デグレとは? 発生する3つの原因や対処法、予防策を紹介

システム開発の現場では、「システムをより良いものにするために改修を行ったはずが、今まで正常に動いていた機能が動かなくなってしまった」といったトラブルが発生するケースがあります。こうしたトラブルを、IT業界では「デグレ(デグレード)」と呼びます。顧客に不便をかけるうえに、修正に多大な労力がかかるデグレは、システム開発に携わるエンジニアにとって警戒すべき事象であり、避けては通れない問題です。この記事では、そんな「デグレ」についての基本的な知識から発生状況のパターン、原因と対処法、予防策までを詳しくご紹介します。
デグレ(デグレード)とは何か
デグレ(デグレード)とは、システムの改修や機能追加、インフラ設定の変更などを行った結果、かえって品質が低下してしまうトラブルのことです。英語で「低下」や「劣化」を意味する「degrade」から派生したもので、日本のIT業界で業界用語として使われています。
システムに手を加えた際に、ほかの部分に意図しない悪影響が生まれることで、デグレは発生します。引き起こされる事象の具体例としては、「それまで正常に動作していた機能が動かなくなる」「不具合を修正したのに、システムの性能が悪化する」などが挙げられます。
なお、デグレは和製英語であり、英語圏では同様のトラブルを「リグレッション(regression)」と呼びます。
デグレの3つのケース
デグレが発生する経緯には、いくつかのパターンがあります。ここでは、代表的な3つのケースについて、考え得る具体的な発生状況や影響などをご紹介します。
プログラムの改修の際に誤った処理が埋め込まれたケース
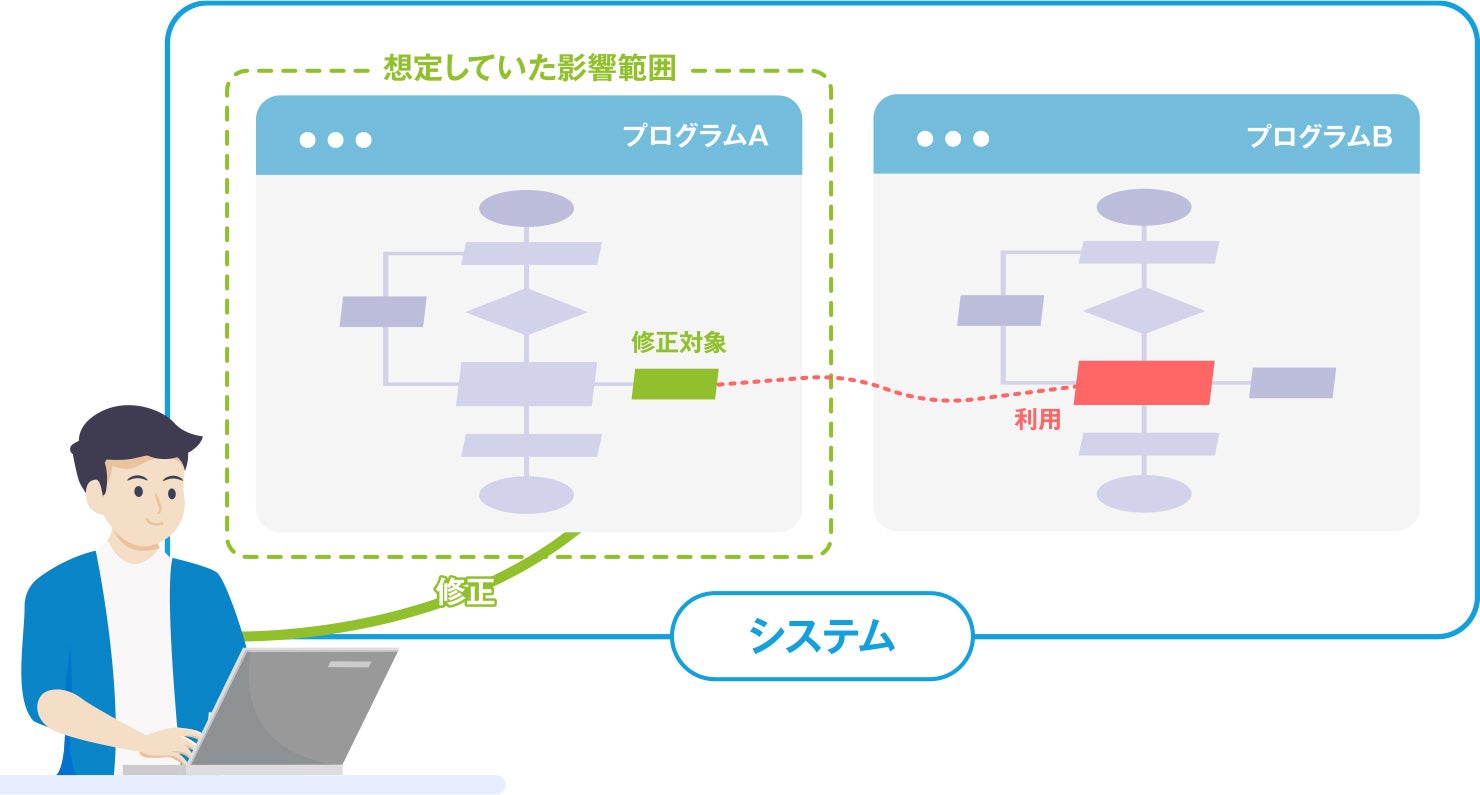
まず考えられるのは、システムを構成するプログラムの改修を行った際に、処理が誤っていたケースです。このケースにおける影響範囲は、コードの修正を行った箇所や、修正内容によって変化します。中でも特に注意が必要なのが、「修正対象の機能とは別の機能に想定外の影響を及ぼす場合」です。
たとえば、「A」というプログラムに修正が必要になったと仮定します。担当者が「A」の機能は「A」の中で完結しているものと認識していた場合、「A」の中での影響範囲だけを調査して修正を進めます。しかし実際には、別のプログラム「B」が動作する際にも「A」のコードが利用されており、「B」への影響を考慮せずに改修した結果、修正対象ではなかった「B」のほうが正しく動作しなくなってしまう、というケースがあります。
改修の対象となる部分にばかり気を取られていると、そのほかの機能の確認がおろそかになる恐れがあります。リリース後に問題が発覚する、といった事態を避けられるよう、システム全体への影響を確認しておくことが重要です。
インフラ環境を変更する際に影響を受けたケース
システムの性能向上やトラブル防止のため、システムを動かす基盤となるインフラ環境に対し、以下のような変更を加えなければならないことがあります。
- 設定値の変更
- インフラ環境を構成するソフトウェアなどのバージョンアップ
- 環境自体の移行
こうした変更を行った際に、併せて対応すべき作業が正しく行われていないと、デグレの発生につながります。特に、重大なトラブルへの対処のために変更を加えた場合など、緊急性の高い状況では対応が粗雑になりやすく、デグレの原因が生まれる危険があります。
具体的な事例としては、「一部の作業を後回しにして応急処置を行い、後から修正を行う予定だったが怠ったため、トラブルが再発する」「修正後の確認に時間を割けず、テストが不十分であったためにシステムダウンなどの大きな問題につながる」といったトラブルが挙げられます。
このケースは、基盤となるインフラにデグレの発生源があるため、影響範囲が大きくなりやすい点に注意が必要です。必要な作業がすべて行われているか、どこかで問題が発生していないかなど、慎重に確認をしなければなりません。
データ変更時の影響を受けたケース
システムに新機能を追加する場合、併せて必要なデータの追加が求められるケースがあります。システムを動作させる際に扱うデータ量が増えると、システムの構成やコード自体には問題がなくても、動作が重くなるという悪影響が出る可能性があります。こうしたトラブルもデグレの一種です。
システムがスムーズに動作するかどうかは、一時的なデータを保管する「メモリ」と、長期的にデータを保管しておく「ストレージ」の容量、各データにアクセスする速度などが影響します。データ量の増加による容量不足や、データ連携の複雑化が発生すると、システムの動作は重くなってしまいます。また、前述のような「インフラ環境の変更」を行った際にメモリの使用量が変わり、容量不足が発生するケースもあります。
これらはデータ量に起因する問題のため、テスト時に本番環境よりも少ないデータ量で実行してしまうと、デグレの原因が潜んでいることに気づけないままリリースまで進んでしまう恐れがあります。そのため、テストの段階からできる限り本番同様のデータ量を用意して動作確認をすることが大切です。
デグレが起きる3つの原因
ここまでにご紹介したようなデグレの発生パターンは、元をたどると情報伝達やコミュニケーションの不足、思い込みや勘違いによる人的ミスなどが要因になっていることが多いです。根本的な原因としてよくある例には、以下のようなものがあります。
実装者によるミス
代表的なデグレ原因の一つとして、実装担当者によるミスが挙げられます。たとえば、改修の影響範囲そのものを担当者が勘違いしていると、事前の影響調査をどんなに丁寧に行っても、どこかに確認漏れが発生してしまいます。また、作業自体の実施漏れがデグレにつながるケースもあります。
これらは実装担当者の思い込みや認識違い、確認不足によって引き起こされる人的ミスではあるものの、管理体制に問題があることでミスが誘発されるケースも多く、すべてが個人のミスとはいえない側面もあります。
人的ミスをゼロにすることは困難ですが、管理ルールが煩雑になっていないか確認し、情報の更新や共有、修正の反映が正しく行われるようにすることで、ある程度は発生頻度を減らせると考えられます。
仕様情報が最新化されていない
改修の影響範囲についての誤認は、個人の勘違いや思い込みのほか、そもそも正しい情報を確認できない状況になっていることで発生するケースもあります。
システムの改修は1回限りのものではなく、以前にも改修が行われていて、一部の仕様が変更されている場合があります。過去に改修された内容が資料に反映されていないと、誤った情報を基に影響範囲が判断されてしまい、デグレの要因となります。
どの情報まで反映しておくべきか、というラインのすり合わせができていないと、このような事象が起きやすいといえます。とはいえ、複数のベンダーが参加するプロジェクトなどでは、おのおのでこうした認識が異なることは少なくありません。可能な範囲での管理ルールの徹底や、そもそも仕様書を更新しなければ改修を進められないような仕組みづくりをすることで改善が期待できます。
コミュニケーション上のミス
最新の情報が共有された状態でプロジェクトを進めるためには、情報共有がしやすい体制づくりはもちろん、プロジェクト内の風通しを良くすることも大切です。大規模なプロジェクトであるほど、開発に関わる人数も増えるため、より注意深く連携ミスを防いでいかなければなりません。
特に複数のチームに分かれて業務に取り組んでいる場合には、チーム間でコミュニケーションを取り、きちんと情報共有することが非常に重要です。複数のチームが並行して作業を進めていく場面も多く、情報伝達にタイムラグが生じる場合もあることから、チーム間で連携しなければ、個々のメンバーが最新情報を把握しきることは困難です。
また、コミュニケーションが十分に取れていない状態で同じ箇所に複数人が手を加えることも、デグレの原因になりやすいといわれています。同時に修正作業を進めたためにコードが上書きされ、片方の担当者が行った修正が消えてしまったり、不整合が生じたりする例も少なくないため、細やかな確認が必要です。
デグレによる悪影響
原因がわかっていても、デグレをすべて防ぎきることは難しいものです。それでは、実際にデグレが発生してしまった場合、どのような影響があるのでしょうか。ここでは、特にリスクが高いといえる3つの悪影響について解説します。
顧客の信用を損なう
デグレが発生すると、「改修を行ったはずなのに、これまで利用できていた機能さえ満足に使えない」という状況が生まれます。特に不具合の修正が原因でデグレが発生した場合には、「立て続けにトラブルが起きた」という印象を与えかねません。
こうした状況は、顧客からの信用を大きく低下させる要因となります。信用を失えば顧客の見る目が厳しくなり、今後の改修に求められるハードルがさらに高くなってしまう恐れもあります。
余計な工数やコストがかかる
デグレの影響は信用の低下だけにとどまりません。デグレが見つかると、不具合の原因を改めて調査・修正しなければならない上に、修正対応に伴って新たなデグレが発生するような事態も避けなければならず、多大な労力を要します。
また、一度デグレが発生して信用に傷がついている状況で、中途半端な対応をすれば、顧客を納得させることは難しいといえます。デグレの再発を防ぐためや顧客の理解を得るためにも、緊急時の時間の余裕がないなかで、詳細な調査と報告資料の作成を行うことが求められます。
これらの対応は本来「デグレがなければ不要だった作業」であり、予定外の工数とコストを消費することになります。さらに、不具合によって顧客に与えた影響次第では、損害賠償にまで発展しかねません。
不要な工数や損害賠償が発生すれば、スケジュールの遅延や予算超過の発生、予定通りにシステムをリリースできずに契約違反とみなされるなど、さまざまなリスクを背負う結果にもなり得ます。
デグレが再発する恐れがある
デグレには、一度発生すると再び発生しやすいという難点があります。そもそもデグレが発生した箇所は、元々リスクが潜んでいた可能性が高いと考えられるため、同じような問題が再び起こるリスクも高いといえます。
またデグレは、システムに手を加えたことによって、ほかのプログラムに干渉した結果として発生するものがほとんどです。ほかのプログラムがデグレの影響を受けたことで、連鎖的に次々とデグレが発生する可能性にも注意が必要です。
こうした悪条件がそろった状況にもかかわらず、早急な修正対応が求められるケースが多いことも、注意すべき点の一つです。デグレの発生で顧客に迷惑を掛けたり、リリースまでの期限が差し迫っていたりすれば、修正にあまり期間をかけるわけにはいきません。
それでも、その場しのぎの対応は推奨できないのがデグレです。焦りがある時には、人的ミスも起きやすくなります。厳しい条件下であっても、普段以上に慎重かつ正確に情報を調査し、確実な修正対応を行うことが重要です。
デグレの防止策
すべてを防止するのは難しく、ひとたび発生すれば大きなリスクをもたらすデグレですが、以下のような防止策に取り組むことで、発生頻度を低下させる効果が期待できます。
適切な管理を実施する
デグレの発生を防ぐためには、最新の情報が正しく共有されるよう、適切な管理体制を整えることが重要です。プロジェクトの開始当初から管理ルールを定めておき、更新された情報がすべての開発関係者に伝達される環境になっていれば、デグレが発生しにくくなります。
定めておくべきルールの具体例としては、更新情報の伝達方法やタイミング、関係者向けの説明会の場を設ける基準などが挙げられます。また、更新の確認やレビューをあらかじめプロセス内に組み込んでおいたり、管理ルールを厳守するための監視や呼びかけを習慣化したりするのも有効です。
そのほか、管理体制を可能な範囲でシステム化しておくことも、ルールの運用を徹底できる環境づくりにつながります。
影響範囲をしっかり調査する
発生原因の中でも特に多いものの一つに、「改修による影響範囲の調査不足」があります。そのため、影響範囲の調査をいかに確実に行うかが、デグレの発生頻度減少に大きく関係します。
影響範囲の調査についても、あらかじめルールや方針を定めて、調査不足やミスを防止できる仕組みをつくるのが効果的です。方針の具体例としては、「調査を行った際に不確実な部分について、改修前後の比較を行う」「担当者と相談しながら影響範囲を確認する」などが挙げられます。そのほか、解析ツールの導入も人的ミスの防止に役立ちます。
また改修作業時には、わずかな処理方法の違いがデグレの原因となる可能性まで考慮しながら、作業を進めていくことが大切です。
デグレの対処法
しっかりと対策をしてもデグレが発生してしまう可能性に備え、対処法を把握しておくことも重要です。ここでは、デグレの発見に役立つテストの種類や、トラブル発生時の具体的な対応についてご紹介します。
1.リグレッションテストを活用する
リグレッションテストとは、システムに修正や機能追加を行った後に、デグレが潜んでいないか確認するためのテストです。日本語では「回帰テスト」や「退行テスト」と呼ばれることもあります。
このテストは、テスト済みの既存機能に対して行い、改修前と同じ動作が問題なく行えるかを確認します。すべての範囲を改めてテストすることは困難なため、改修時の影響範囲についての調査結果を基に、テスト範囲を決定するのが一般的です。
リグレッションテストを行う際は、以下のような点を意識して進めるのがポイントです。
影響範囲を十分に調査し、優先順位を考慮してテスト範囲を決定する
これまでにも述べた通り、デグレの発生防止や検出にはまず、影響範囲の調査を確実に行うことが重要です。また、不具合が発生した場合の影響範囲が大きい部分や、これまでの不具合発生率が高い範囲、処理方法に差分が存在する範囲などは、優先的にテスト範囲に含めたほうが良いとされています。
不具合が検出された場合の修正対応まで踏まえたスケジュールを組む
リグレッションテストで不具合が検出されれば、修正対応が必要になり、その分の工数がかかります。あらかじめ不具合の程度ごとの対応方針などを定めておき、重大な不具合が発覚しても修正できるスケジュールを組むことが大切です。
本番環境とできる限り近い環境やデータでテストを実施する
環境やデータの違いによってデグレが起きるケースもあるため、できる限り本番環境に近づけることで、問題の見落としを防ぎます。
2.自動テスト・CIを活用する
限られたスケジュールの中でリグレッションテストを行う際、作業に手間がかかり過ぎるとテストできる範囲が狭まってデグレを見落としやすくなります。そのため、ツールの導入によるテスト自動化を検討することが推奨されます。
リグレッションテストの自動化にあたっては、開発スピードの向上に役立つ「CI(Continuous Integration)」という手法を取り入れるのが有効です。CIを活用すれば、プログラムの書き換えからテスト、テストしたシステムの展開までの一連の業務を自動化できます。テストコードの作成やメンテナンスなどの手間はかかりますが、効率的にリグレッションテストを実行でき、検出しやすいデグレを早期に発見可能な手法です。
また、CIを取り入れて定期的に自動テストを行うと、以下のようなメリットが得られます。
- 影響範囲外と想定された部分のデグレを検出できる
- すべてのAPIについて挙動の変化をチェックできる
- 環境の変化や機能変更の影響で発生した、思わぬデグレを発見できる
しかし、こうしたメリットがある一方で、自動テストではあくまでテストとして実装した内容しか確認できない点に注意が必要です。加えて、自動テストは実装時にコストがかかるため、長期的な利用を検討できるタイミングで取り入れるほうが良いとされています。
プロジェクトの初期から実装しておいたり、柔軟な対応が可能な手動テストと組み合わせたりすることでデメリットを解消し、より効果的に活用することができます。
3.デグレの振り返りを実施する
デグレが一度発生したシステムには、再び同様の不具合が起きやすいという特徴があることから、デグレが起きたら振り返りを行い、原因を詳細に分析して再発防止につなげることが大切です。
影響範囲の調査や設計書の内容は正しかったのか、人的ミスである場合には避けられないものだったかなどを分析し、作業工程を見直します。この時、以下のようなポイントを押さえておくと、より良い改善策を見つけやすくなります。
- 個人のミスで終わらせず、ミスを引き起こした大本の要因まで分析する
- 大本の要因への対処になるような、プロジェクト全体の仕組みややり方の改善案を考える
- 具体的にどうやって改善するかまで検討した上で実行する
- 改善策による効果の測定を継続して行い、必要に応じて見直す
4.リリースをコントロールする
デグレの影響を最小限に抑える手段の一つとして、「品質をチェックしながらリリース(提供)を進め、問題が起きたら元の状態に戻す」というやり方があります。クラウド環境でリリースする場合に特に向いている方法で、デグレ対策になるだけでなく、品質の安定と向上を図る上でも役立ちます。
このようなリリースのコントロールに利用できる手法には、以下のような種類があります。
カナリアテスト
カナリアテストは、まずは限られた顧客のみに最新版のシステムを提供し、反応を見ながら徐々に提供範囲を広げていく手法です。「カナリアリリース」とも呼ばれます。新しいシステムと従来のシステムを同時に稼働させながら、サーバーの負荷を分散させる「ロードバランサー」という装置を使って、利用者の割合をコントロールします。
最新版を提供された顧客に本番環境で使用してもらい、問題が発覚した場合にはすべてのシステムを従来版に戻します。問題がなければ、最終的にはすべての顧客が最新版のシステムに移行します。
シャドーテスト
シャドーテストは、最新版のシステムが非公開の状態で、裏で挙動を確かめる方法です。新旧どちらのシステムも動かして、ロードバランサーでコントロールするところまでは、カナリアテストと似た流れです。シャドーテストの場合は、顧客ごとにバージョンを分けるのではなく、顧客の入力を新旧両方のシステムに送ります。
顧客には従来のシステムから出力が返されますが、その裏で新システムによる出力も行われ、どのような結果になるかを確認できます。それぞれの出力内容に相違点がある場合は、デグレが潜んでいる恐れがあるため、詳細な調査に移行します。確認のためだけに最新版のシステムを動かすことにはなるものの、実際の業務内容に準じたチェックが行えるのが利点です。
A / Bテスト
A / Bテストは、AとBの2つのパターンを実際に提供して、成果を踏まえてどちらを残すかを決定する手法です。この手法でも、新旧2つのシステムを同時稼働させるところまではカナリアテストと同じですが、徐々に提供範囲を変えるのではなく、顧客を半分に分けてそれぞれに各システムを提供します。その上でモニタリングを行い、成果を比較します。
デグレ防止よりも、システムの有効性をテストしたい場面で用いられることが多い手法といえます。より正確なデータを収集するため、比較対象以外の条件はなるべくそろえておくことが望ましいとされています。
まとめ
この記事では、デグレの意味や発生パターン、発生時のリスクや、原因と対策などをご紹介しました。ゼロにすることは難しいデグレですが、その原因には傾向があり、特に注意すべき点を把握して対策を練れば発生頻度を減らすことが可能です。きちんと対策をせずにデグレが頻発してしまうと、連鎖的に次々と不具合が起こり、多大な工数と費用を浪費する結果となってしまいます。大きな損害を引き起こす前に、プロジェクトの体制や現場のルールを見直すことをお勧めします。
Sky株式会社では、デグレ対策を含む評価 / 検証業務のサポートからテスト自動化ツール「SKYATT」の提供まで、ソフトウェアテストの進め方に関するさまざまな支援を行っています。お困りの際はぜひ一度お問い合わせください。

