

1990年代後半よりマルチコア(密結合アーキテクチャ)のシステムが増えてきて、それに伴い、複数のコアを有効に活用する方法として、いろいろな並列処理の技術が生まれています。
しかし、表題のOpenMPの誕生(v1.0リリース1997年)からかなり経過しているのですが、実は組み込み開発業務で積極的に使ったコードをあまり見たことがありません。
組み込みの世界では、ターゲットCPUがマルチコア化し始めて20年くらいでしょうか…
(いろいろなシステムがありますが大規模な開発だと割と多いです)
しかし、まだまだマルチコアシステムを有効活用した並列処理の技術は、普及していないのかもしれませんね。
それでは、OpenMPと言われる”pragma omp”の構文に関して、あくまでさわりの説明だけとなりますが、並列処理の実行イメージも含めて説明してみたいと思います。
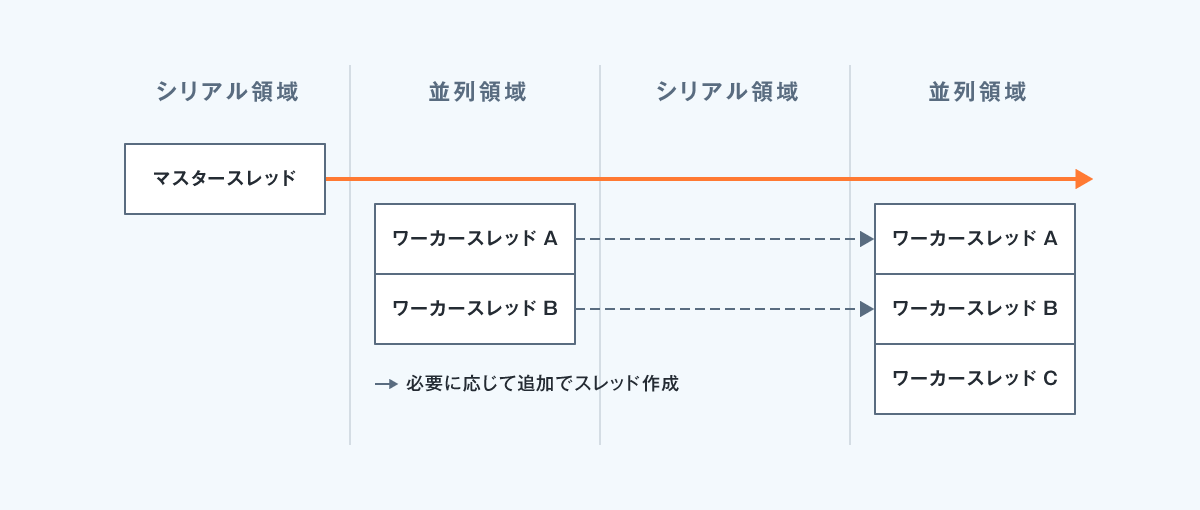
⓪OpenMPの実行モデル
- OpenMPプログラムはシングルスレッド(=マスタースレッド)で処理を開始する。
- ワーカスレッドは並列領域で生成されマスター共にスレッドのチームを作成する。
- 並列領域と並列領域の間ではワーカスレッドはスリープ状態になる。
OpenMPランタイムが全てのスレッドの動作を管理する(スレッドの終了や同期なども管理する)。 - コンセプトは「フォーク(プロセス複製)&ジョイン(参加)」とする。
インクリメンタルな並列処理を許可している。- 途中から並列処理を増やしたり減らしたりなどの操作が可能です。
- 処理が完了したワーカスレッドは必要に応じて再利用され、スレッド生成は最小限に最適化されます。
以下の図が、OpenMPの実行モデルです。
高度な使い方になると、記載の任意のワーカスレッドの同期など複雑な制御も行えるようになります。
① OpenMP 並列領域:for ワークシェアの例
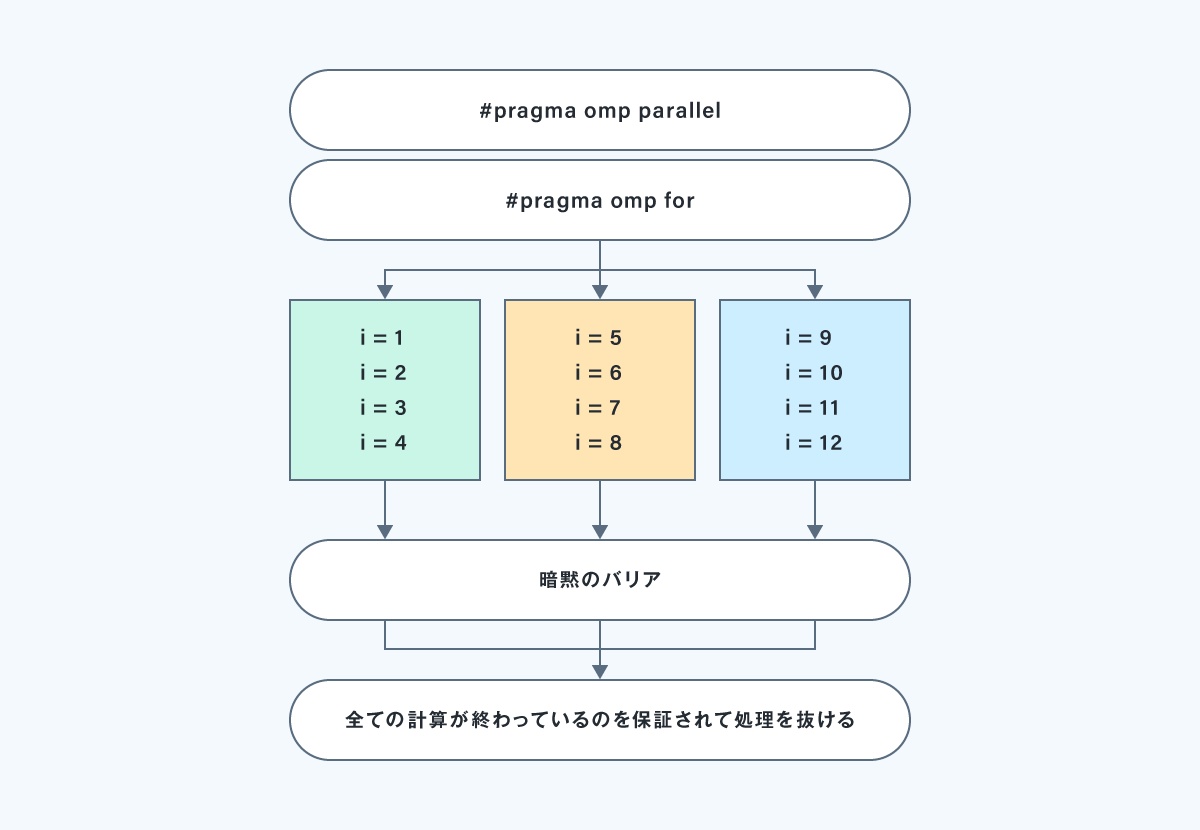
以下のコードが、forワークシェアの例です。
#pragma omp parallel
#pragma omp for
for (int i = 1; i < 定数; i++)
c[i] = a[i] + b[i];
- スレッドには独立したループ処理が割り当てられる
- 各ワーカスレッドはforワークシェア構文の最後で待機する(全てのワーカスレッドの処理が終了すると待機解除)
通常のOSのAPIを使ってスレッド生成して、別々に計算処理を実装して、終了同期をとって…
みたいなマルチスレッド(並列)処理を書くよりは、かなりシンプルなコードで並列処理が実現できていますね。
しかも、ompディレクティブにコンパイラが対応していない場合は、 #pragma行は単にコメント行として無視されるだけなので、 記載のコード例はシングルスレッドで実行されるだけになります。
ターゲットCPUに依存して移植性を損なうことなくコードを組めます。
ちなみに、実行イメージ図のループカウントのN数=12だと、並列処理のありがたみがあまりないのでご注意ください。
ターゲットCPUの性能次第になりますが、効果を実感できるのは少なくとも万単位のループになると思います。
→for文の中の処理が秒単位で実行されるケースなどはその限りではありません(効果あり!です)。
以下が、forワークシェアの実行イメージです。
② OpenMP 並列領域:sections ワークシェアの例
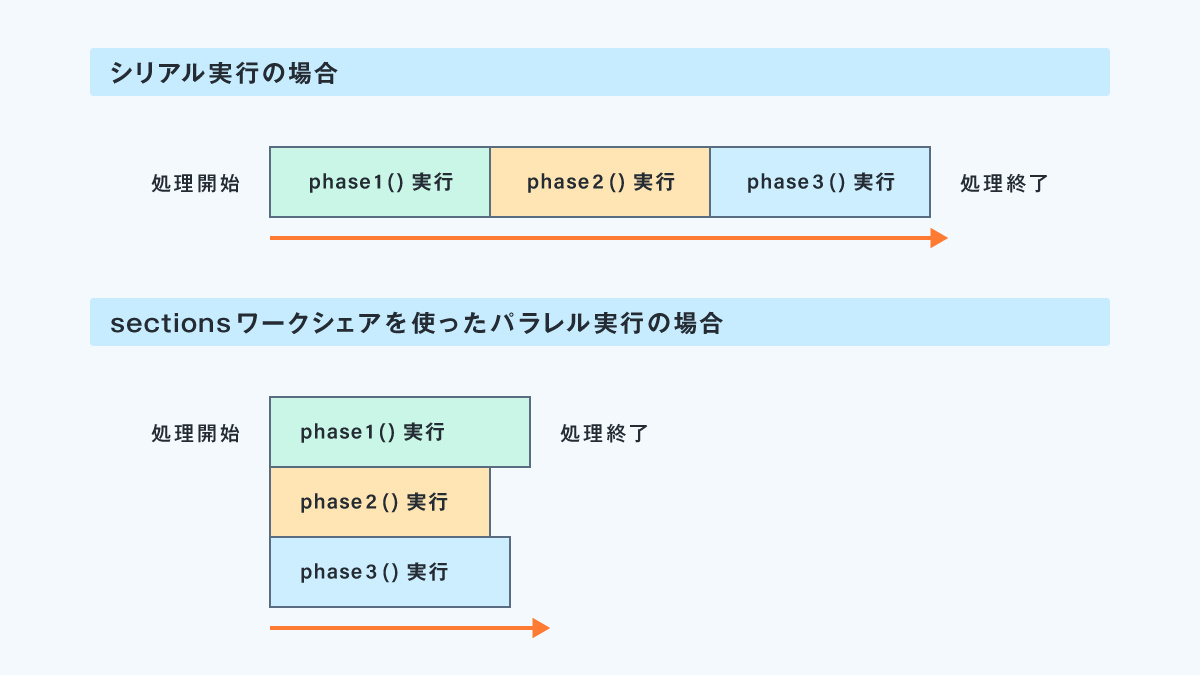
以下のコードが、sectionsワークシェアのコード例です。
#pragma omp parallel sections
{
#pragma omp section
phase1();
#pragma omp section
phase2();
#pragma omp section
phase3();
}
forワークシェア同様、簡単に並列処理を記述できますね。
こちらも、OpenMPに対応していないコンパイラではpragma行が無視されるだけなので、シングルスレッドで実行(シリアル実行)されることになります。
以下、sectionsワークシェアの実行イメージ図です。
③ OpenMPのリダクション
リダクションという言葉には「縮小」「削減」などの意味があるのですが、ここでは回答をまとめるくらいの意味になるでしょうか。
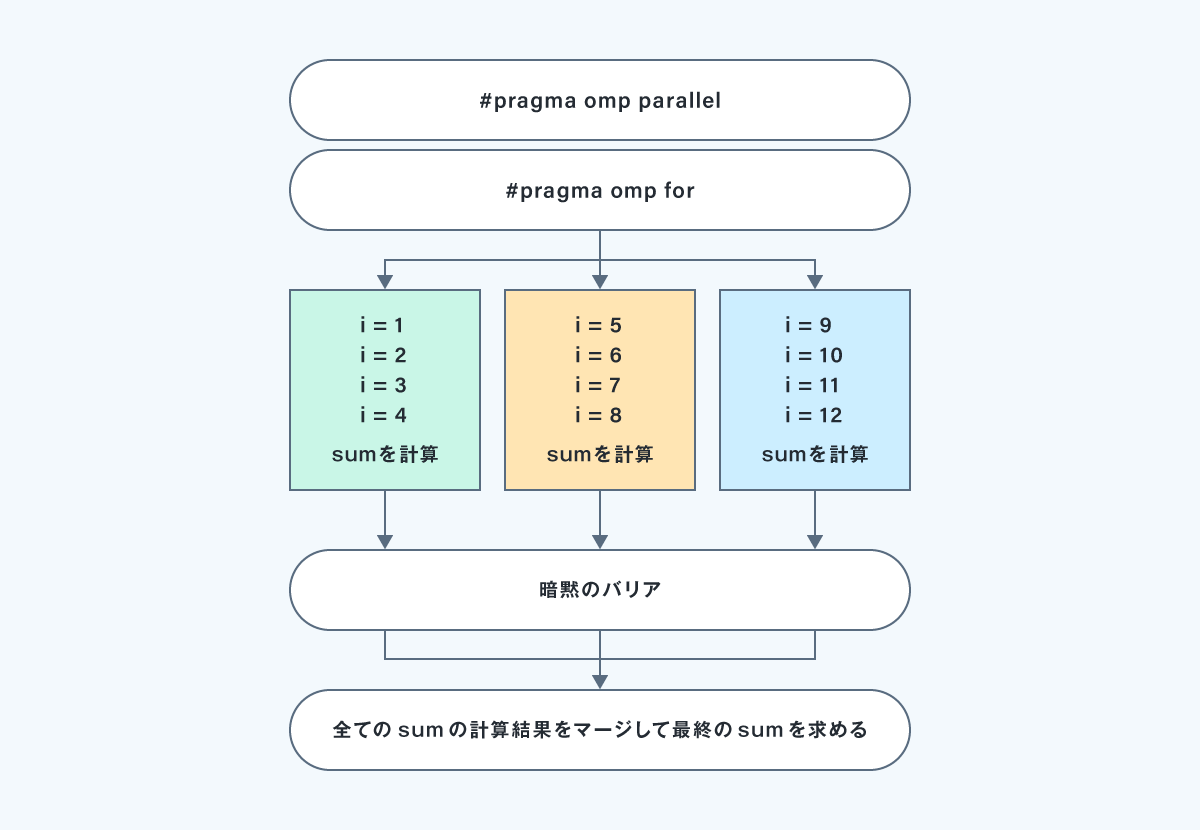
コード例は、以下になります。
#pragma omp parallel for reduction (+:sum)
for (i = 1; i < 定数; i++) {
sum += a[i] * b[i];
}
2つの配列を掛け算した結果の総計を求めているのですが、それぞれのワーカスレッドのローカルコピーで計算されたsumを最後にマージして総計を求めるという処理になります。
以下、forワークシェアにリダクションを指定した場合の実行イメージです。
いくつか例を挙げましたが(本当にOpenMPの基本部分だけです)、シンプルな記載例なのでイメージがわきやすいかと思います。
#実際の使いどころは難しいと思います。
→ある程度の計算量が無いとスレッド複数生成の負荷が勝ってしまいますので。
まぁまぁ大きい特定のメモリ領域のチェックSUM計算処理とか、CRCチェック処理などには効果を実感できる使い方になりそうと思っています(ケースバイケース)。
コアが余っていて、なおかつ処理を早く終えないと次のフェーズに進めない状態みたいなシチュエーションがあれば、OpenMPによる並列処理も検討してみて下さい。
→処理高速化の手段の選択肢の一つとして持っておいてください。
機会があればもう少し細かい制御のOpenMP構文も説明したいと思います。
長文にお付き合いいただき、ありがとうございました。
