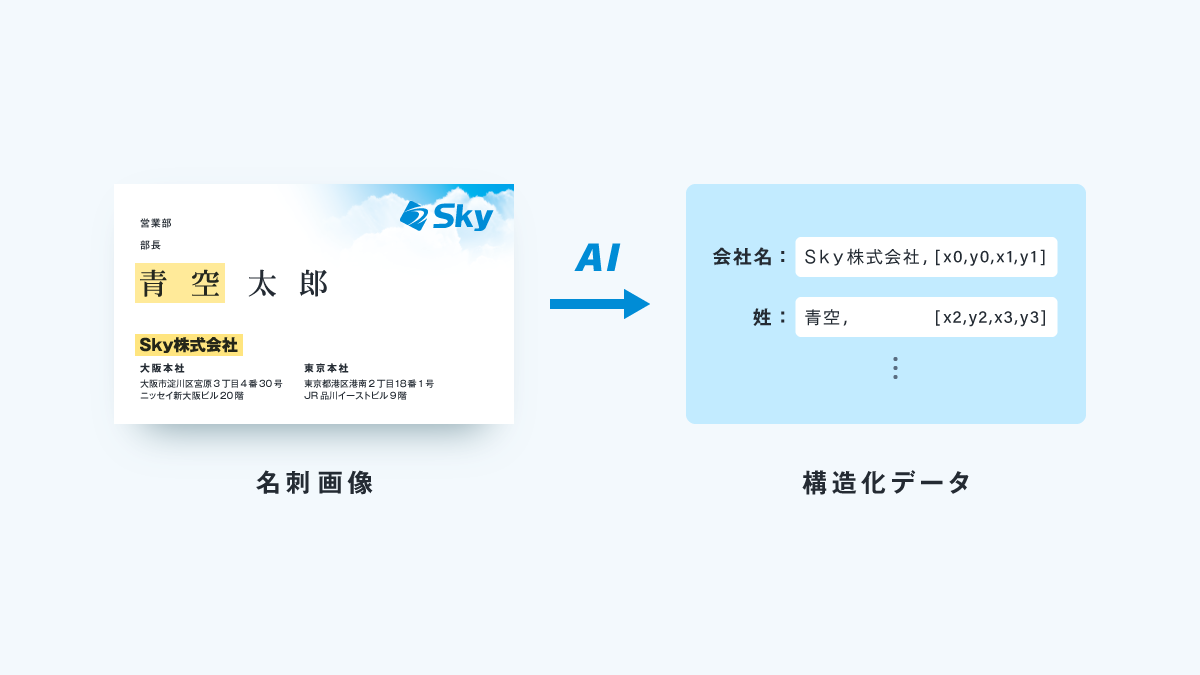
① 矩形の検出
これまで出力していた、会社名・姓・名・住所などの各項目のテキスト情報に加え、各項目の位置情報についても出力を行うことができます。
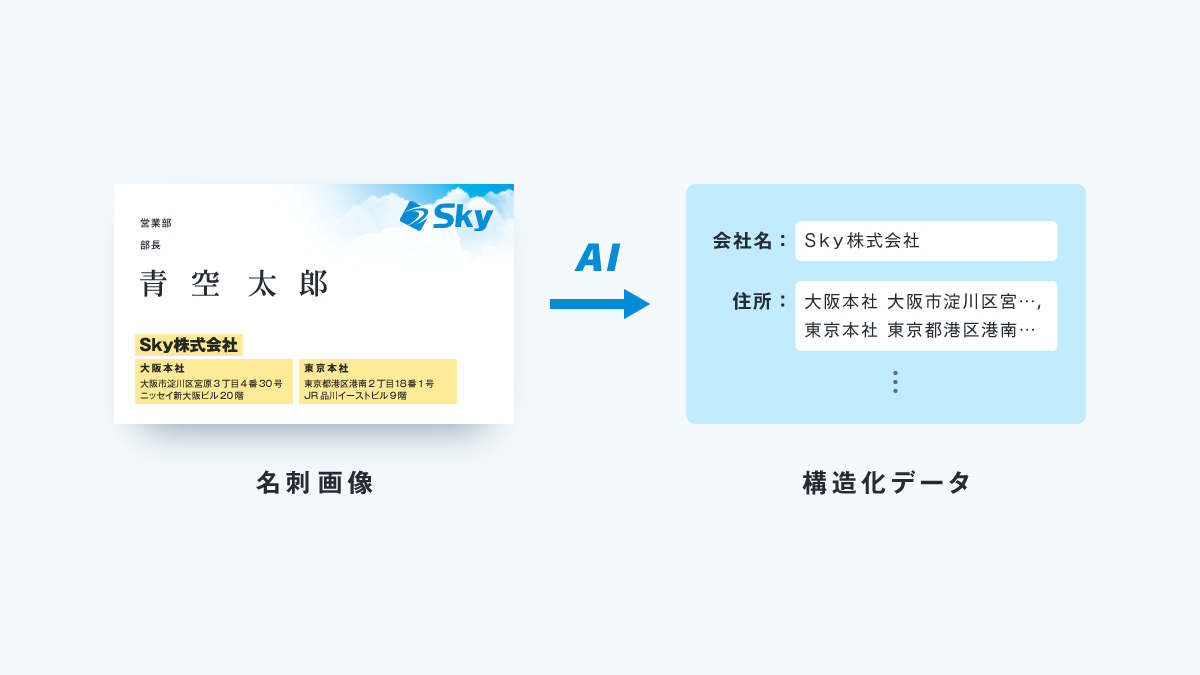
② 複数項目の検出
名刺には各拠点の複数の住所や電話番号が記載されている場合があります。
それぞれを出力することができます。
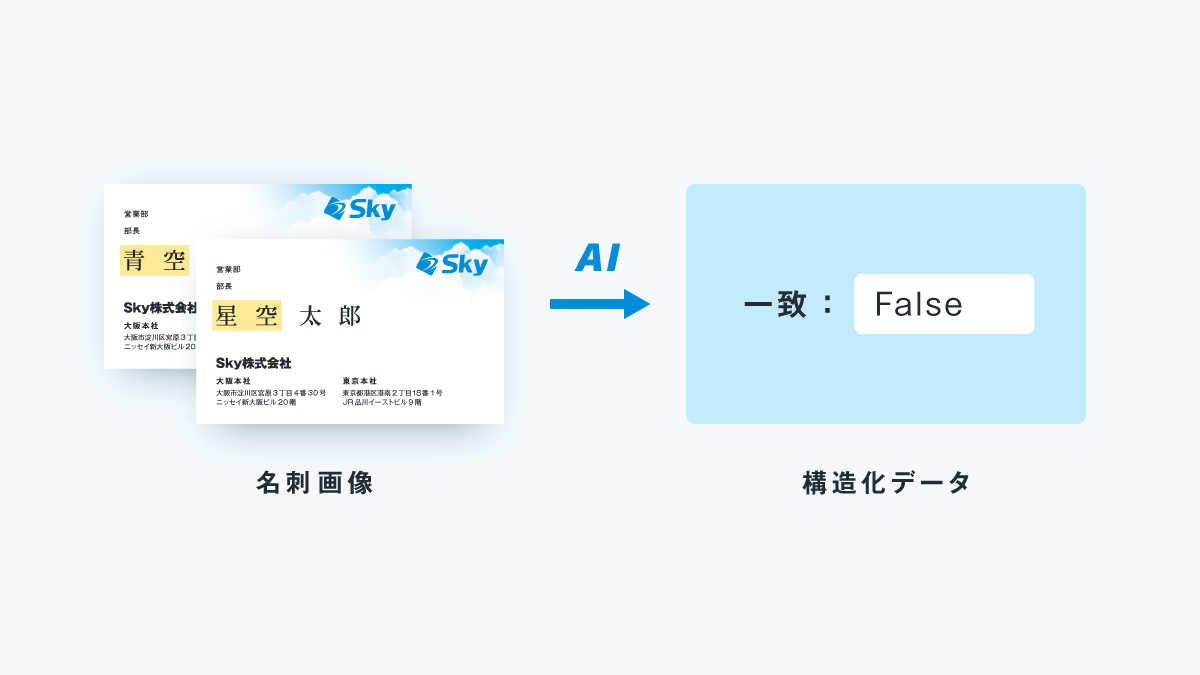
③ 2画像の比較
既に取り込んだ名刺と、新たに取り込まれた名刺が一致しているかを判定することができます。
2枚の名刺に大きな違いがなくても、一致・不一致を判断することができます。
まとめ
Vision & Language モデルであれば、出力側のフォーマットは自由であり、実際に様々な出力形式を試してきましたが、思った以上に活用の幅が広いです。
最後に
私たちのTech Blogを最後までお読みいただき、ありがとうございます。
私たちのチームでは、AI技術を駆使してお客様のニーズに応えるため、常に新しい挑戦を続けています。
最近では、受託開発プロジェクトにおいて、LLM(大規模言語モデル)を活用したソリューションの開発ニーズが高まっております。
AI開発経験のある方やLLM開発に興味のある方は、ぜひご応募ください。
あなたのスキルと情熱をお待ちしています。
