

はじめに
本記事ではGoogle社が開発・販売しているAIアクセラレータであるGoogle Coralを使った 開発方法を紹介いたします。
AIアクセラレータとは
AIアクセラレータは、ニューラルネットワークのモデル推論処理を 高速化するための専用ハードウェアです。 これには、USBスティックタイプ、単体のチップタイプ、M.2の拡張ボードタイプなどがあり、 さまざまな形態があります。最近では、推論専用のチップも多く登場しています。
AIアクセラレータを用いたエッジAIの利点は、モデルの推論環境を安価に、 クラウドではなくエッジデバイス側で実行できるようにするところです。 またリアルタイム性が重視される物体検知、自動運転などの領域では AIアクセラレータがよく導入されています。
Google Coral
Google Coralは、Google社が開発・販売するAIアクセラレータのブランドです。 Google CoralにはEdge TPU(Tensor Processing Unit)が搭載されており、 AIの推論をエッジデバイス上で高速、低電力で実行することができます。
Edge TPUは以下の特徴があります。
-
高速
1秒間に4兆回の演算(TOPS: Tera Operations Per Second)を行う能力を持ち、 1TOPSあたり0.5ワットの電力を消費します。 これにより、エッジデバイス上でのリアルタイムな機械学習推論が可能となります。 -
低消費電力
エネルギー効率が高く、エッジデバイスでの使用に最適です。 例えば、2TOPSの処理を行う際には1ワットの電力しか消費しません。 -
多様なデバイス対応
USBアクセラレータやPCIeカード、M.2カードなど様々な形態で提供されています。
- TensorFlow Lite対応
Google CoralではTensorFlow Liteのモデルを実行できます。 自作したAIモデルを動かしたい場合は、TensorFlow Liteに変換する必要があります。 TensorFlow LiteはPython, C++で実行することができます。
公式公開モデル、サンプル
公式からいくつかのAIモデルやタスクのソースが公開されています。
- 画像処理
イメージ分類、オブジェクト検出、顔検出 - 音声処理
音声認識、音声合成、音声コマンド認識 - 自然言語処理
テキスト解析、文章生成、機械翻訳
モデル要件
AIモデルをGoogle Coralで実行するにはいくつかの要件があり、 その要件に従ってモデルの最適化が必要になります。
モデル要件は以下になります。
- テンソル、パラメータは8ビットの固定小数点(int8, uint8)
⇒量子化は必須 - テンソル、モデルは静的サイズ
- テンソルは最大3次元
カラー画像入力のバッチ推論×(H, W, C)
グレースケール画像のバッチ推論〇(B, H, W) - Edge TPUのサポート命令、その他命令はCPU処理
▼サポート命令一覧
TensorFlow models on the Edge TPU | Coral
Edge TPUモデル変換フロー
モデルの変換フローの図を以下に示します。
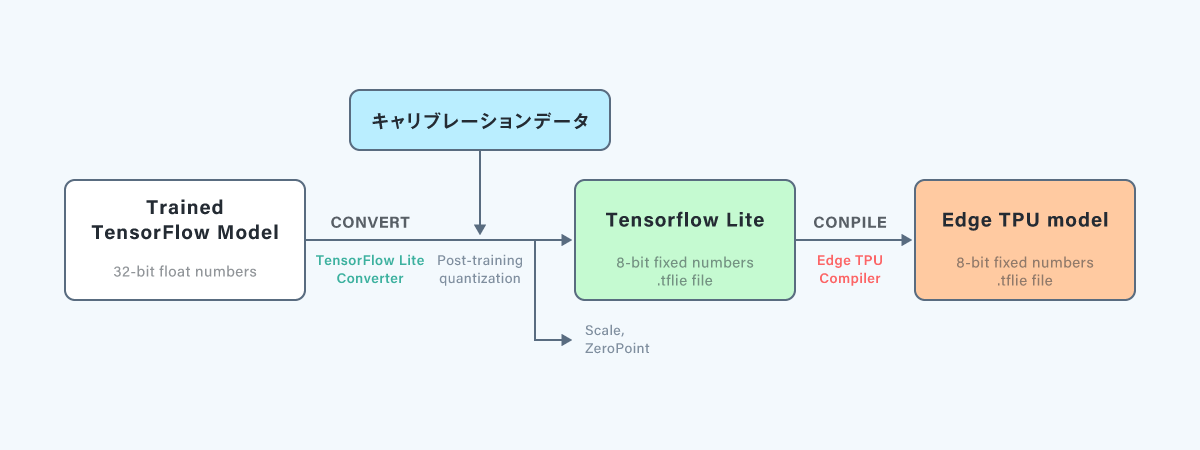
変換フローは大きく分けて3段階です。
①実行するモデルの学習
TensorFlow Liteモデルに途中で変換するため、
大きくサポートがあるTensorFlowのモデルを学習することが望ましいです。
オープンソースが潤沢なPyTorchでも変換可能ですが、ONNXなどの中間形式を経由する必要があり、
変換エラーが発生しやすいので難易度が高いです。
②量子化 + TensorFlow Liteモデル変換
量子化はモデルのパラメータ(重みやバイアス)、アクティベーションの数値表現を
低精度に変換するモデル圧縮手法の1つです。
完全整数量子化ではモデルのすべての数値表現を32bitから8bitに減らすため
モデルの速度が4倍、サイズが1/4になります。
量子化は2種類あり、PTQ(訓練後量子化)とQAT(量子化認識トレーニング)をすることができます。
一般的に量子化は、精度劣化が発生するため量子化後のモデルを訓練するQATは
PTQより精度が高くなる手法になります。
しかし、TensorFlowのQATのAPIの制約が厳しく、クラス分類モデル以外で
ほとんど実施することができません。
▼TensorFlow QAT制約
量子化認識トレーニング | TensorFlow Model Optimization
そのため、主な量子化の手順としてはPTQを行う変換フローが主流になります。
TensorFlowではTensorFlow Lite形式への変換と同時にPTQを行うことが行うことができます。
PTQ時には量子化のパラメータであるscale、zeropointを決めるために、
実際に推論で使う画像データをキャリブレーションデータとして用います。
③Edge TPUモデル変換
モデルを実際にGoogle Coralで使える形式にするため
Edge TPUコンパイラーを用いて量子化後のモデルをEdge TPUモデルに変換します。
▼EdgeTPUコンパイラー
Edge TPU Compiler | Coral
Edge TPUコンパイラーはGoogle Coralでサポートされる命令を変換することができます。
ここで事前にコンパイラーでモデルのすべてがEdge TPUにマッピングされるように
モデル最適化を行うことで、推論の速度を上げることができます。
Edge TPUモデル推論フロー
モデルの推論フローの図を以下に示します。
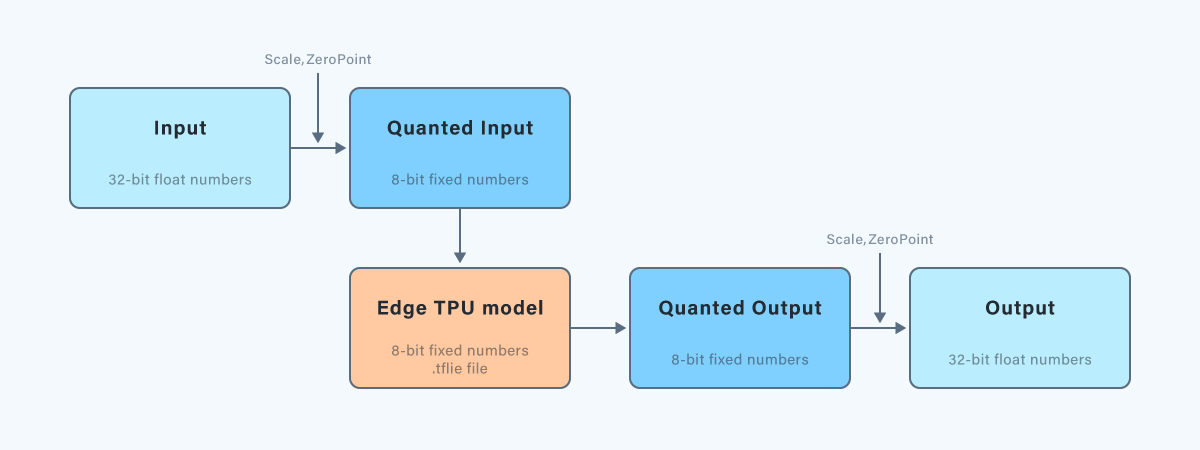
Edge TPUモデルは量子化されているため、モデルの入出力の形式が8bit整数型になっています。
通常入力の数値表現は32bit浮動小数点になっているので8bit整数型に変換する必要があります。
変換時には量子化時にキャリブレーションデータから算出したscale, zeropointを用います。
※入力と、出力のscale, zeropointは別の値が算出されます。
float型のデータをuint8型に変換する場合は scale, zeropointを用いて以下の変換式を入力データに行います。

モデルの出力はuint8になるので、それをfloat型に復元する際は この変換の逆関数として実行します。
量子化精度劣化に対する活性化関数の選定
量子化ではモデルの数値表現の精度を下げることから、 サイズ、速度を改善することができても、精度低下が発生することが課題になっています。 モデルで使われている活性化関数の種類によっては精度劣化の程度が異なります。 そのためモデル最適化では活性化関数に注目する必要があります。
近年のモデルでは活性化関数が改善され、SiLU(Swish)のような複雑な活性化関数などが 主流になっています。 SiLUなどの活性化関数を用いることで、事前訓練後のモデルの精度を向上することができますが、 量子化後にはシンプルな活性化関数より大きく精度劣化を起こす可能性があります。
例えば量子化における活性化関数選定では複雑なSiLUよりも単純で、整数表現しやすい ReLUを用いた方が精度劣化を抑えることできます。
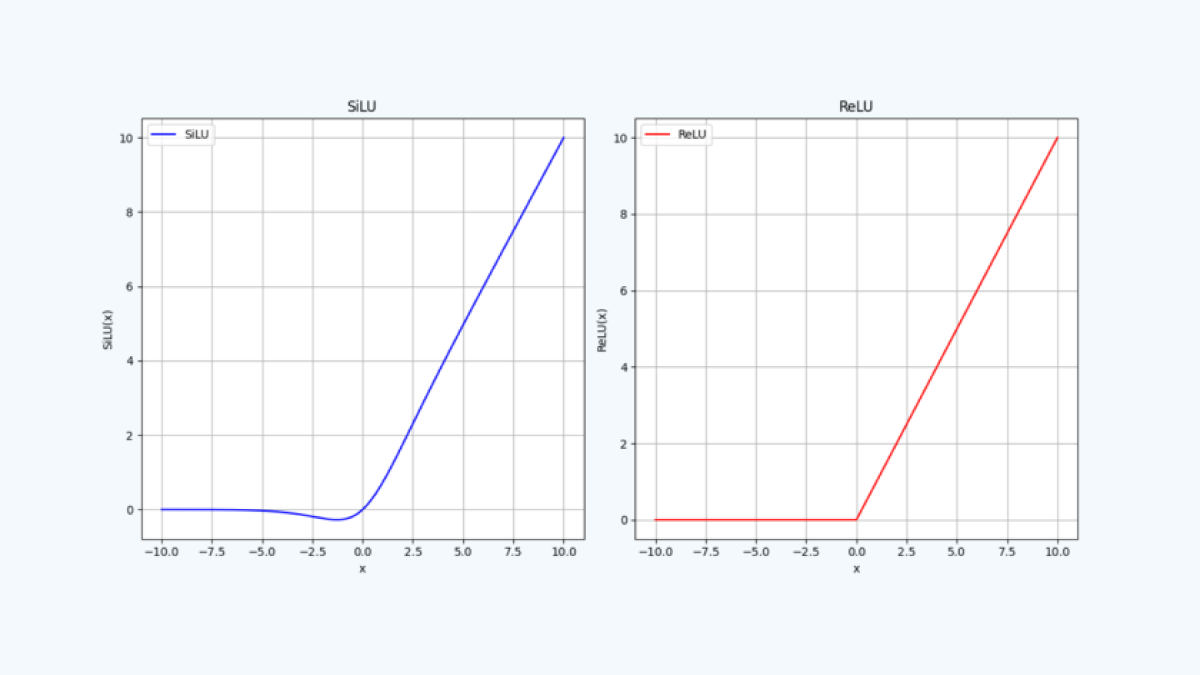
Google CoralにおいてSiLUをReLUに変えて訓練することで、2点の観点でメリットがあります。
- 量子化後のモデルが精度劣化を抑えることができ精度改善ができる。
- ReLUがEdge TPU上のサポート命令であるのでEdge TPUにアクセラレーションされ、 SiLUより高速な推論を行うことができる。 (サポート命令である活性化関数はReLU, ReLU8)
しかし、1つ目に関しては、SiLUモデルの方が事前訓練後のモデルの精度が高いため、 精度劣化程度が小さい場合は依然SiLUモデルの方が精度が良いこともあります。 そのため精度、速度、サイズの観点から複数のモデルパターンを検証し、 使用する環境の要件から選定する必要があります。
