前回の記事(掛け算処理)に続いて割り算処理です。
といっても内容はかなり似通っています。
被除数:A ÷ 除数:B = 商:C + 余り:D
…とするとAから何回Bを引けるのか?が商のCとなりますね。
なので、A - BをA’に代入
→続けてA’ - BをAに代入、
…この処理をBが引き算の答えを代入したA’より大きくなるか、イコールになるまで繰り返せば整数除算処理となります。
既視感のある展開だと思いますが、この処理には致命的な欠陥がありますね。
例えば、16bit整数割り算演算(符号なし)で、
被除数:A=65,535、除数:B=1とすると
上記のループ処理は65,535回も繰り返してしまいます。
これでは速度的に使い物になりませんよね。
なので、効率よく商を求める方法を探ります。
被除数:A ÷ 除数:B = 商:C + 余り:D
この式の関係は以下のように置き換えることができます。
被除数:A = 除数:B × 商:C + 余り:D
(つまり「被除数:A => 除数:B × 商:C」 )
そして、商:Cはいくつになるのか判りませんが2のべき乗の塊で表現できます。
なので、商となる値を求めるために(16bit整数割り算処理として)16bitの最上位から最下位まで順番に一つのビットが立っている状態を除数と掛けて
(一つのビットが立っている状態を掛けるというのは、2のべき乗の掛け算となるので単に左シフトするだけとなります)
その値が被除数から引けるか?…を順番に確認していき、すべての条件が成立するビットをまとめれば最終的な商の値が求まります。
→上述の不等式を満たす最も大きい値を求める処理を実行するということです。
つまり16bit整数除算の場合は、以下の処理となります。
① B × 2^15 はAより小さいか? →商:Cは15bit目が立っている(32,768以上の数である)
② 条件成立ならAからB × 2^15を引いて更新してAとして次のbitの処理へ進む
③ B × 2^14 はAより小さいか? →商:Cは14bit目が立っている(16,384以上の数である)
④ 条件成立ならAからB × 2^14を引いて更新してAとして次のbitの処理へ進む
…最下位bitまで繰り返し。
上記の処理の規則性をそのままフローチャートに起こすのは簡単ですね。
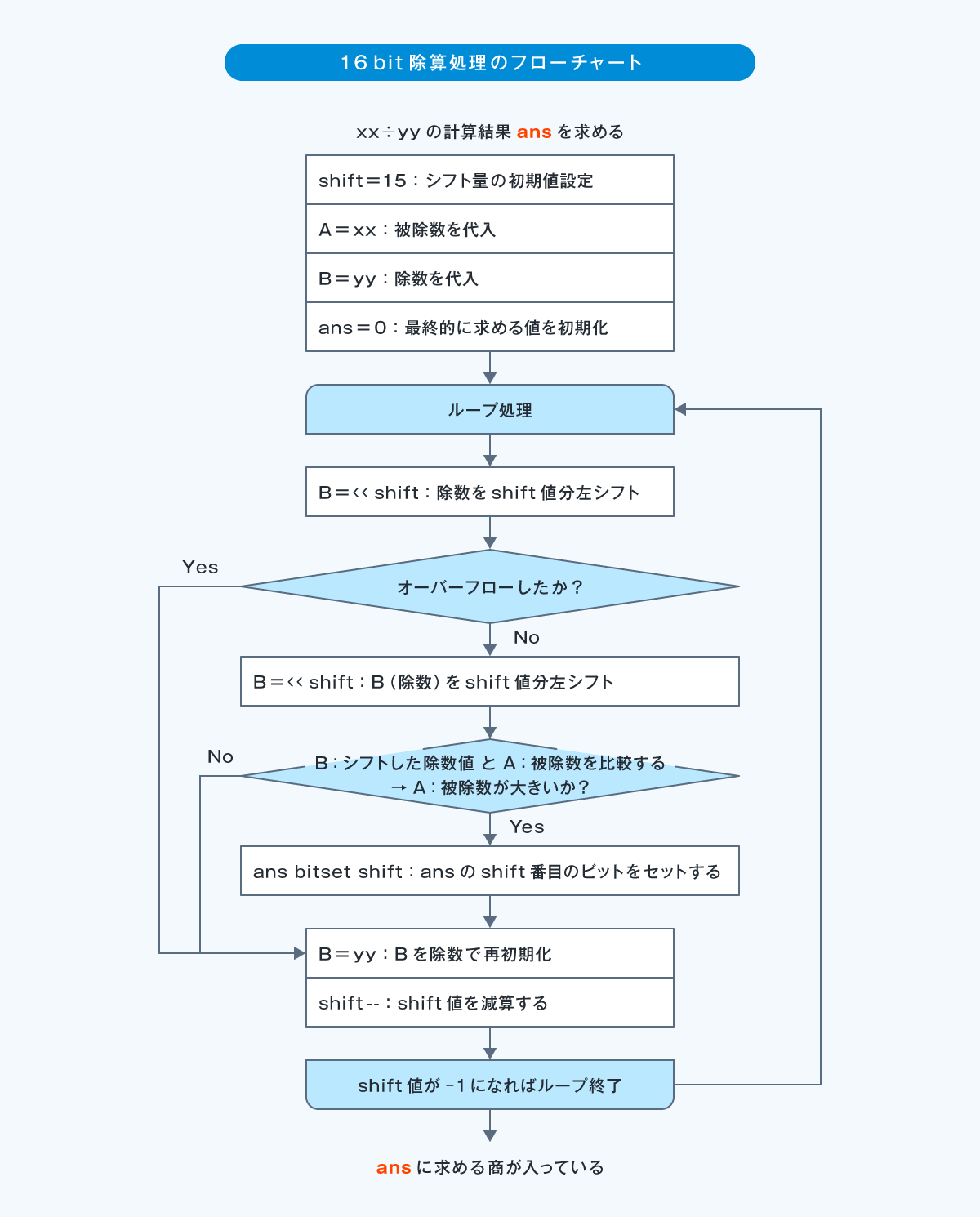
上記はあくまで例ですが、掛け算処理と比べて上位bitから順番に引いていかねばならないことに注意です。
最後にタイトル回収なのですが、
多くの掛け算・割り算命令が機械語レベルで装備されているCPUにとって、加算・減算処理よりも掛け算・割り算処理は時間が掛かるものです。
その理由は掛け算・割り算処理にはCPU内部でシフト+加算・減算処理が何回も実行されているということだからですね。
そして特に掛け算処理よりも割り算処理に時間が掛かることが多いのですが、それは上位bitから順番に引いていかねばならないこの制約があるからです。
掛け算処理には並列で処理できる余地がかなりあるので、フローチャートだけを見ると掛け算も割り算もほぼ同等の処理をやっているように見えますが、割り算処理がより時間が掛かることになってしまうのです。
つまり「コンピュータは割り算が苦手」となります。
ちなみにベテランの技術者になると「定数で4分の1にする」のような処理があるとほとんど脊髄反射的に2bit右シフトで代用したりします。
さらにいうと「定数で4分の3にする」だと被除数を1bit右シフト+被除数を2bit右シフトで求めたりします。
定数式なので上記フローチャート(+掛け算のフローチャート)のどこのビットが条件成立するのか最初から判っているので、ループ処理を省略して速度最適化しているわけですね。
(たぶんコンパイラの速度最適化をオンにした時も同じ機械語コードを吐き出すと思います)
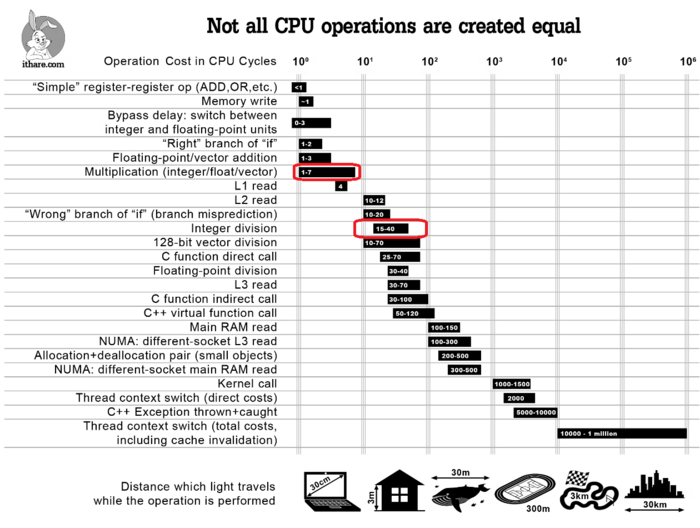
なので比較的最新のCPUでも、基本的には以下の処理時間の関係であることは覚えておいた方が良いかと思います。
割り算>掛け算≒(もしくは>)加算=引き算
引用:IT Hare on Soft.ware
「Infographics: Operation Costs in CPU Clock Cycles」
http://ithare.com/infographics-operation-costs-in-cpu-clock-cycles/