

SKYPCEでの名刺のデータ化については、自社で開発したAI-OCRを活用しています。 このAI-OCRについてご紹介します
機能
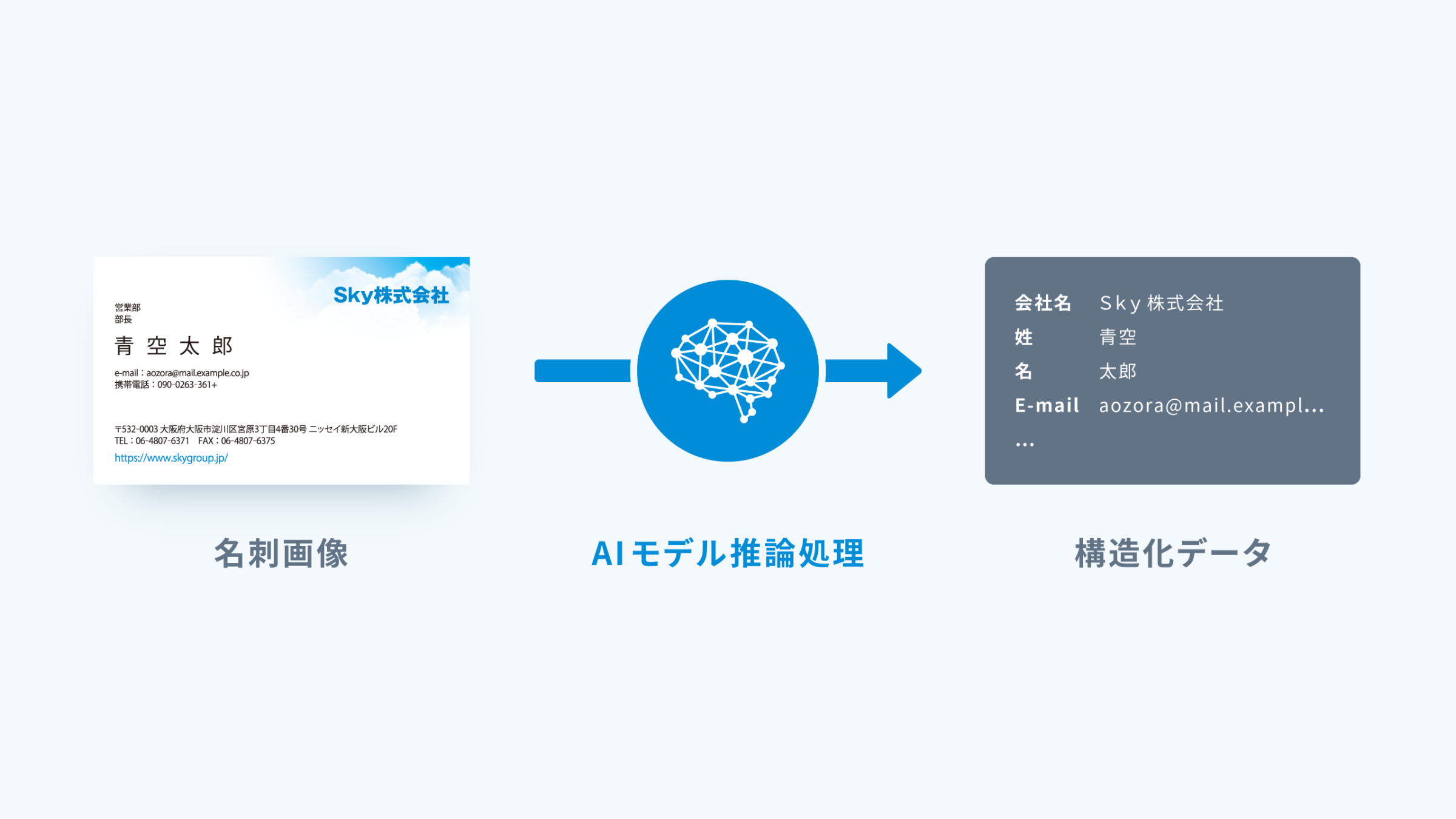
名刺画像を入力することで、会社名・姓名・住所などの各項目のテキスト情報が読み込まれ、構造化データとして出力できます。 ポイントは特に読み取る場所を指定しなくても、画像上のどこに該当する項目があるかを判別し読み取ってくれることです。 名刺においては各項目が名刺上のどの位置に記載されているかは明確なルールが無いため、とても重要です。
開発
AIモデル & 学習方法
OSSで公開されている Deep Learning の Vision & Language モデルをベースとして、一部カスタマイズし、名刺データにて End to End の学習を行っています。
そのため、学習用データとしては、入力に相当する「名刺画像」と出力に相当する「最終データ」があればよく、この SKYPCE の AI-OCR は End-to-End 学習に非常にマッチします。
名刺はフォーマットがあるようで実はありません。(お店の名刺で姓名が無い、会社名に相当する団体名等が多数あって特定できない、等) そのため、決まった項目に落とし込むためには、様々なイレギュラーケースを想定したデータ化ルールが存在しますが、それをいちいち考慮していたのではきりがありません。 Deep Learning のEnd-to-End 学習により完ぺきではないもののある程度のルールに自動的に対応できています。
学習最適化
パラメータチューニングなどは当然行いますが、重要なポイントとしては、Tokenizer が対応している Token 内容になります。 元々用意されている環境では、多くの言語にて文字・単語が対応されてますが、日本語の文字(漢字含む)のカバー率が十分ではありません。 この場合、単漢字として Token が用意されていなければ当然予測不可能になります。そのため、特殊な文字・漢字については一通り Token を追加しており、人名、地名などにもしっかり対応できています。
その他
本AI-OCR開発は、開発着手から約半年という短期で開発・実運用化しています。 技術アドバイザーである 中部大学 藤吉 弘亘教授 や 九州大学 内田 誠一教授 にもこの開発にご助力頂きましたが、 この短期間での開発・実運用化について、「Deep Learningをはじめとする最新の機械学習技術群とSky株式会社独自のデータ技術を適切かつ迅速に融合できた点が素晴らしい」というご感想を頂いてます。
以上、よろしくお願いいたします。
