

モデル発表から少々時間が経っており、最新情報ではないですが、「XMem」という非常に高精度なモデルと巡り合ったので簡単にご紹介まで。
モデル情報(論文、GitHub)
XMem
Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
- GitHub:https://github.com/hkchengrex/Xmem
- 論文:https://paperswithcode.com/paper/xmem-long-term-video-object-segmentation-with
概略
| 項目 | 内容 |
|---|---|
| 認識/追跡精度 | ○ 領域の認識(セグメンテーション)精度、追跡精度ともに非常に優秀 ※MOT/SOT/VOT/VOS各タスクの様々なモデルと比較検証したが、XMemが群を抜いた精度感 ○ 対象の重なり、スイッチング、遮蔽、フレームアウト/イン等、各種変化にも頑健 × 似たような特徴量を持つ物体同士の分離が難しい等の精度課題はあり (ただし、これはその他モデルでも同様で難易度が高い) |
| 認識/追跡対象 | ○ (いわゆるSAMではないが)「Segment Anything」、つまり「あらゆる物体/対象の認識が可能」 ※開始フレームで追跡対象を指定(該当領域をマスク)することで、以降その対象を追跡できる。 なお、このマスクも、開始時に100%完全でなくても、時間経過とともに徐々にうまく自己補正/補完していきながら、しばらくすると本来の対象を綺麗に捉えられるようになる |
| 処理速度 | ○ 処理速度面も(VOSタスクにおいては)優秀 ※VOSタスクはどうしても処理速度がボトルネックになるモデルが多いが、このXMemは、GPU上で20-30fps程度とそれなりの速度を実現。 さすがにリアルタイム性の点では厳しいが、VOSタスクの他の高精度モデル群と比較してもかなり早い部類 |
なお、前述のGitHub内にもリンクがありますが、この「XMem」をベースとしたさらに後発の、XMem++、Cutie、Tracking-Anything-with-DEVA、といったものもあります。
これらは未検証ですが、さらに高性能な予感がします。
モデル構造
概略
(前述の論文より引用)
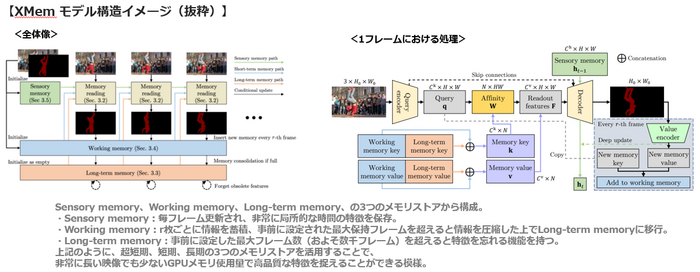
ポイント
上記だとイメージしにくいかもしれませんが、ざっくりいうと、
- 3つの記憶アルゴリズム(感覚記憶、作業記憶、長期記憶)を持ち、
- transformerに近いself-attention的な機構を使用し、性能を担保しつつ、メモリ節約と処理速度の向上を実現、
という点になります。
※詳細は別途論文等をご参照ください。
もう少し嚙み砕くと...
物体を追跡するうえで、対象の特徴を記憶/蓄積できればできるほど、(過去の情報と現在と比較して)マッチングもしやすい
↓
ただ、そうなると記憶するために膨大なメモリが必要 = メモリ爆発を引き起こす
↓
上記をうまく対処したアルゴリズム
という感じのものです。
単にメモリ操作を効率良くしただけではなく、それをベースにしつつ高度な認識/追跡を可能にしているようです。
サンプル結果
GitHub上にもデモ動画がありますのでそちらを参照ください。
しばしば、こういったモデルのGitHub/論文上のデモでは、何でもうまくいきそうな結果が紹介されていたりするものの、実際に試すと若干そうでもない感...が付き纏うことが多いですが...
実際に手元で任意の追跡向け動画データを検証したり、他のVOS高精度モデル群からいくつか厳選して比較検証してみたところ、抜群の精度/性能で、他モデルより1歩2歩抜きん出た印象でした。
課題、弱点
とはいえ、さすがに何でもかんでもうまくいくわけではありません。
前述の「特徴」の項とも重複しますが、この「XMem」は、VOSタスク界隈の中では非常に高性能ではあるものの、人物の重なり/遮蔽等に対しては、やはりどうしても追跡が難しいシーンは色々あります。
※特に、似たような人物/対象が多数いるようなシーン等。ただし、これは「XMem」に限らず、VOSタスク群では共通課題/弱点です。
なお、当方の検証時は学習フェーズまで手は出していませんでしたが、上記弱点部分を補強してあげるような効果的な学習を考えることで、ある程度はカバーできる部分はあるかもしれません。
以上、かいつまんだモデル紹介ではありますが、実際に検証した当時は(特にVOSタスク群において)衝撃的な精度感でしたので、興味があればぜひ試してみていただければ幸いです。
