

2つの文字列から一致する文字を検出するアルゴリズムの紹介になります。
最長共通部分列問題(LCS)と呼ばれる2つの文字列から最長の共通部分列を探すアルゴリズムになります。
※ DNAの解析とかでも使われるアルゴリズムのようです。
例を用いて考え方の紹介いたします。
以下の2つの文字列内の最長文字分列を見つけます。
- 文字列1(”ABCDCE”)
- 文字列2(”ACCDEX”)
① : それぞれの文字列を先頭から順番で取り出します。
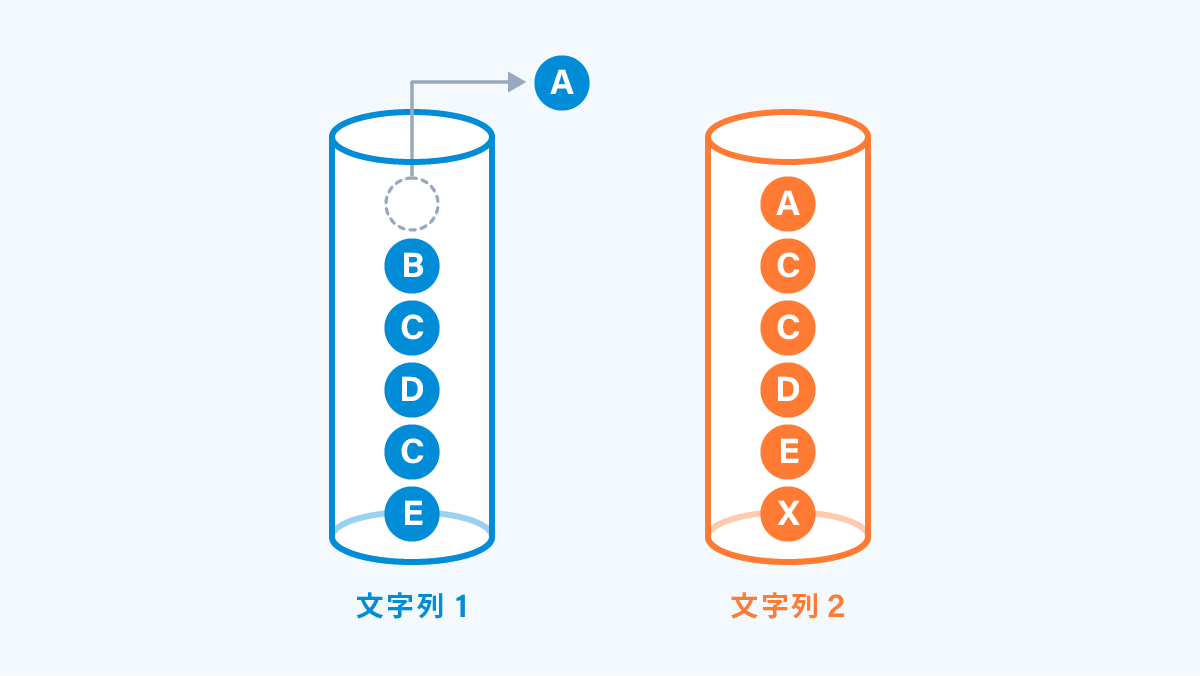
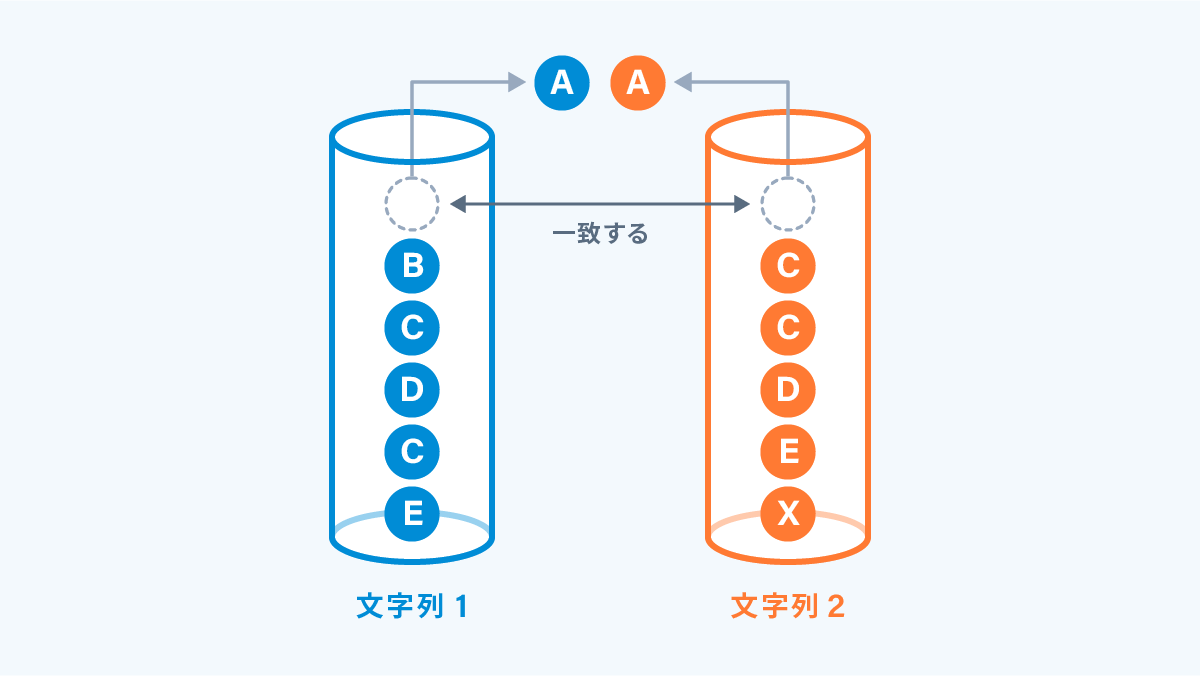
② : 一致するものがあった場合は両方の要素を同時に取り出します。
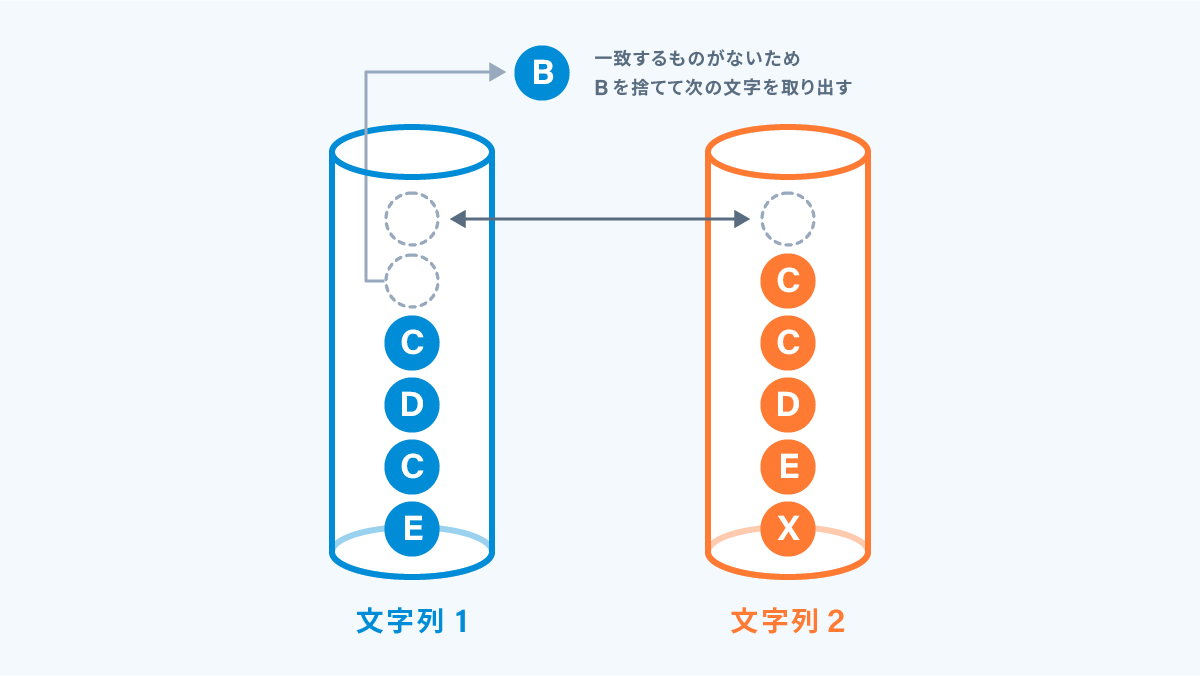
③ : 一致するものがない場合は、取り出した文字を捨て、次の文字を取り出します。
④ : ①~③を繰り返して最大の一致数になったものがLCSとなります。
少しまとめると、それぞれの先頭から順番に文字をキューから抜き出していき最終的に一緒に取り出した数が多い取り方を探すというものです。
では、今回の例で最長文字分列はどうなるのでしょうか?
- 文字列1(”ABCDCE”)
- 文字列2(”ACCDEX”)
直感的には”ACDE”となりそうな気がしますね。
実際に最長の共通部分列を求める際は対応表を作成し探査していくことになります。
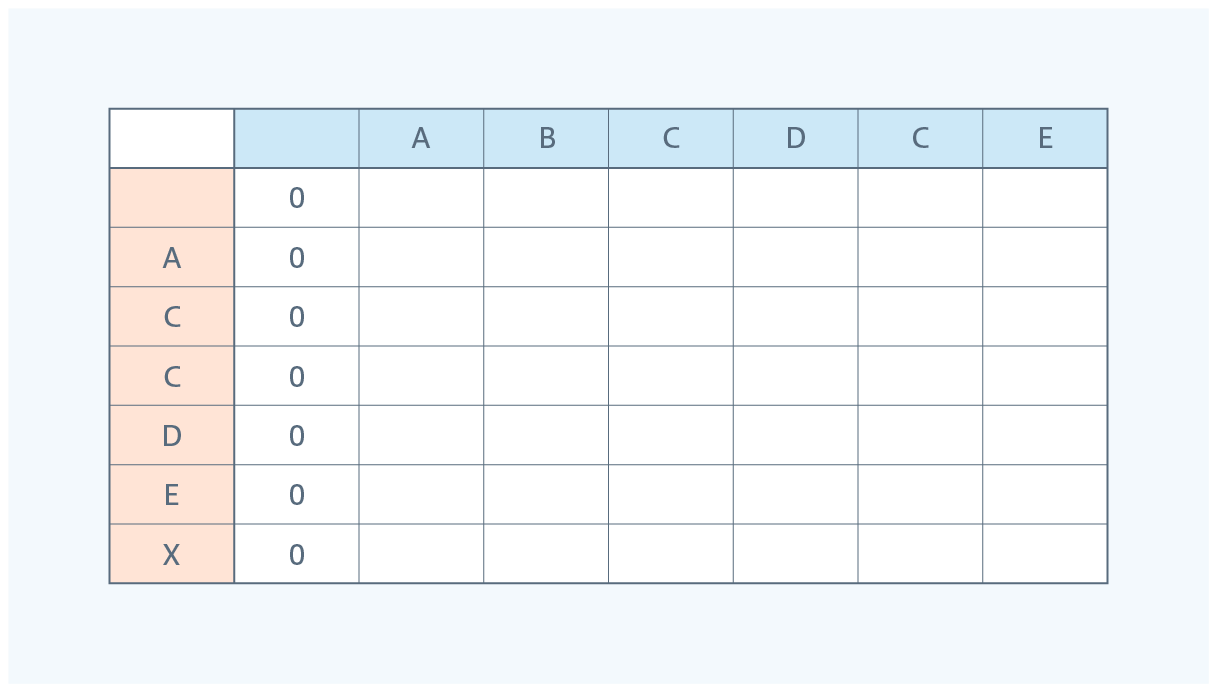
① 横軸を文字列1、縦軸を文字列2で対応表を作成します。
一致として取り出した文字数を対応表に記載していきます。
※ マッチせずに捨てた文字がわかるように、先頭に空文字を入れた表を作成します。下の表だとお互いに取り出していない個所は0になります。
② 次に文字列1の”A”を取り出す際に文字列2から最大何個取り出せるか記載します。
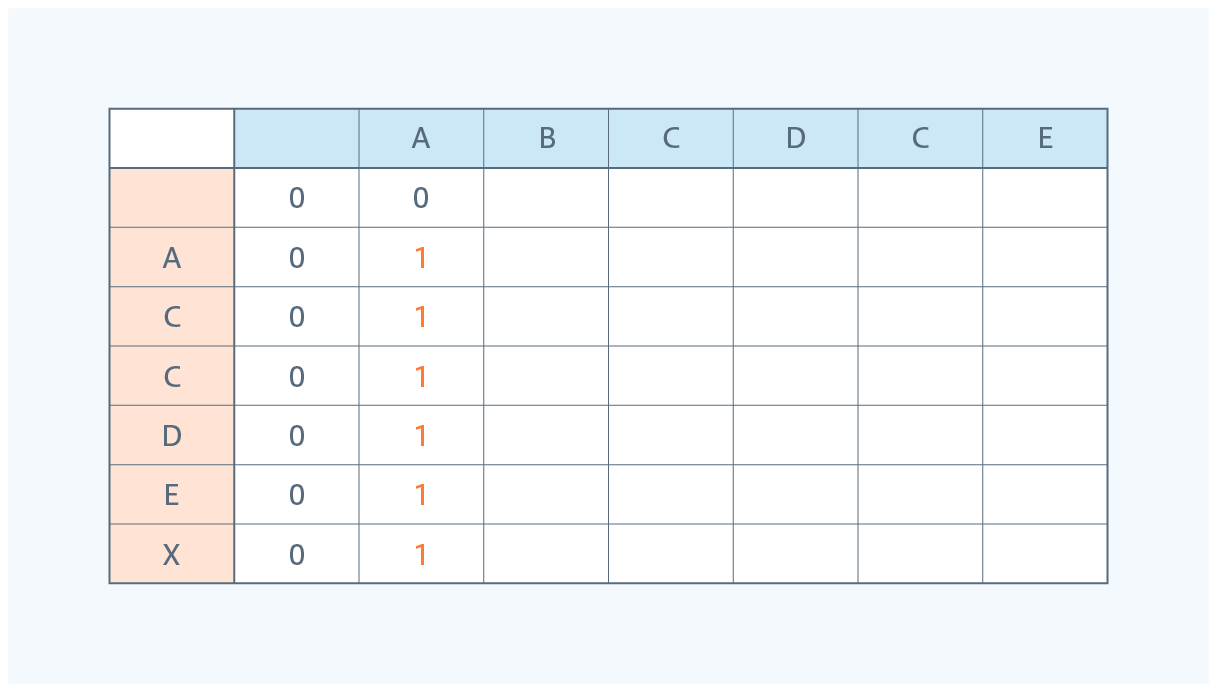
③ 文字列1の"AB"を取り出す際に文字列2から最大何個取り出せるか記載します。
”B”に一致する文字が文字列2に存在しないので、”A”を取り出した時と数の変化はありません。
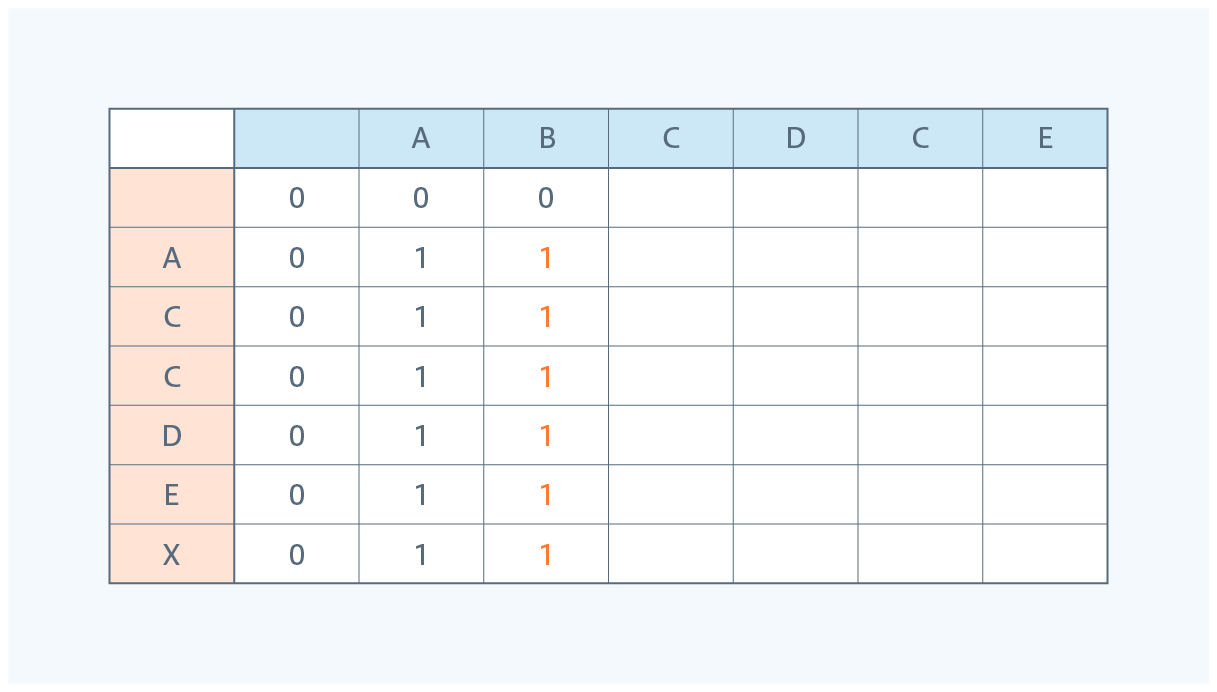
④ 文字列1の"ABC"を取り出す際に文字列2から最大何個取り出せるか記載します。
"A"を取り出した以降で、"C"を取り出せる場合は"A"と"C"を取り出せることになるため、2となります。
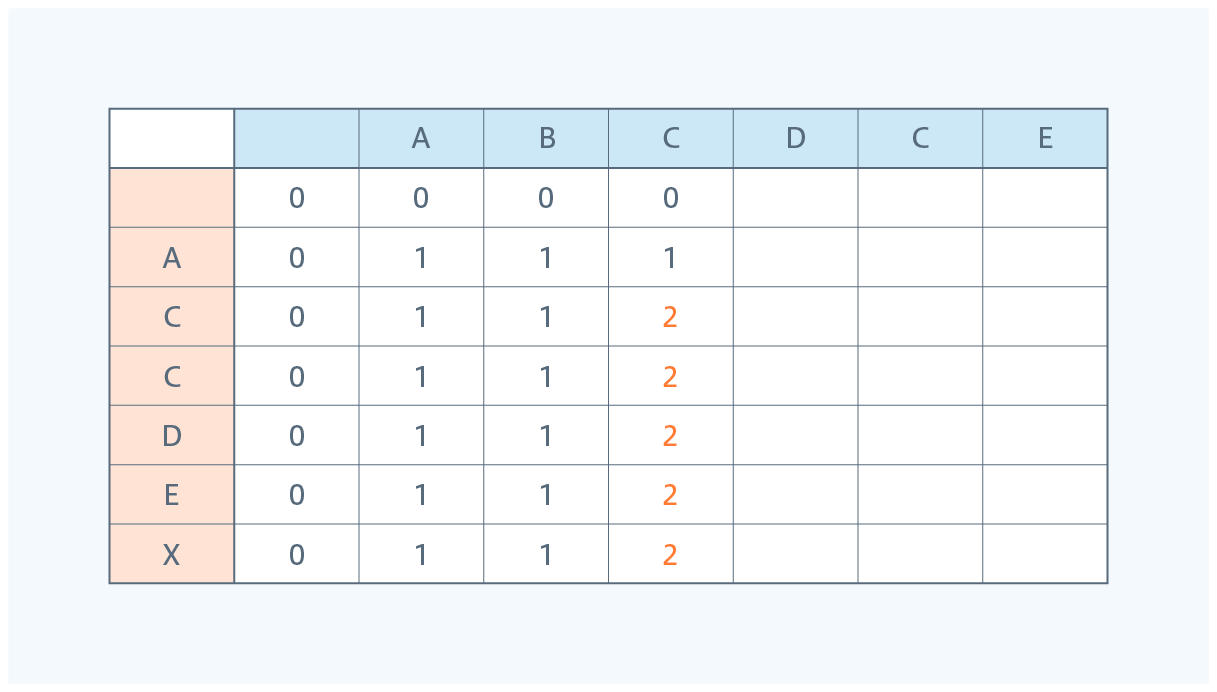
⑤ 一文字ずつ取り出す文字を増やしていき、文字列2から最大何個取り出せるか記載します。

⑥ 表の右下から左上に向けて数字が高いものを通るように辿っていきます。
※ 隣接する数字がすべて同じ場合は、斜め上に移動します。
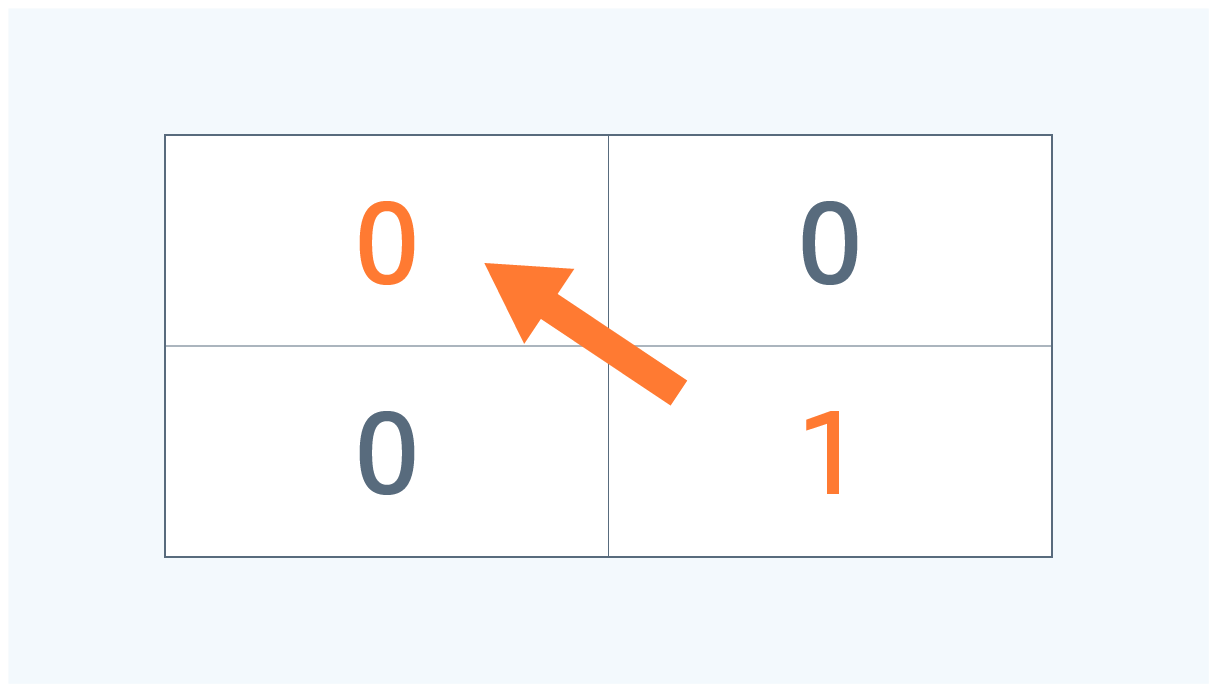
今回の例で辿るルートは以下になります。
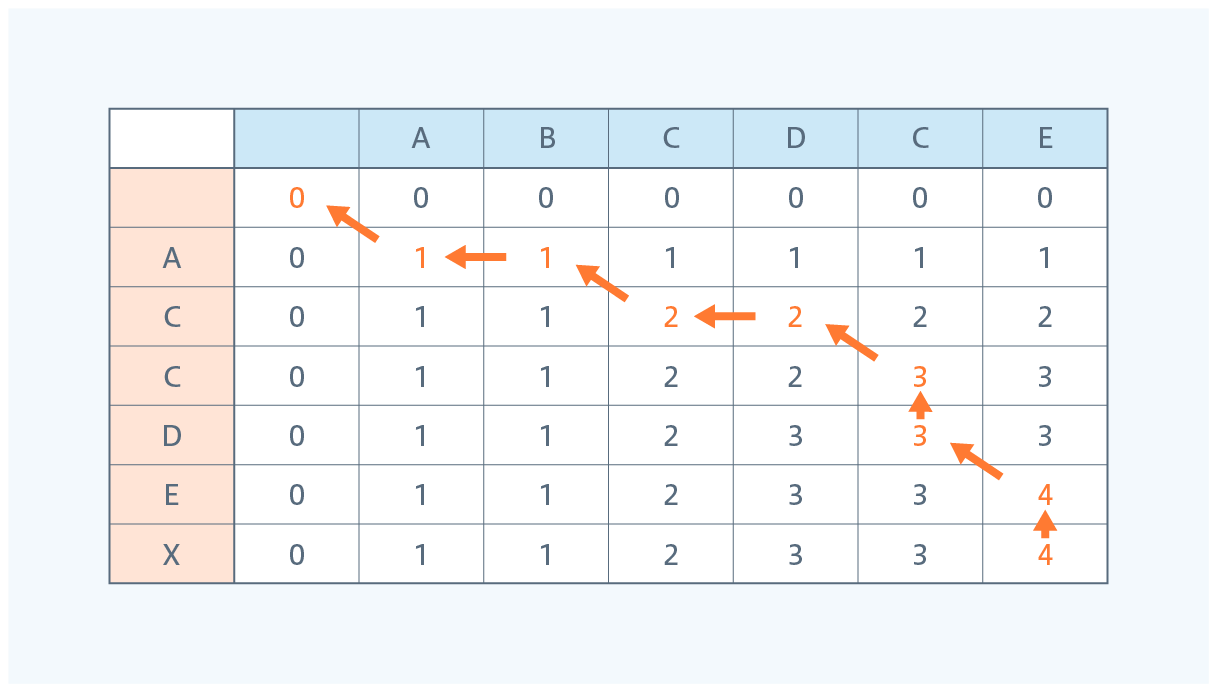
数値が変動する箇所は文字列1と文字列2の両方から文字を取り出したことになります。
今回の文字列1と文字列2で最長文字分列は"ACCE"となります。
あれ?思っていた”ACDE”と違う・・・
今回の例で、実はもう一つ最長文字分列を取れるルートが存在します。
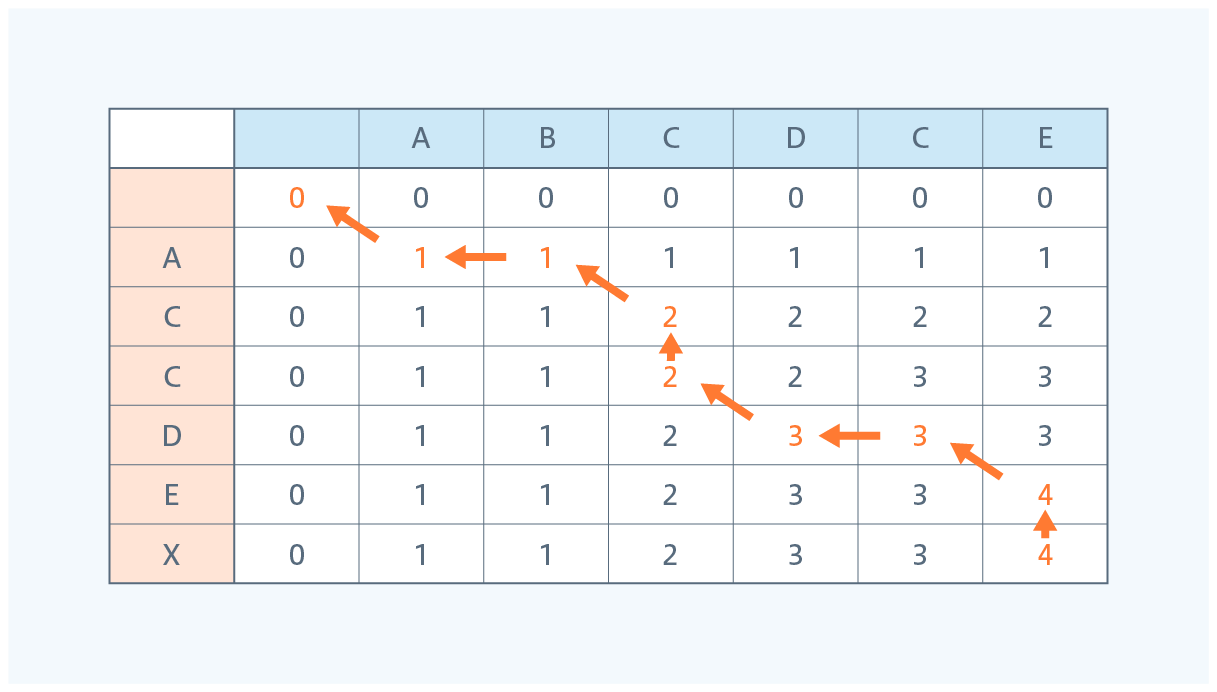
ちゃんと"ACDE"も最長文字分列でした。
この最長文字分列を探すためのルートで、以下のことも判断できます。
- ↑は「文字列1に存在しない文字」
- ←は「文字列2に存在しない文字」
↑と←に注目することで、2つの文字列の違いを検出することもできます。
最長文字分列が"ACDE"となるルートの場合は、以下の違いになります。
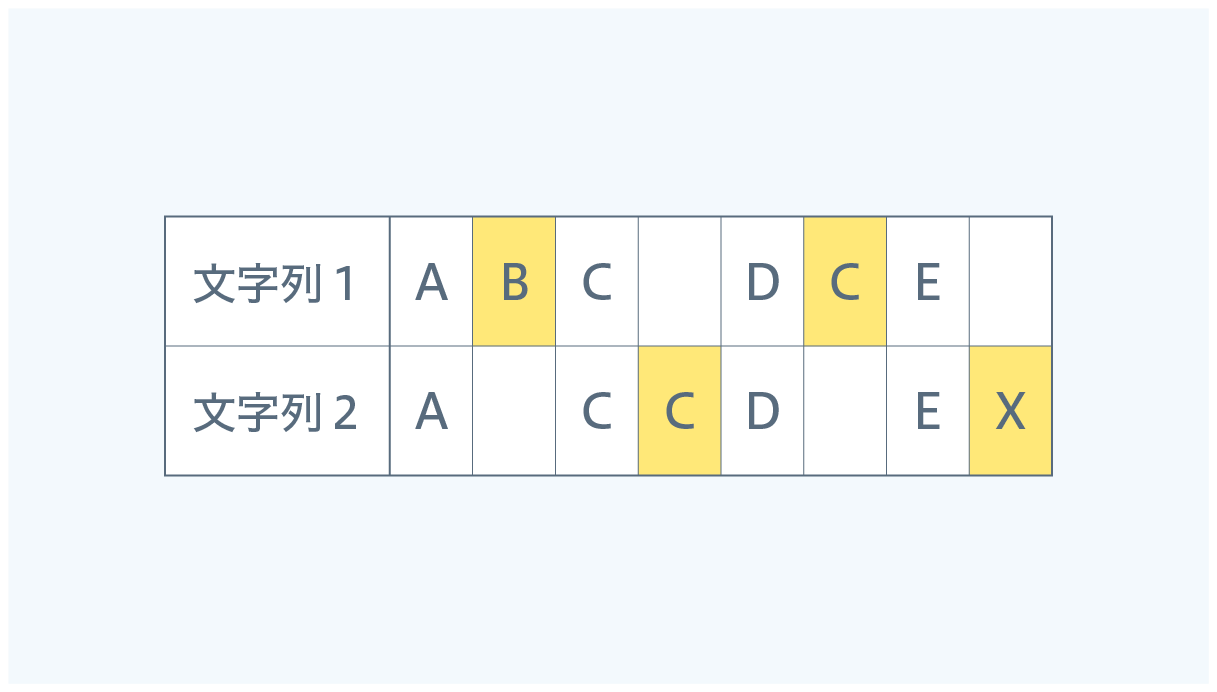
文字として一致している部分だけでなくどの部分が欠損しているのか、追加されているのかといった違いを検出することもできますので差分表示が必要なケースなどでは、一つの案として検討していただければと思います。
以上です。
最後まで読んでいただきありがとうございました。
