

はじめに
社内システム開発ではGitLab CIを用いてCI環境を構築しています。
Runnerのインスタンスは、Kubernetes上で動作するKubernetes Executorを用いています。
そのRunnerが動作するKubernetesクラスターはKarpenterによるオートスケーリングを構成していますが、今回はそこで遭遇した問題と対応に用いたTipsをご紹介します。
Kubernetes Executorの仕組み
以下はKubernetes Executorの動作を表した図です。
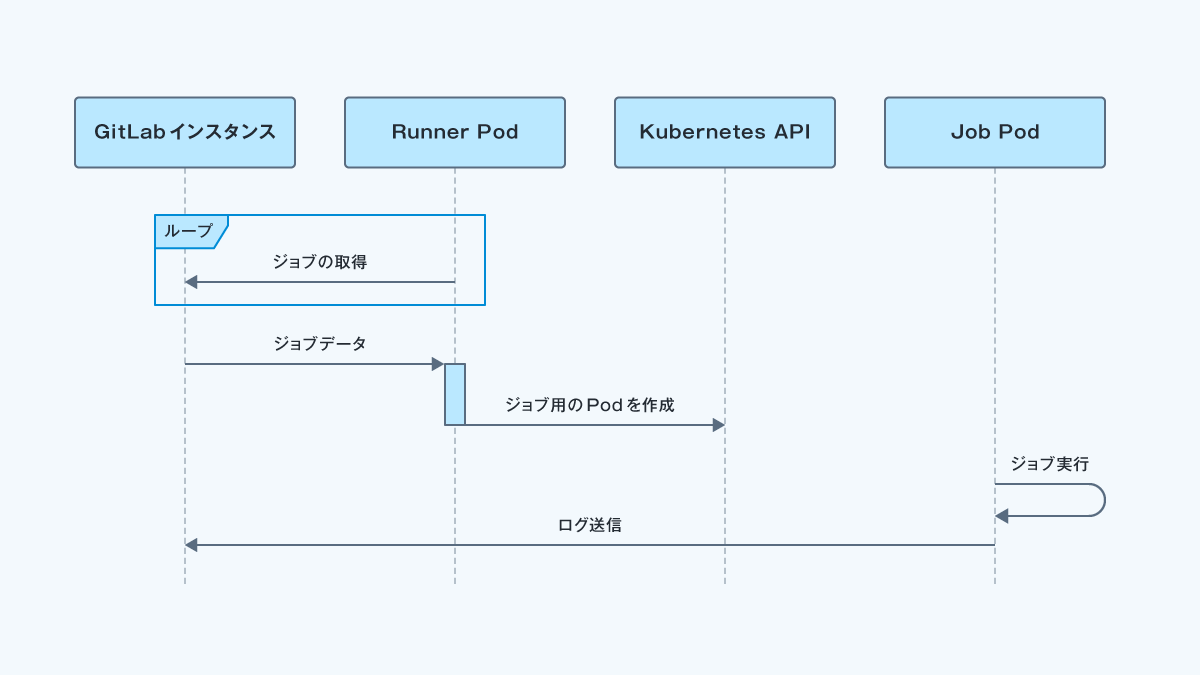
Kubernetes上にはRunnerが動作するPod(以下、Runner Pod)が常駐しており、GitLabインスタンスに対して新しいジョブがないかどうかポーリングします。
Runner Podが新しいジョブを見つけると、Kubernetes API経由でそのジョブ専用のPod(以下、Job Pod)を立ち上げます。
GitLab上のジョブの実行ログは、Job Podのログが出力される形となります。
例えば、一つのパイプラインに10個のジョブが定義されていると、10個のJob Podが立ち上がる形となります。
遭遇した問題
冒頭述べた通り、Runner Pod、Job Podが動作するクラスターはKarpenterによるオートスケーリングを行なっていますが、Job Podにはビルドなどを実行する都合上、以下のように比較的大きいリソースを割り当てています。
なお、Job Podは長時間実行されることもあるため、Node SelectorとTolerationsでオンデマンドインスタンスのみに配置されるようにしています。
runners:
config: |
[[runners]]
[runners.kubernetes]
cpu_request = "2"
memory_limit = "8Gi"
service_cpu_request = "100m"
service_memory_limit = "2Gi"
helper_cpu_request = "400m"
helper_memory_limit = "600Mi"
service_account = "gitlab-runner"
[runners.kubernetes.pod_annotations]
"pod-cleanup.gitlab.com/ttl" = "1h"
"karpenter.sh/do-not-evict" = "true"
[runners.kubernetes.node_selector]
"eks.amazonaws.com/capacityType" = "ON_DEMAND"
[runners.kubernetes.node_tolerations]
"capacityType=ON_DEMAND" = "NoExecute"
poll_interval: 5
poll_timeout: 3600
サービスコンテナやヘルパーコンテナを含めると、1Podあたり、CPU 2500m、メモリ 10.6Giを要求する形となりますが、クラスターにそれほどの空きがあることは少なく、Karpenterによるノードのスケールアウトを待つことになります。
EC2の立ち上げやクラスターへの参加はそれなりに時間を要するため、結果としてジョブの実行が数分以上待ちになる状態となってしまっていました。
バルーンPodによる解決
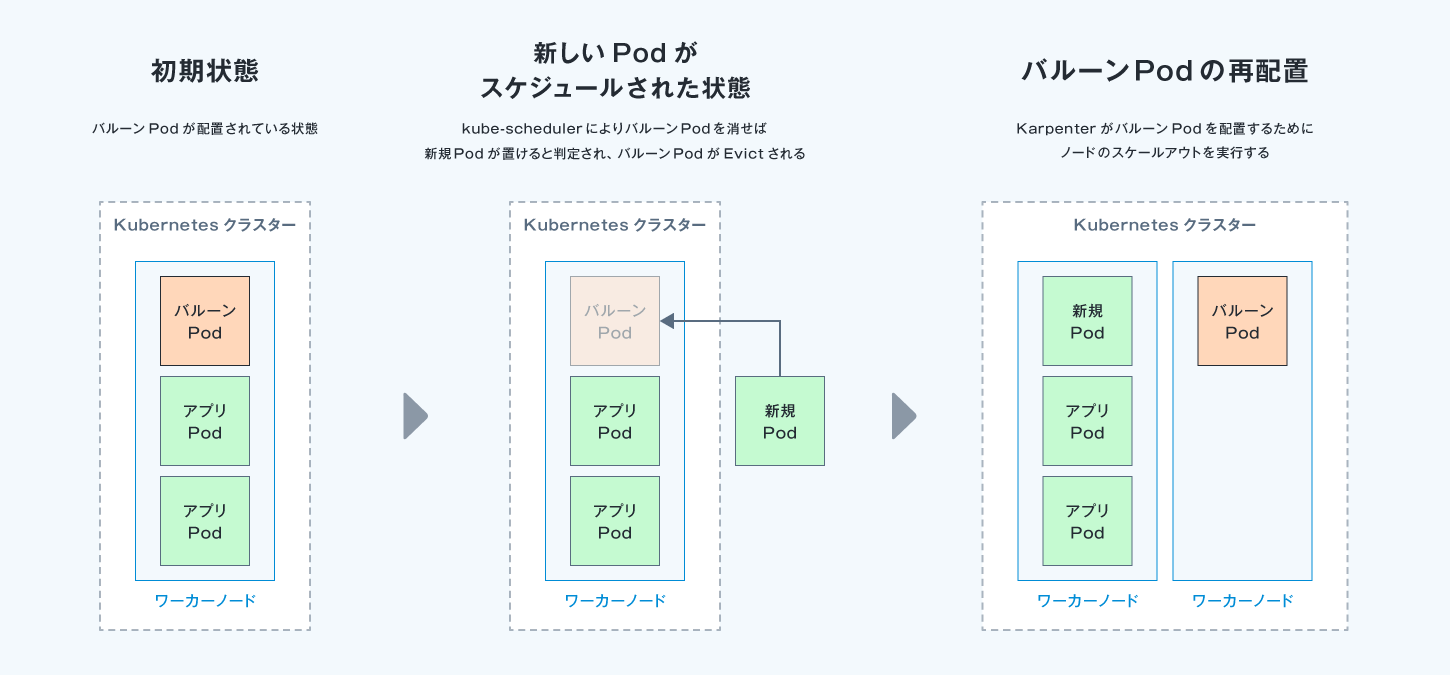
前述のようにKubernetesノードのスケールアウト待ちでPodが長時間立ち上がらない問題の緩和策として、バルーンPodというテクニックを用いました。
バルーンPodは、何か特別なミドルウェアや仕組みではなく、リソースを確保した何もしないPodをあらかじめ配置しておき、PriorityClassで優先度を通常以下にしておくことで、新しいPodがスケジュールされた際にバルーンPodが退避(=プリエンプション)され新しいPodが配置されるようにするというテクニックです。
(風船のように割れることからそのように呼ばれているようです。)
動作イメージは以下です。
バルーンPodに設定するPriorityClassは、以下のように定義しました。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: balloon
value: -10
preemptionPolicy: Never
globalDefault: false
description: "Balloon pod priority."
バルーンPod自体は以下のように定義しました。
重要な部分はpriorityClassNameの指定です。ここを設定し忘れると通常Podと同じ優先度になるため、プリエンプションの対象として優先されません。
Job Podと同じようにバルーンPodもオンデマンドインスタンスに配置されるようにしています。
apiVersion: apps/v1
kind: Deployment
metadata:
name: balloon
spec:
replicas: 3
selector:
matchLabels:
app: balloon
template:
metadata:
labels:
app: balloon
spec:
priorityClassName: balloon
nodeSelector:
eks.amazonaws.com/capacityType: ON_DEMAND
tolerations:
- effect: NoExecute
key: capacityType
operator: Equal
value: ON_DEMAND
containers:
- image: 'registry.k8s.io/pause:3.9'
imagePullPolicy: IfNotPresent
name: balloon-pause
resources:
limits:
cpu: "2.5"
memory: 12Gi
requests:
cpu: "2.5"
memory: 12Gi
KedaによるバルーンPodの起動数コントロール
今回のバルーンPodはリソース量も大きいため、常時立ち上げておくとお財布的にも優しくありません。
我々のCI環境は、定期実行などはほとんどないため、以下のように定時内: 5、定時後しばらく: 3、それ以外: 0というふうにレプリカ数をコントロールしています。
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: balloon
spec:
cooldownPeriod: 300
minReplicaCount: 0
scaleTargetRef:
name: balloon
triggers:
- metadata:
desiredReplicas: "5"
start: 30 8 * * *
end: 00 18 * * *
timezone: Asia/Tokyo
type: cron
- metadata:
desiredReplicas: "3"
start: 00 18 * * *
end: 00 22 * * *
timezone: Asia/Tokyo
type: cron
