

MLOpsをオンプレ環境で構築するポイントについてご紹介します。
MLOpsがどういうものなのかについては、以下の記事をご覧ください。
オンプレ環境でのMLOps構築は難しい!?
MLOpsの構築は、一般的にクラウドとの相性が良いと考えられます。
MLOpsには主に以下の要素が求められます。
- 学習コードとデータが紐づいた形での、モデルのバージョン管理
- 再現性が可能な学習コードと学習環境の管理
- スケーラブルなGPUリソース管理
- 学習に必要となる前処理/学習/推論を行う一連の流れのパイプライン化
- モデルの精度評価の管理と、運用モデルの管理も含めたエンドポイントへのモデルデプロイの仕組み
これらはMLOpsを構築することによって実現できるメリットであると同時に、その実現のためには、スケーラブルな運用に耐えうる大量のGPU/CPU/メモリ/ストレージリソースが必要となることが多々見られます。
クラウドでは、マシンリソースの確保が柔軟に行えることが、MLOps構築の利点につながります。
その一方で、扱うデータの特性によってはクラウドが使用できないという場合もありますし、すでに導入済みのオンプレ上のGPUリソースを有効活用するために、オンプレでのMLOps構築が必要になることもあるのです。
オンプレ環境でのMLOps構築を難しくする要因
オンプレでのMLOps構築の大変さは、システムを安定して動作させるための環境構築にあると考えられます。
MLOps環境でGPUリソースを使用する場合、多くの場合は複数のGPUノードを使ってクラスタを構築することになります。
GPUマシンを使ったクラスタの構築・運用は、インフラエンジニアが担う領域であることが多く、Kubernetesによるクラスタ運用や、ネットワークの知見も必要となってくることから、多くのデータサイエンティスト、AIエンジニアにとっては専門外の領域で、敷居が高いというのが実情です。
オンプレ環境で構築したMLOps環境で、実際に良く発生するトラブル事例です。
- 気づいたときには、ストレージの空き容量がなくなってしまっている
- 特定の学習ジョブがCPUを占有してしまう
- 空いているGPUリソースの割り当てがうまくできない
- 学習ジョブの実行が、想定以上に時間がかかりすぎてしまい、溜まっているジョブが実行されない
クラウドであれば、インスタンスサイズを変更して対処できることでも、オンプレ環境だと簡単にはいきません。
実行する学習/推論ジョブに対して、必要な学習マシンリソースが確保できているのかを監視できる仕組みも必要になります。
オンプレ環境でのKubeflowベースでのMLOps導入例
オンプレ環境でMLOpsを実現する際は、用途に応じて適切なマシンスペックを選定することが重要になります。
しかし、私たちのAI開発チームでもそうだったのですが、AI開発プロダクトは必ずしも最初からGPUマシンを数多く必要としているとは限りません。
そこで、後からGPUマシンを追加しやすい形で環境を構築することを検討したいです。
そのような場合に、Kubernetesによるクラスタ構築は都合が良いです。
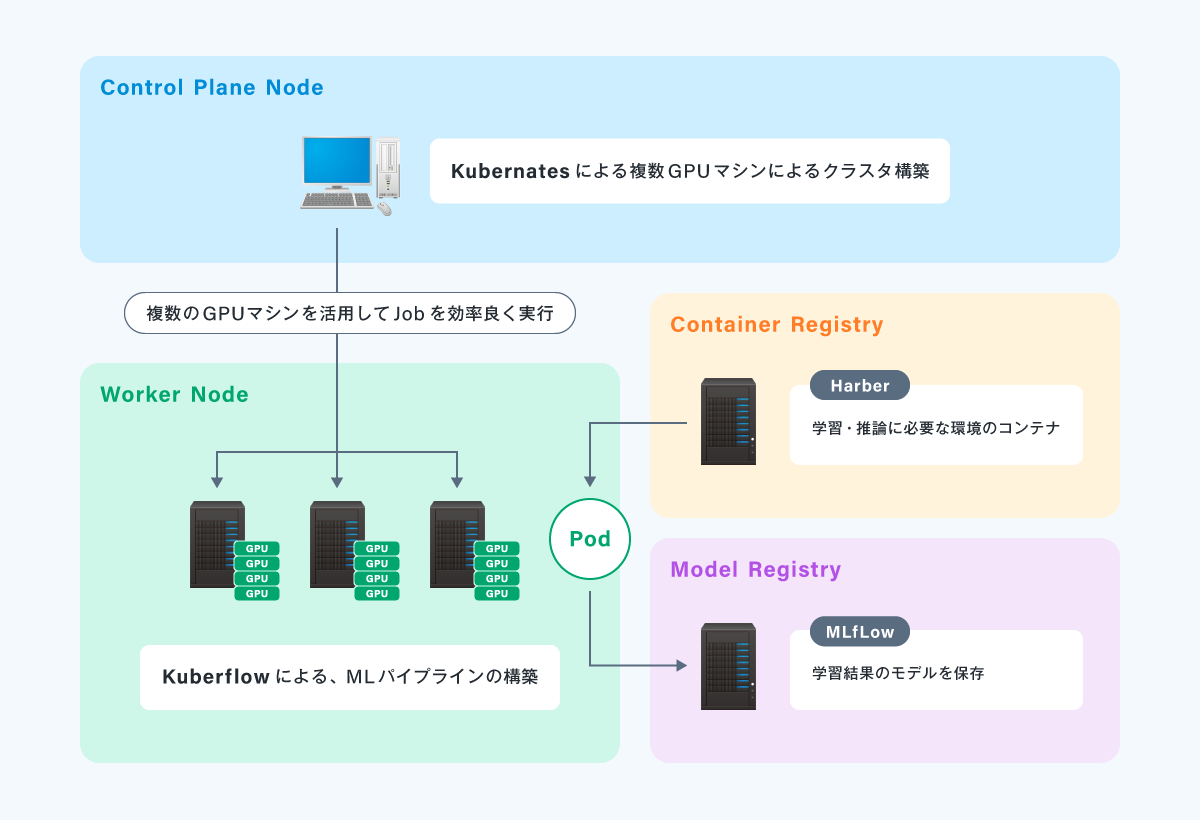
Kubernetes クラスタを構成して、Kubeflowを使ってMLOps環境を構築した例です。
Kubeflowは、Kubernetes クラスタ上で、MLパイプラインを管理できる機械学習プラットフォームです。
Kubeflowでパイプラインを構築する際は、前処理/学習/検証などの処理をComponentというコードセットをまとめたものを作成し、複数のComponentを接続したパイプラインを作成することで、一連のワークフローを構築します。Component はKubernetes上で個別のPodとしてデプロイされます。
学習を実行するのは、Workerノードとして登録しているGPUマシンになりますが、Workerノードは後から追加していくことも可能です。
GPUリソースが不足してくれば、Workerノードを拡張すれば使い勝手はほぼ変えずに同じ環境で学習リソースを増やすことが出来るのです。
Kubeflow環境の便利なところ/不便なところ
Kubernetes 上で動作するKubeflowですが、メリット/デメリットがそれぞれ存在します。
実際に使ってみて感じていることです。
〇 オンプレ環境Kubeflowの便利なところ
- 一度動作するパイプラインを構築できれば、データの差し替えでの再実行が簡単で、結果もダッシュボードからすぐに確認できる。
- エラーが発生したComponentのログも、ダッシュボードからトレースすることできる。
- Componentが実行されるPodの割り当ては、Kubernetes により自動割り振りされるので、複数台のGPUマシンを効率よく運用できる。
× オンプレ環境Kubeflowの不便なところ
- 学習コードのComponent化作業のコストが高いため、サクッと検証するという用途に向かない。
- Kubeflow標準の機能として、データセット/ソースコード/モデルのバージョンを紐づける仕組みがない。
- ベースになるKubernetes 環境を、オンプレで構築/運用することが大変。
- クラウドなら、Amazon EKSやAKSといったマネージドサービスでKubernetes を簡単にデプロイすることが可能だが、オンプレだと環境構築から運用保守をしなければならない。
- 豊富な計算リソース(GPU/CPU)やストレージがないと、十分にメリットを享受しきれない。
Kubeflowを使うのに向いているタスク
実際にKubeflow環境を構築して、適用しやすいプロダクトと適用しづらいプロダクトがあることがわかりました。
◆ 適用しやすいプロダクト
- 長期間にわたって、追加されるデータを使用して継続してモデル構築する必要がある
- 同一データに対して、複数モデルを同時に学習/評価したい、かつ複数の種類のモデルが、同一リポジトリの環境で学習できるようになっている。
- 一定期間に渡って、短いスパンでモデル改善を繰り返したい。
◆ 少し適用しにくいプロダクト
- 短期間のPoCで成果を上げる必要がある
- 最新のモデルを複数検証したい
- 実装方法が独立したリポジトリコードベースだと、Component化も別々に行うことになるため、よりコストがかかる。
まとめ
小規模な単独のPoCレベルだと、Kubernetes + Kubeflow によるMLOps構築は取り入れにくいかもしれません。
しかし、中長期にわたるAI開発を続けていくには、Kubernetes + Kubeflowを取り入れることにより、開発効率を向上するのにとても役立つMLOpsが実現できます。
オンプレ環境でのMLOps構築にご興味がある方、ぜひ弊社にお問い合わせください!
最後に
私たちのTech Blogを最後までお読みいただき、ありがとうございます。
私たちのチームでは、AI技術を駆使してお客様のニーズに応えるため、常に新しい挑戦を続けています。
最近では、受託開発プロジェクトにおいて、MLOps構築のニーズが高くなってきていますが、弊社ではAI開発経験者の目線で使いやすい環境を構築するように努めています。
また、このようなシステム開発にチャレンジしたいという技術者も募集しております。
AI開発経験のある方やMLOps、LLM開発に興味のある方は、ぜひご応募ください。
あなたのスキルと情熱をお待ちしています。
