

概要
お疲れ様です!! Difyのイテレーションブロックの制約について、FastAPIを用いた解決策を提示します。 過去のイテレーション結果を次のイテレーションで使用できるようにします。
Difyのイテレーションブロックの制約
今回解決したいDifyのイテレーションブロックの制約は、「前のイテレーションの結果を次のイテレーションで参照できない」というものです。
今回この制約が問題となったのはRefine(LLMによる逐次的な要約)においてです。
Refineでは、直前の要約結果を文章と結合し、要約します。
Difyのイテレーションブロックでは直前の要約結果が参照できないため、逐次的な要約ができません。
この問題をFastAPIを用いて、無理矢理解決しました。
Refineについては以下の記事が参考になると思います。
- https://js.langchain.com/v0.1/docs/modules/chains/document/refine/
- https://zenn.dev/tsuzukia/articles/05bfdcfcf5bd68#refine%E6%B3%95
- https://qiita.com/taka_yayoi/items/8cb2aa56523898385193#%E3%82%AA%E3%83%97%E3%82%B7%E3%83%A7%E3%83%B3-3-refine
FastAPIを用いた解決例
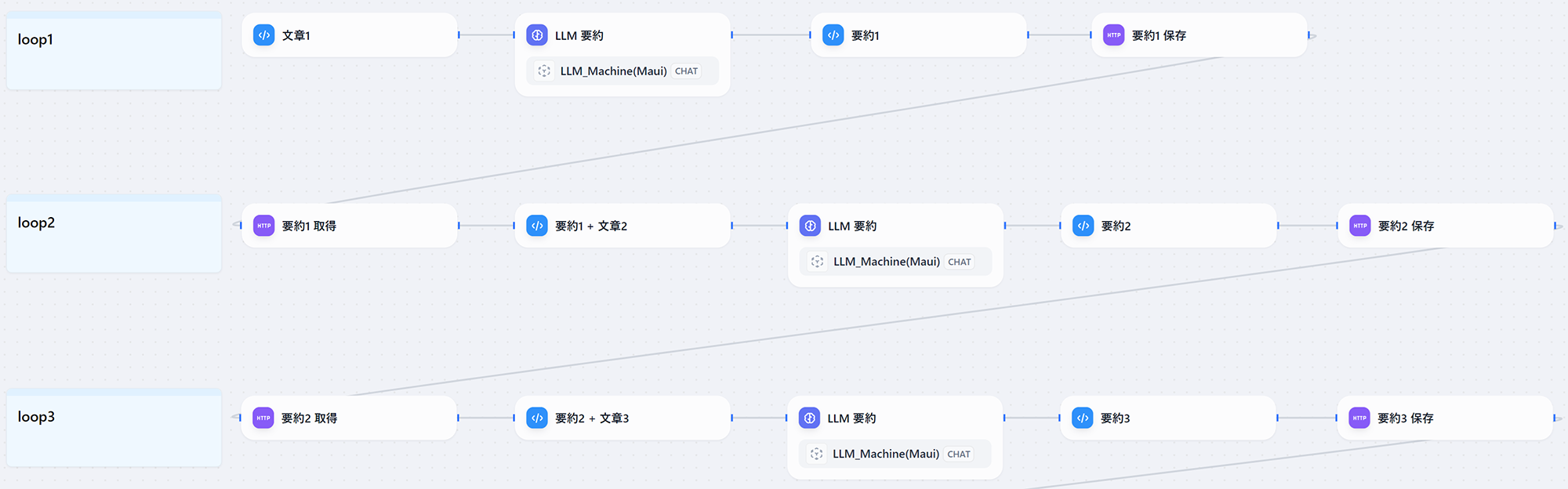
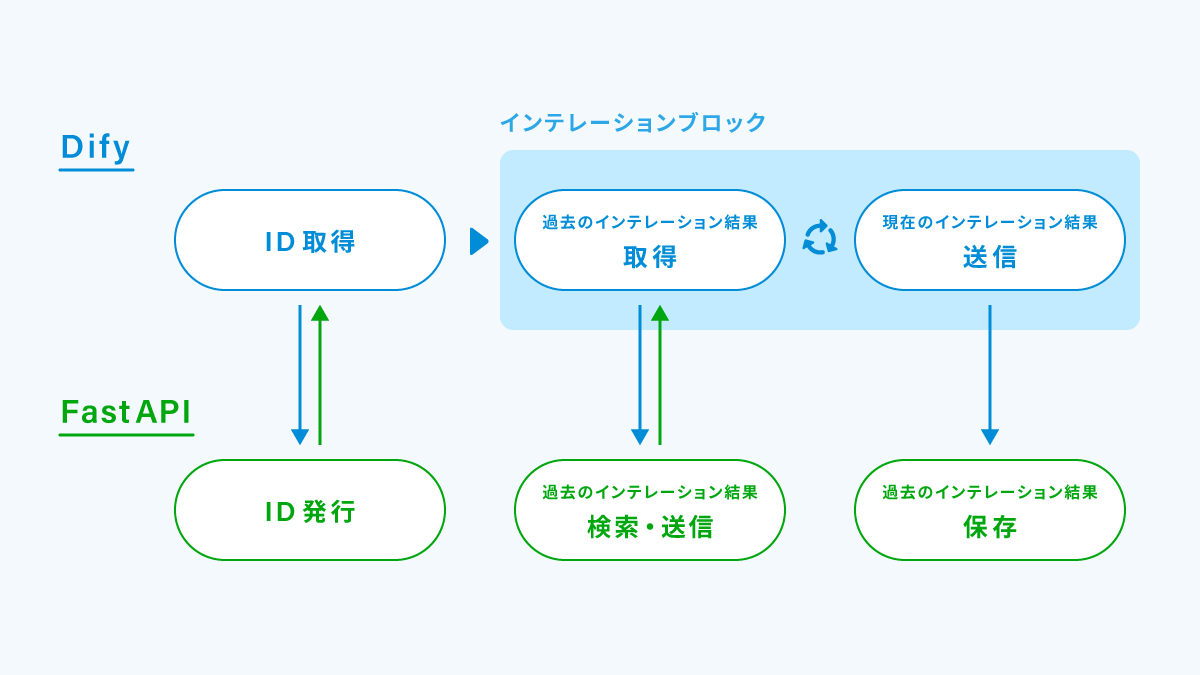
FastAPIを用いて、イテレーション結果を一時保存するAPIサーバを立てることで、過去のイテレーション結果を参照できるようにしました。
以下の図は、イテレーションの流れを書き下したものです。HTTPブロックを使用してFastAPIとやり取りしています。
以下の図は、DifyとFastAPIの通信イメージです。
実装例(Dify)
今回は簡単のため、LLMでの要約ではなく、単純な文字列結合の例で説明します。
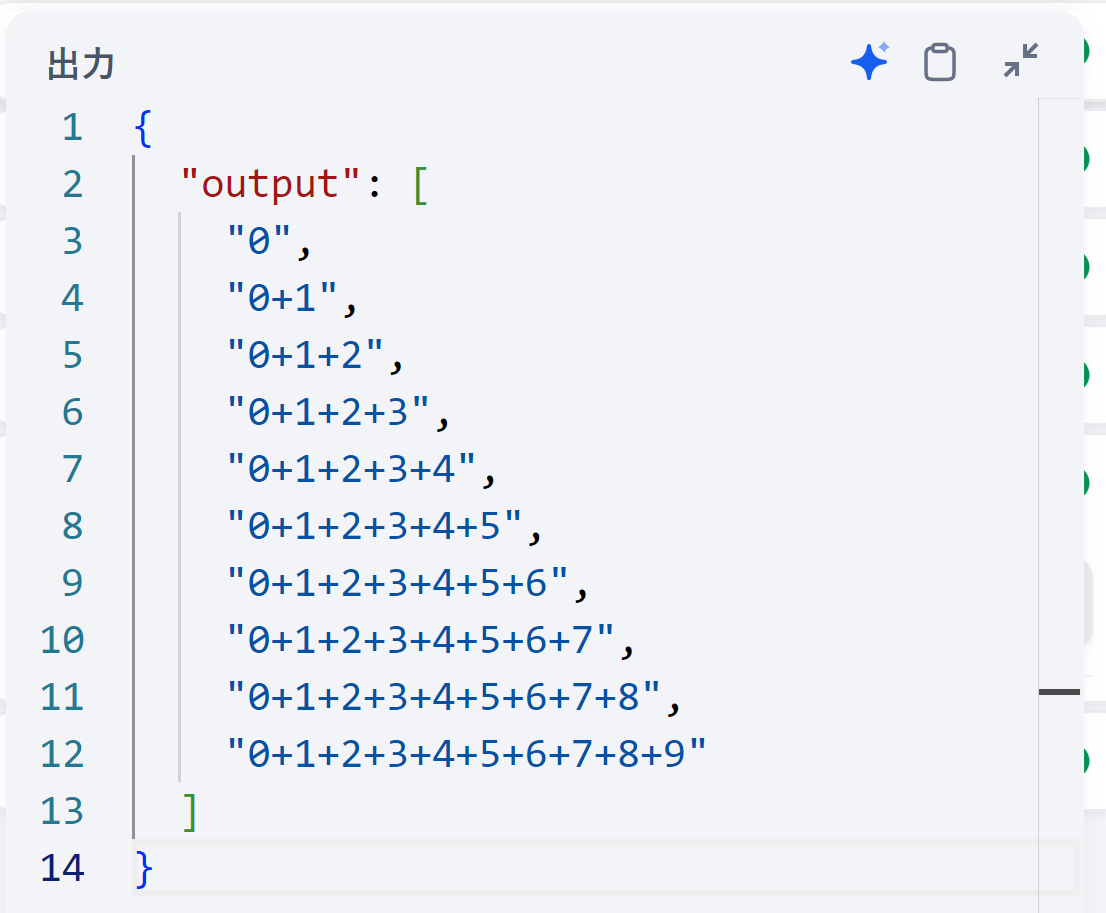
想定出力
10回のイテレーションを回し、イテレーションごとにインデックスを文字列に結合していきます。
最終出力が"0+1+2+3+4+5+6+7+8+9"となることを想定します。
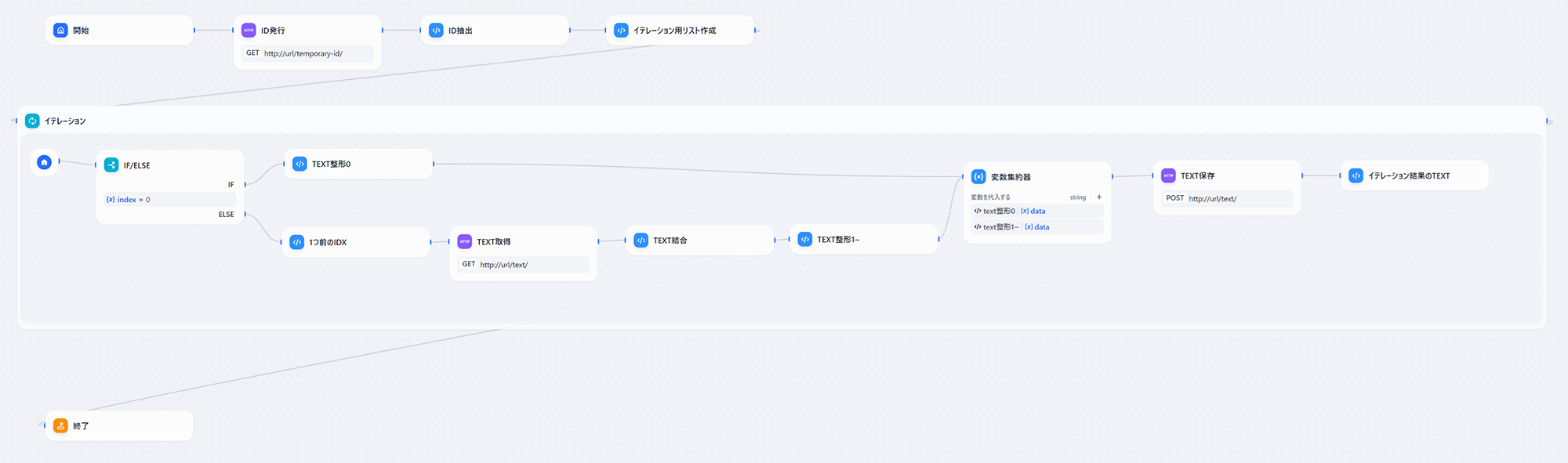
ワークフロー全体像
- ID発行
- 直前のイテレーション結果のテキスト読み込み
- イテレーション結果のテキスト保存
- ID発行
どの保存情報を参照すべきか判別するためにIDを取得します。
イテレーションではこのIDを使用します。

- 直前のイテレーション結果のテキスト読み込み
直前のイテレーション結果のテキスト読み込みます。
HTTPリクエストブロックを使用し、FastAPIで構築したAPIを叩きます。

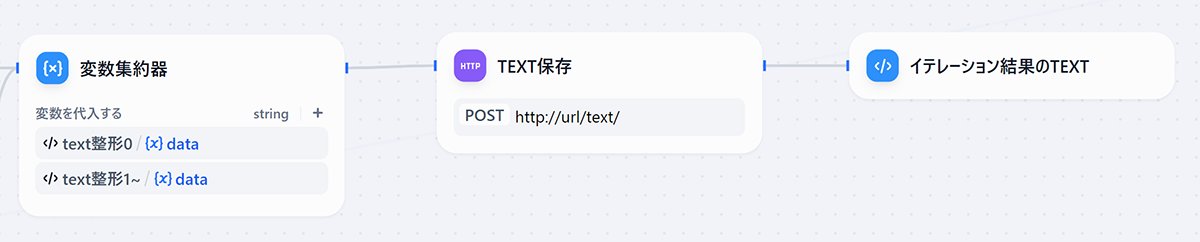
- イテレーション結果のテキスト保存
直前のイテレーション結果と本イテレーションのテキストを結合します。
結合した結果を本イテレーションの結果として保存します。
HTTPリクエストブロックを使用し、FastAPIで構築したAPIを叩きます。
結果
ご覧の通り、最終出力が"0+1+2+3+4+5+6+7+8+9"となりました。
実装例(FastAPI)
以下FastAPIを用いた実装例です。config部分は各自定義してください。
blog用.py
from pathlib import Path
import pickle
from typing import Dict, Optional
import uuid
from uuid import UUID
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import config as CONFIG
app = FastAPI()
class TextData(BaseModel):
uuid: UUID
idx: int
text: str
@app.get("/temporary-id/")
async def generate_uuid():
"""
新しいUUIDを生成して返すエンドポイント
Returns:
Dict[str, str]: 生成されたUUIDを含む辞書
"""
new_uuid = str(uuid.uuid4())
return {"uuid": new_uuid}
@app.post("/text/")
def save_text(text_data: TextData):
"""
文字列を受け取り、辞書のリストに変換してから保存するエンドポイント
Args:
text_data (TextData): 受け取る文字列を含むリクエストボディ
Returns:
Dict[str, bool]: 処理の成否を示す辞書
"""
text_file_service = TextCacheService(text_data.uuid)
success = text_file_service.save_text(text_data.idx, text_data.text)
if not success:
raise HTTPException(status_code=500, detail="Failed to save text")
return {"success": success}
@app.get("/text/")
async def get_text(uuid: UUID, idx: int):
"""
UUIDとインデックスを指定して保存されているデータを返すエンドポイント
Args:
uuid (UUID): ファイル名に使用するUUID
idx (int): インデックス番号
Returns:
Dict[str, str]: 保存されているテキストデータ
"""
text_file_service = TextCacheService(uuid)
text = text_file_service.get_text(idx)
if text is None:
raise HTTPException(status_code=404, detail="Text not found")
return {"text": text}
class TextCacheService:
def __init__(self, uuid: UUID):
"""
TextCacheServiceクラスの初期化
Args:
uuid (UUID): ファイル名に使用するUUID
"""
self.file_path = Path(CONFIG.DIR_CACHE) / f"{uuid}.pkl"
self.data = self._load_file()
def _load_file(self) -> Dict[int, str]:
"""
ファイルを読み込み、辞書を返す関数
Returns:
Dict[int, str]: ファイルから読み込んだ辞書
"""
if self.file_path.exists():
with self.file_path.open("rb") as file:
return pickle.load(file)
return {}
def save_text(self, idx: int, text: str) -> bool:
"""
辞書にテキストを保存し、ファイルに書き込む関数
Args:
idx (int): インデックス番号
text (str): 保存するテキスト
Returns:
bool: 処理の成否
"""
self.data[idx] = text
return self._save_file()
def get_text(self, idx: int) -> Optional[str]:
"""
指定されたインデックスのテキストを取得する関数
Args:
idx (int): インデックス番号
Returns:
Optional[str]: 保存されているテキスト、存在しない場合はNone
"""
return self.data.get(idx)
def _save_file(self) -> bool:
"""
辞書をファイルに保存する関数
Returns:
bool: 処理の成否
"""
try:
self.file_path.parent.mkdir(parents=True, exist_ok=True)
with self.file_path.open("wb") as file:
pickle.dump(self.data, file)
return True
except Exception as e:
print(f"Error saving file: {e}")
return False
まとめ
FastAPIを用いて、Difyで過去のイテレーションの結果を無理矢理使用する方法を紹介しました。
今回はLLMのRefineを行いたいモチベーションでしたが、他の用途でも利用できると思います。
ネックはFastAPIとDifyで通信が発生する点です。
Difyの標準機能として過去のイテレーション結果を参照できるようになるといいですね!
今後のアップデートに期待です!
最後に
私たちのTech Blogを最後までお読みいただき、ありがとうございます。
私たちのチームでは、AI技術を駆使してお客様のニーズに応えるため、常に新しい挑戦を続けています。
最近では、受託開発プロジェクトにおいて、LLM(大規模言語モデル)を活用したソリューションの開発ニーズが高まっております。
AI開発経験のある方やLLM開発に興味のある方は、ぜひご応募ください。あなたのスキルと情熱をお待ちしています。
新卒、キャリア募集しています!
自動運転/先進運転支援システム(AD / ADAS)、医療機器、FA、通信、金融、物流、小売り、デジタルカメラなど、組込み機器やIoT、Webシステムなど様々なソフトウェア開発を受託しており、言語やOS、業務知識の幅を広げることが可能です。
また、一次請けの案件が多く上流工程から携わることができます。客先常駐でも持ち帰りでも、Sky株式会社のチームの一員として参画いただきますので、未経験の領域も上司や仲間がサポートします。
