機械学習パイプラインとは? メリットや種類、効率的な方法を紹介

AI(人工知能)の普及に伴って、AIと関わりの深い技術である「機械学習」の注目度も高まり、さまざまな分野に影響を与え始めています。機械学習を応用すれば、新たなビジネスチャンスを生み出すことや、業務の効率化を実現することが可能です。 そんな機械学習を行ううえで重要な役割を果たすのが、「パイプライン」と呼ばれる仕組みです。この記事では、機械学習パイプラインの概要やメリット、学び方などを詳しく解説していきます。
機械学習パイプラインとは何?
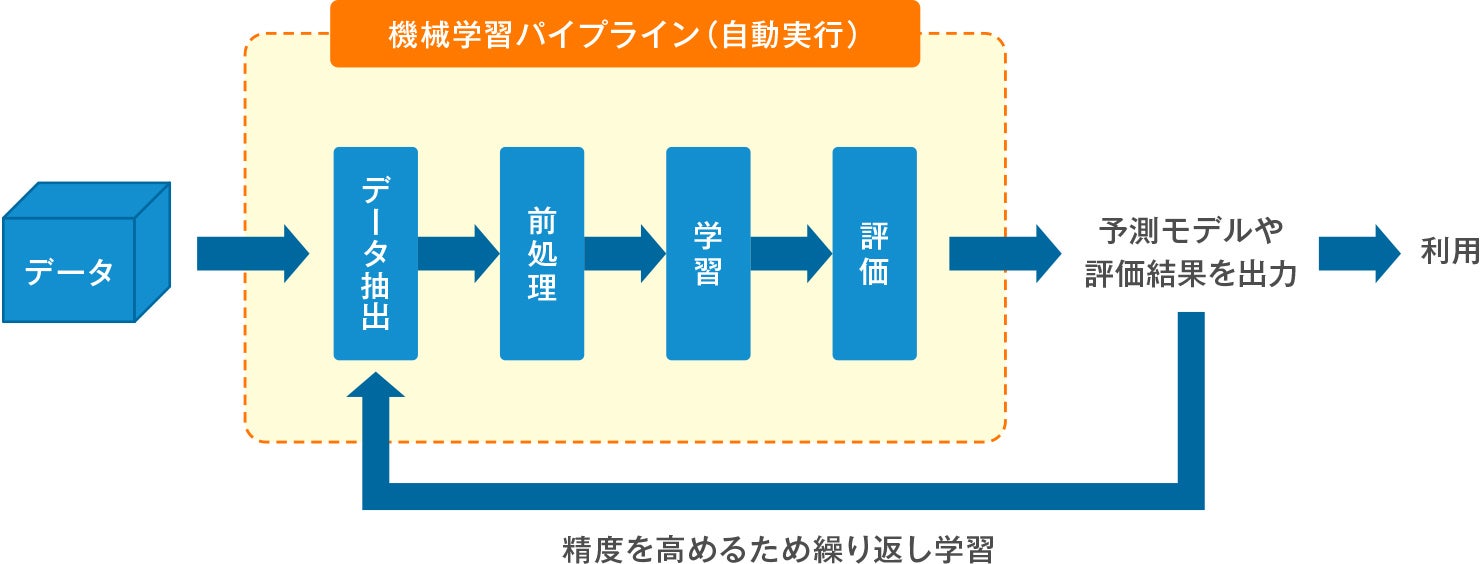
機械学習パイプラインとは、機械学習に必要な「予測モデル」を作成するためのデータ処理を、一連の流れでまとめて行えるようにした仕組みのことです。複数の処理プログラムを連結させてパイプライン化することで、ステップごとに手動で作業を行わなくても、自動的に複数の処理を続けて実行します。
予測モデルとは、コンピューターが物事を判断する際に必要不可欠な数式やルールのことで、作成するには大量のデータを分析しなければなりません。このデータ分析作業を進めるうえで、効率的で扱いやすい処理プログラムを構築するために、機械学習パイプラインは重要な役割を果たします。
そもそも機械学習とは?
機械学習とは、大量のデータをコンピューターに分析させることで、データに潜むパターンを発見して学習させる解析技術です。学習用のデータから見つけ出したルールを覚えることで、ルールに基づいた「予測」や「判断」をコンピューターが自動で行うことが可能になります。このルールが「予測モデル」と呼ばれるものです。
人の手で大量のデータから分析・予測を行う場合は膨大な時間がかかってしまいますが、コンピューターであれば迅速に処理が行えるという利点があります。また、データを機械的に処理するため、作業の精度も高いことが特長です。
混同されやすい言葉として「AI(人工知能)」がありますが、機械学習はAIを実現するために必要な技術的要素の一つといえます。
一般的な機械学習の流れ
機械学習は一般的に、以下のような手順で進められます。
- 学習用データの収集
- データの前処理
- 教師データの設計(教師あり学習の場合)
- 機械学習の開始
- テストデータをベースに精度を評価
- ハイパーパラメータ(モデルの設定)のチューニング
- 機械学習モデルの展開(デプロイ)
いわゆる「機械学習」と呼ばれる作業には、手順4が当てはまります。手順2では、機械が扱えるデータへの変換や加工、不要な重複データの削除を行います。こうした作業を「データクレンジング」と呼びます。また、データの特徴を数値で表したものを「特徴量」と呼び、学習内容と関連性の高い特徴量をピックアップする作業なども、前準備として行います。
機械学習の種類とは
機械学習には「教師あり学習」や「教師なし学習」、「半教師あり学習」、「強化学習」、「深層強化学習」といった複数の学習手法があります。ここでは、代表的な3種類の手法についてご紹介します。
教師あり学習
教師あり学習とは、入力内容と正解のデータ(教師データ)をセットで用意し、正解に沿った正しい出力ができるようにルールや特徴を学習させる手法です。
教師あり学習で扱われる問題は、「分類」と「回帰」の2タイプに分けられます。分類では「犬か猫か」「スパムメールか否か」など、ルールに沿ったクラス分けを行い、回帰では「売上や価格がどのように変化していくか」のような、連続する値の予測が行われます。
教師なし学習
教師なし学習の場合は、正解データは用意しません。無数の入力データからパターンや構造を見つけ出すことで、ルールを分析・学習していきます。データ間の類似度や近さの計算、データ同士のつながりについての推測、データのグループ分けなどが行えます。
似たもの同士をグループ化する手法は「クラスタリング」と呼ばれ、通販サイトのレコメンド機能などに利用されます。
強化学習
強化学習とは、「エージェント」と「環境」という2つの要素を持つシステムにおいて、エージェントが環境に合った行動を取れるようにするための学習方法です。教師あり・教師なし学習のように、最初からデータがあるわけではなく、試行を重ねてその結果から学習していきます。
強化学習におけるエージェントとは、意思決定や行動の主体となるものを指します。自ら最適解を考えてゲームをするAIや、より安定した歩き方を試行錯誤しながら学ぶロボットなどが例として挙げられます。近年では、生成AIの回答品質や安全性を高める調整にも、強化学習の考え方が活用されることがあります。
機械学習パイプラインの8つのメリット
機械学習パイプラインの仕組みを利用することで、機械学習のプロセスはどのように変化するのでしょうか。ここでは、パイプライン化によって得られる具体的なメリットを8つご紹介します。
1. 機械学習のプロセスをモジュール化できる
モジュール化とは、全体をいくつかの単位に分割し、流用しやすい形にしておくための手法を指します。
機械学習をパイプライン化すれば、学習のプロセスをモジュール化できるため、段階ごとに分割して個別に開発やテスト、最適化を行うことが可能です。これにより、業務フローの管理や保守がしやすくなります。
2. 再現性がある
機械学習パイプラインを使った学習は、パイプライン化する際に手順や設定を明確に定義することにより、再現性を持たせることができます。
プロセス全体をそのまま再現することも可能なほか、一貫した結果が得られるというメリットがあります。
3. タスクが自動化される
機械学習のパイプライン化を行うと、学習用データの前処理やモデル評価、機械が理解しやすいデータへの変換といったさまざまなタスクを自動化できます。
人の手で行うよりも、機械的に処理をしたほうが早く完了できる作業が多く、ヒューマンエラーによって手間取る心配もないため、大幅な作業時間の節約につながります。
4. 拡張性が高い
大規模なデータセットを利用する場合や、複雑な業務フローを採用する必要がある場合には、機械学習を行うためのプロセスを再構成しなければならないケースもあります。
機械学習パイプラインは拡張性が高く、必要なリソースの増加や業務フローの複雑化にも臨機応変に対応できるため、こうしたケースでもプロセスのすべてを構成し直す必要がありません。
5. 柔軟性がある
パイプライン化された機械学習のプロセスでは、一部のステップだけを柔軟に変更し、別の条件を試すことができます。データの前処理を行う技術や、予測精度に関わる「特徴量」の選択を変更したり、別の予測モデルを試したりといったプロセスの最適化も迅速に行えます。
6. デプロイがスムーズに行える
機械学習モデルのトレーニングや評価を行うにあたって、定義が明確化されたパイプラインを確立しておくと、アプリケーションやシステムへの統合が行いやすくなります。そのため機械学習パイプラインは、機械学習モデルの運用環境への展開がスムーズに行えるという特長があります。
7. データサイエンティストなどと連携しやすい
機械学習パイプラインでは業務フローが構造化され、文書化されているため、チーム内での情報共有がしやすく、データサイエンティストやエンジニアなどのチームメンバー全員が容易にプロセスを理解できます。これにより、スムーズに連携を取りながら各人がプロジェクトに貢献できる体制づくりを行えます。
8. バージョン管理がしやすい
パイプラインのコードや設定を変更し、後から元に戻す必要が出てきた場合、バージョン管理システムを使用していれば前のバージョンへのロールバックが容易に行えます。また前述の通り、各ステップの詳細についての文書化も可能なことから、バージョンごとの情報の把握や管理がしやすいのもメリットです。
これまでの機械学習パイプラインの歴史
現在のように形式化された機械学習パイプラインが登場したのは、つい最近のことです。機械学習パイプラインが形式化されていく過程には、機械学習とデータ処理、それぞれの歴史が深く関係しています。ここでは、現在に至るまでの関連技術の歴史についてまとめていきます。
機械学習の普及以前のデータ処理
データ処理の基礎技術は1960年代ごろから普及し始め、企業でもコンピューターを使ったデータ処理が行われるようになりました。一方、AIという概念は1950年代に誕生していましたが、機械学習が広く普及したのはずっと後のことです。
2000年代以前における機械学習は、データのクリーニングや変換、分析などの専門的なタスクに利用されており、プロセスの中心ではありませんでした。また、この頃は手動で作業が行われていました。
機械学習をさまざまな領域で採用
2000年代になるとインターネットが急速に普及し、扱われるデータの量が飛躍的に増加したことで、「ビッグデータ」という概念が生まれます。
大規模なデータセットを利用できる可能性が生まれたことや、コンピューターの計算能力、機械学習アルゴリズムなどの進化に伴い、この頃から機械学習が脚光を浴びるようになります。機械学習はさまざまな領域で活用されるようになり、データ分析の精度向上に貢献しました。
データサイエンスの普及
「データサイエンス」は、統計学やデータ分析、機械学習を組み合わせた分野を指す言葉です。語源自体は古くからあったものの、ビッグデータ分析や機械学習の応用が広まったことで、2000年代後半から2010年代前半にかけて重要視されるようになっていきました。
この頃になると、データの前処理やモデルの選択・評価といった、データサイエンスのワークフローが形式化します。これらは、機械学習パイプラインにおいても欠かせない要素です。
機械学習ライブラリの発展
2010年代になると、機械学習ライブラリやツールの開発が進み、パイプラインの構築が以前よりも容易になりました。PythonやR言語など、データサイエンスの分野で広く使われているプログラミング言語で使用できるライブラリやフレームワークも開発され始めます。
データを可視化するツールや、データ分析ツールの開発も進み、高機能で使いやすいさまざまなツールが登場しました。
AutoML(自動機械学習)ツールの登場
2010年代に登場したツールの一つに「AutoML(自動機械学習)」があります。このツールでは、機械学習モデルを設計・構築するプロセスを自動化することが可能です。
具体的には、データ収集から機械学習モデルの生成までを自動化できます。AutoMLの登場以前はこれら作業が人の手で行われており、高度な専門知識や技術がなければ対応できない工程だったため、人手不足が課題となっていました。しかし、ツールによって作業の自動化や視覚化、チュートリアルの利用などが行えるようになり、専門家以外でも機械学習を利用しやすくなりました。
MLOps(機械学習オペレーション)の登場
ツールの登場以外で機械学習パイプラインの円滑化に影響を与えたのが、MLOps(機械学習オペレーション)の登場です。MLOpsとは、機械学習チームや開発チーム、運用チームの工程をパイプライン化することで、業務の円滑化や生産性の向上を目指す考え方のことです。
スピーディーな開発を行うためのソフトウェア開発手法の一種である「DevOps」から派生したもので、DevOpsが通常のソフトウェア開発に焦点を当てているのに対し、MLOpsは機械学習システムに特化した手法となっています。
機械学習やパイプライン処理を学ぶ方法
便利なツールが登場しているとはいえ、「まずは機械学習やパイプライン処理についての基礎知識を身につけたい」と考えている方も少なくないと思います。主な勉強方法としては、以下のような例があります。
専門書を読み自主学習する
機械学習パイプラインや関連技術については、入門書から難易度の高いものまで、さまざまな専門書が販売されています。自主学習を行い、全般的に知識を身につけたい場合は、まずは専門書を読むのがお勧めです。
専門書は基礎知識から順序立てて説明されており、幅広く情報を網羅できるようになっていることが多いため、基礎を学ぶのに向いています。また1冊持っておけば、辞書のようにわからない箇所をその都度調べられます。繰り返し使用できて、基礎知識を定着させやすい勉強方法です。
プログラミングスクールで学ぶ
機械学習に関する知識は、プログラミングスクールでも学ぶことができます。専門的な知識や技術を確実に習得したい場合に向いている方法です。費用はある程度かかりますが、専門家から直接指導を受けられます。
プログラミングスクールに種類が豊富にあり、それぞれ特徴が異なります。自分が学びたい内容をきちんと学べるのか、働きながらでも通えるのか、転職や就職の実績など、自分の目的や生活スタイルに合わせて条件を確認しながら選ぶことが大切です。近年ではオンラインで授業を受けられるスクールも増えており、自身の都合に合わせた受講が可能です。
ITツールを利用して実践的に学ぶ
機械学習に関する知識や技術をしっかり定着させるためには、実践を積むことも大切です。
現在はさまざまなITツールが提供されており、機械学習に対応しているツールも利用できます。こうしたツールでは、AIの構築に必要なアルゴリズムが用意されていて、手軽に機械学習を体験できる場合がほとんどです。そのため、自らの手でゼロから機械学習モデルを構築するほどの技術がなくても、実践的な練習が行えます。
また、クラウド型のツールを選べばサーバーを用意する必要がなく、導入にかかる手間も削減できます。
機械学習パイプラインに関するQ&A
AutoMLツールにデメリットはある?
ツールを利用して機械学習パイプラインの構築を自動化する場合、構築内容がブラックボックス化してしまう点に注意が必要です。そのため、構築方法そのものについて学びたい場合などには向いていません。
また、問題が発生した際に、その原因を突き止めて解決することが困難になる可能性もあります。AutoMLでできること・できないことを事前に理解し、機械学習パイプラインを構築する目的に適しているかを確認しておくことが重要です。
機械学習パイプラインの活用事例は?
機械学習パイプラインは、AIを用いて業務の効率化を図る場合などに活用されています。
大手物流企業の事例では、業務量の予測を行うための機械学習モデルを毎月作成しており、以前はデータの抽出からモデルの評価までのプロセスを手動で実行していました。作業負担が大きいことから、これらの一連の業務を自動で実行する機械学習パイプラインを構築し、余裕のあるスケジュールで運用することを可能にしました。
Sky株式会社のシステム開発
Sky株式会社では、システム開発に関わる幅広い業務について、エンジニアの派遣や受託開発を行っています。要件定義から設計、開発、検証、運用保守まで、あらゆるステップにおいて技術の提供が可能です。
データ分析の分野では、クラウド上やエッジデバイスからのデータ収集に加え、現場の声にも耳を傾け、固有の情報や知識、ノウハウも分析内容に反映しています。また、AutoMLを活用した効率的なデータ分析を行うなど、実効性の高いシステム開発が可能です。
データ分析の手法や現場の知識の活用方法、検知・予測モデルの選定方法など、データの分析や活用についてお悩みの際は、ぜひ一度ご相談ください。
まとめ
機械学習パイプラインには多くのメリットがあり、機械学習のプロセスを効率化するために欠かせない仕組みとされています。データサイエンスの普及と共に形式化されていき、現在では構築を自動化できる便利なツールなども登場するほどになりました。
今回ご紹介した内容が、「機械学習パイプラインについて詳しく学びたい」「実際に業務へ導入したい」と考えている方の参考になれば幸いです。

