

前回の記事
SKYDIV Desktop Client を支える技術の一つ、「SQL Server Express 冗長化」をご紹介いたします。
SQL Serverには上位エディション(Standard/Enterprise)で利用可能な「SQL Server Always On」という冗長化機能があります。
上位エディションということもあり、結構高価で高級な機能になっています。
そこまで高級な機能でなくてもいいから、もっと安価であったら、、、
競合製品と比較して大きなアドバンテージを得ることができますよね。
そこで SKYDIV では無償で利用できる SQL Server Express Edition を使用する場合でも、Always On のような冗長性と信頼性を担保できるように「SQL Server Express 冗長化」機能を独自に実装して製品に搭載しています。
今回は要素技術の 1 つである「フェイルオーバー(Failover)」についてご紹介いたします。
シリーズ一覧
①システム構成編
②フェイルオーバー【今回の記事】
③レプリケーション
④トランザクション編
⑤リダイレクト
フェイルオーバーとは
フェイルオーバーとは、システムの一部が故障した際に、予備のシステムに自動的に切り替えるプロセスを指します。
これによってダウンタイムを最小限に抑えることができ、サービスの継続性が確保されます。
「自動的に」予備システムに切り替えるには故障を検知するアルゴリズムが必要になります。SKYDIV では、このアルゴリズムとして「分散合意アルゴリズム」を採用しています。
分散合意アルゴリズム
分散合意アルゴリズムは、分散システムにおいて複数のノードが一貫した状態を保つためのアルゴリズムです。これによってシステム全体が一つの一貫したデータベースのように動作することができます。
分散合意アルゴリズムの代表的な例としては Paxos や Raft があります。
これらのアルゴリズムは、ノード間の通信や障害発生時の対応を考慮しながら、データの整合性を保つことを目的としています。
SKYDIV では、多数決を基本として分かりやすくイメージしやすかった「Raft」を採用しています。
Raft とは
Raft は 2014 年にスタンフォード大学の Diego Ongaro と John Ousterhout によって提案された分散合意アルゴリズムです。
Raft は Paxos の複雑さを解消し、理解しやすく実装しやすい合意アルゴリズムを目指して設計されました。
Raft の基本原理
役割
Raft では各ノード(サーバー)は以下の 3 つの役割のいずれかを担います。
- リーダー(Leader):
クライアントからのリクエストを受け取り、データを他のフォロワーに複製します。 - フォロワー(Follower):
リーダーから送られたデータを自身に複製します。 - 候補者(Candidate):
リーダー選出のための投票に立候補します。
SKYDIV ではデータの複製についてはレプリケーションで行うので、リーダー選出についてだけ Raft を採用しています。
リーダー選出
リーダー選出は以下の手順で行われます。
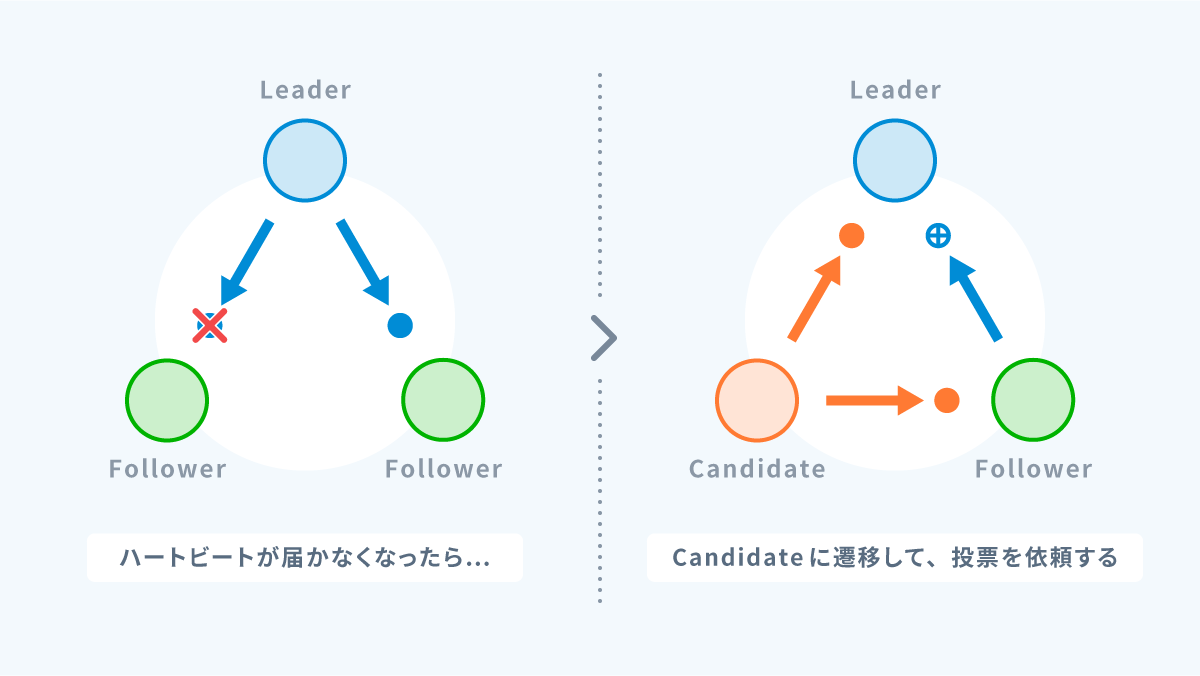
- タイムアウト:
リーダーからのハートビートが一定期間フォロワーに届かなかった場合、フォロワーは候補者に昇格します。 - 投票要求:
候補者は他のすべてのノードに対して投票を要求します。 - 投票:
各ノードは 1 つの候補者に投票します。過半数の投票を得た候補者がリーダーに選出されます。
ハートビート
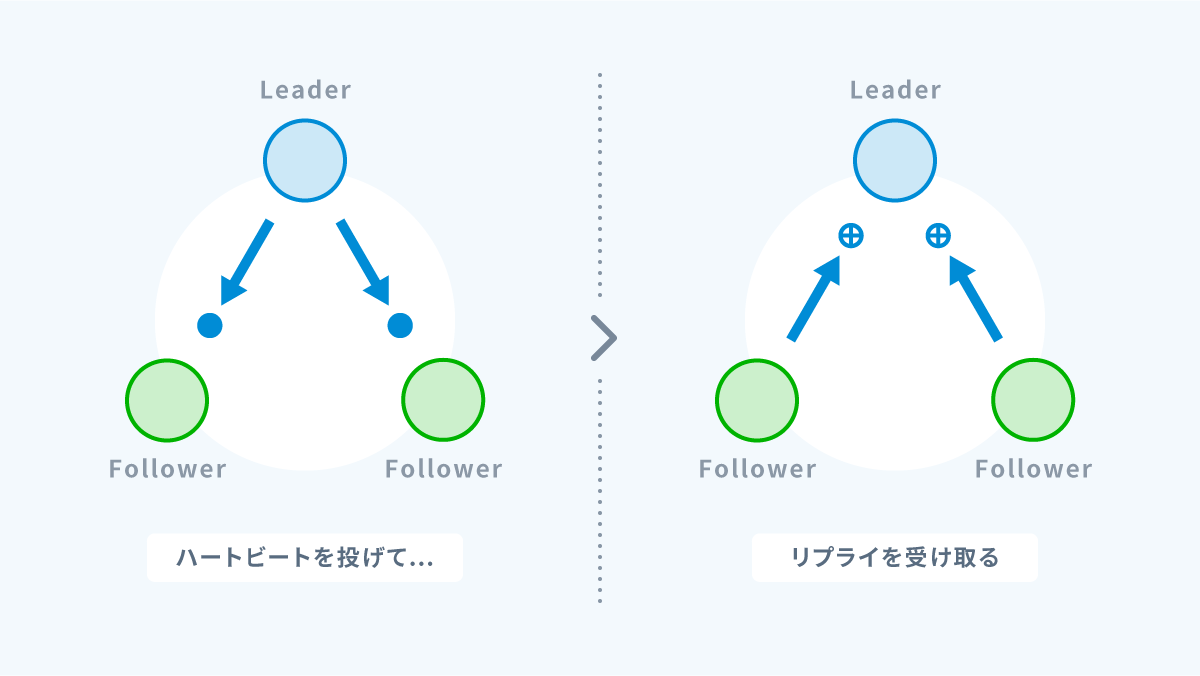
リーダーは他のノードに対して定期的にハートビートを送信することでリーダーとしての地位を維持します。
他のノードはそのハートビートを受け取ることでリーダーが健在なことを確認します。
まとめ
SKYDIV では障害発生を検出するために分散合意アルゴリズムの一つである「Raft」を採用しています。選定の理由としては以下の理由が挙げられます。
- 状態遷移が単純(3つの状態しかないので管理しやすいですよね)
- (特殊な状況を除いて)リーダーは 0 or 1 になる
- Microsoft Failover Cluster でも同じような多数決制を採用している
特に状態遷移の単純さが決め手でした。
これで障害発生時に運用系から待機系へ自動的に切り替えできるようになりました。
次回は冗長化を支えるもう一つの要素技術「レプリケーション」についてご紹介できればと思います。
