

AI分野では、画像や言語などさまざまなものが扱われています。そのうちの一つに音声があります。
しかし、音声データをそのまま解析するのは難しいです。理由は以下の通りです。
- 時間軸のみの情報であり、周波数成分を視覚的に捉えづらい。
- 高次元であることから、計算量が膨大になり、効果的な学習が難しい。
- 生の音声データは人間の聴覚特性を直接反映していないため、音の違いを捉えづらい。
このような理由から、音声データを直接扱うのは難易度が高いとされています。
ここで登場するのがメルスペクトログラムです!
メルスペクトログラムとは
メルスペクトログラムとは、音声信号を時間と周波数の2次元の画像として表現したものです。
これにより、先ほどの音声データそのものの解析におけるデメリットが解消されます。
- 時間軸だけでなく周波数軸の2次元の画像として表現されるため、視覚的に捉えやすく、画像処理技術を適用しやすい。
- 周波数成分の数を大幅に削減し、計算量を減らすことができる。
例えば、本来の音声データなら0Hzから8kHzまでの周波数成分が得られるのに対して、メルスペクトログラムでは、128次元の周波数成分に圧縮される。 - 周波数軸を人間の聴覚に合わせて変換する方法を使用して、人間の解釈に合うようなデータになっている。
つまり、メルスペクトログラムを用いることで、解釈しやすいデータとなり、扱いやすくなります。
具体例
私は趣味でアカペラをしており、ボイスパーカッションができます(以降、ボイパと呼びます)。ボイパでよく出てくる6種類の音声を録音し、メルスペクトログラムを用いて画像に変換しました。
その結果が以下の通りです。
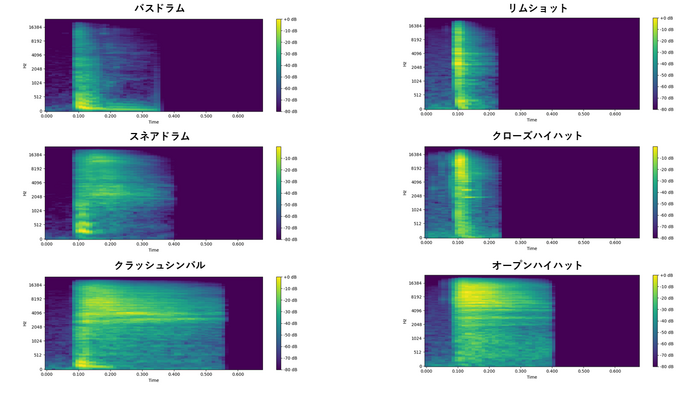
確かに、バスドラムは低音が強く、リムショットは低音と高音の間が強く、クローズハイハットは高音が強いなど、音声が視覚的に捉えやすくなっていることがわかります。
これを非常に簡易的な画像認識モデルに入力し(モデルは二層の畳み込み層、二層の結合層のみ)、先ほどの6種類の音声データを計2140個用意し、正しい音の種類に分類できるモデルの学習を行いました。
その結果、100%の精度で音声データを分類することができました。
この結果から、音声を画像化することで、解析しやすくなっていることが確認できます。
まとめ
今回は、音声データそのもので解析するのではなく、メルスペクトログラムを用いて画像に変換することで、より推論しやすいものに変換した実例を紹介しました。
