

作成したシステムの概要
今回は業務で利用したモデルの情報が、以下のような形式でCSVファイルとPDFファイルで蓄積されている状況を想定します。
1. 業務で用いたモデルの名称と特徴が記述されたCSVファイル

このCSVファイルには過去の業務で用いたモデルとその特徴が記述されています。
なお、LLMが抽出した情報を回答に利用していることを保証するために、これらのモデルはChatGPTに考えてもらった架空のモデルとなっています。
2. ImageClassifierX(架空のモデル)を利用したときの情報が記述されたPDFファイル

このPDFファイルにはCSVファイルに記述されている架空のモデルの内、ImageClassifierXというモデルを業務で利用した際の詳細情報について記述されています。
具体的には、データの収集方法やモデルの学習方法、学習後の精度などについてです(こちらもChatGPTに考えてもらいました)。
以上の2つのファイルから、 LLMに「社内のノウハウに画像分類に利用できそうなモデルはありますか。」といった質問を入力すると、これらの情報から質問内容に沿った情報を抽出して回答してくれるシステムを作成します。
今回は、LangChainというライブラリの内、AgentとRetrieverという仕組みを用いてシステムを作成しました。
それぞれについて簡単に説明します。
-
Agent
Agentは質問に対して、必要な情報を様々なToolから適切なToolを動的に選択して使用することで、 精度の高い回答を行うことを狙う仕組みです。
Toolには数学の問題を解くためのものやGoogle検索を行うためのものなど、多岐にわたるToolが準備されています。
例えば、「今日のニュースについて教えてください。」という質問がAgentに入力されたとします。Agentは回答を生成するにあたり、今日のニュースについて知るためにはどのような行動が必要かを推論します。
そして、Agentは今日のニュースを知るために準備されたいくつかのToolから、Google検索を行うToolを選択・使用して今日のニュースを取得します。
その後、Agentは取得した情報を踏まえて、今日のニュースについて回答を行います。
なお、Toolはどのような情報を得るために役立つのかが記述されたdescriptionという属性を持ちます。
Agentはこのdescriptionを利用することで、複数のToolからどのToolを用いるかを決定しています。 -
Retriever
RetrieverはRAG(Retrieval-Augmented Generation)という技術をToolとして実現したものです。
RAGはテキスト生成時にLLMが知らない外部情報の検索を組み合わせることで回答の精度を向上させる技術です。
具体的には、あらかじめ外部情報の文書をいくつかのチャンクという部分に分割します。
その後、それぞれのチャンクの埋め込みを計算して、チャンクと埋め込みが紐づいたノードを蓄えたインデックスを作成しておきます。
検索するときには準備しておいたインデックスを利用し、入力されたクエリに対して埋め込みを基に類似度が高いチャンクを返します。
これにより入力されたクエリに関連する情報を外部情報から抽出することが可能となります。
Retrieverには、CSVファイルやPDFファイルをそれぞれ外部情報とするCSV Retriever、PDF Retriverなど様々な種類が用意されています。
以上の技術を用いてシステムを作成しました。システムに期待される動作について、以下にその概略を示します。
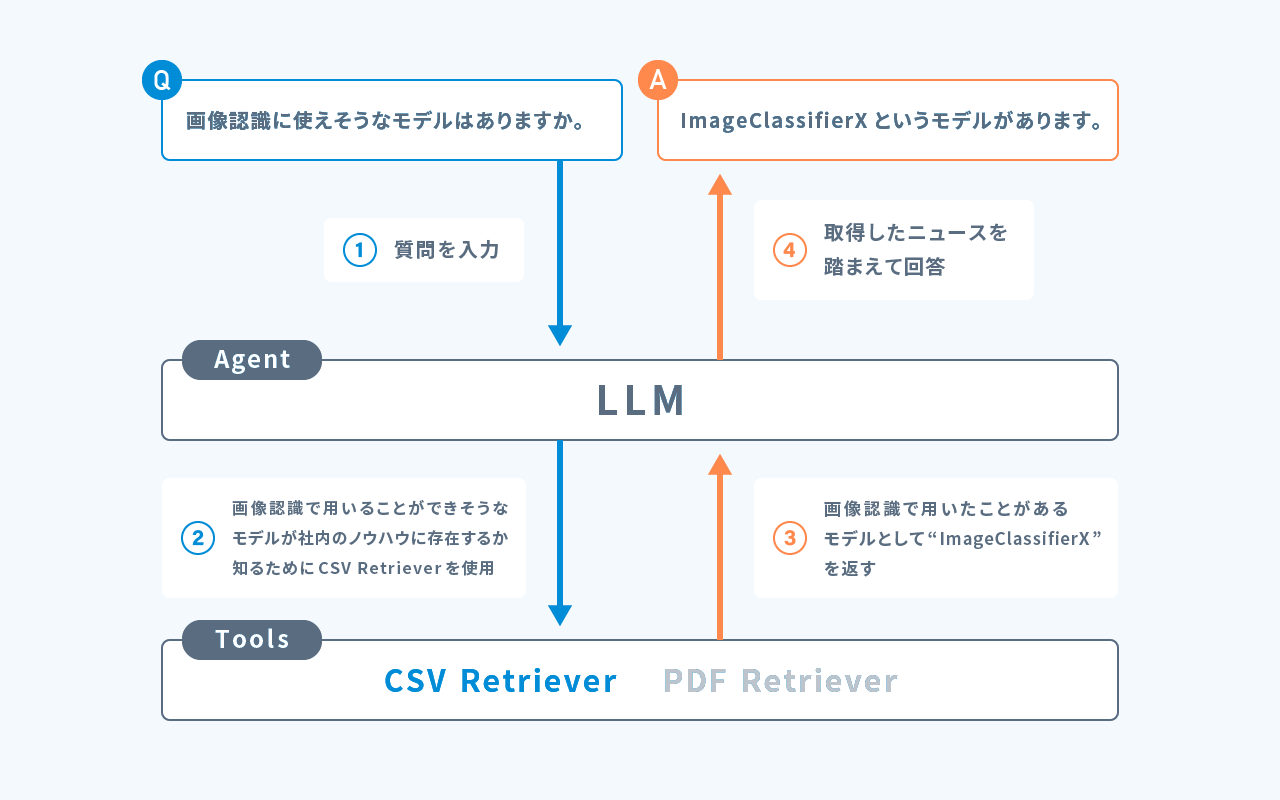
ユーザが「画像認識に使えそうなモデルはありますか。」という質問を入力したとします。Agentは画像認識で用いることができそうなモデルが社内のノウハウに存在するかを知るために、CSV Retrieverを選択して使用します。
このときAgentは「画像認識」というクエリをCSV Retrieverに入力して、最も関連が高い、画像分類で用いたことのあるImageClassifierXというモデルについて記述されたチャンクを取得します。
Agentは最終的に「画像認識に使えそうなモデルとしてはImageClassifierXというモデルがあります。」という回答を生成します。
作成したシステムの動作
以下では作成したシステムに質問を入力して、 上手く社内ノウハウを検索ができたいくつかの例を示します。
1. 用途を指定したモデルの検索
システムに「社内のノウハウに姿勢推定に使えそうなモデルはありますか。」という質問を入力してみました。そのときの回答(左)とAgentの内部的な振る舞い(右)について以下に示します。
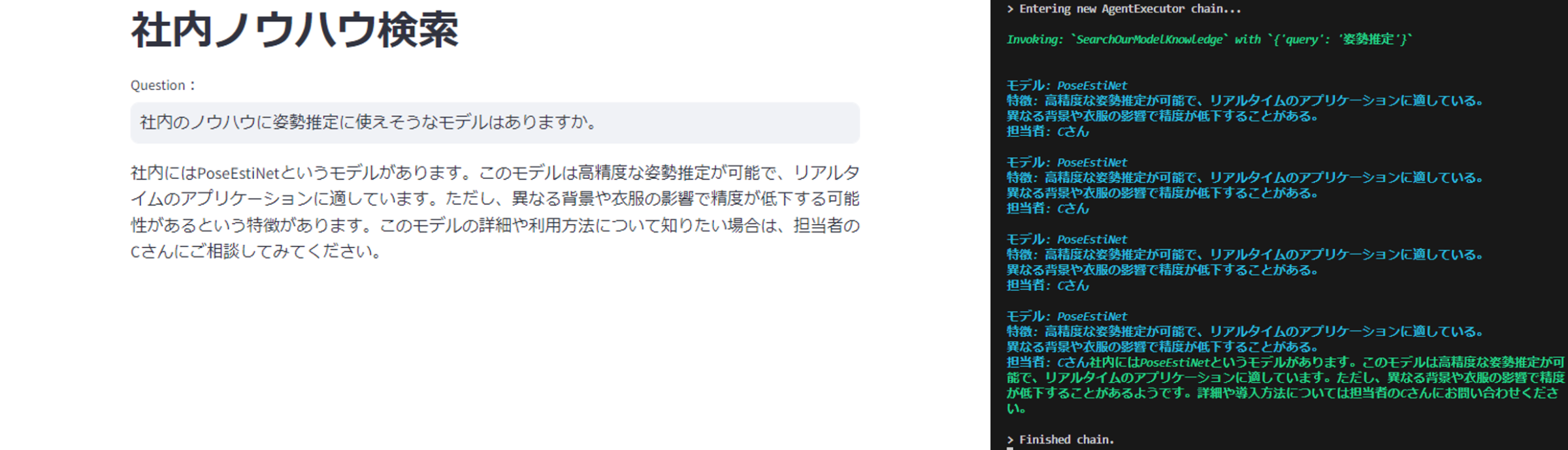
AgentはまずCSV Retrieverに「姿勢推定」というクエリを入力することで、PoseEstiNetという架空の姿勢推定モデルのチャンクを取得していることがわかります。
そして、Agentは取得したPoseEstiNetの情報を利用して、しっかりと社内ノウハウを考慮した回答を生成できていることがわかります。
2. 複数のRetrieverを利用した検索
システムに「画像分類に使えそうなモデルはありますか。またそのモデルの詳細を教えてください。」という質問を入力してみました。
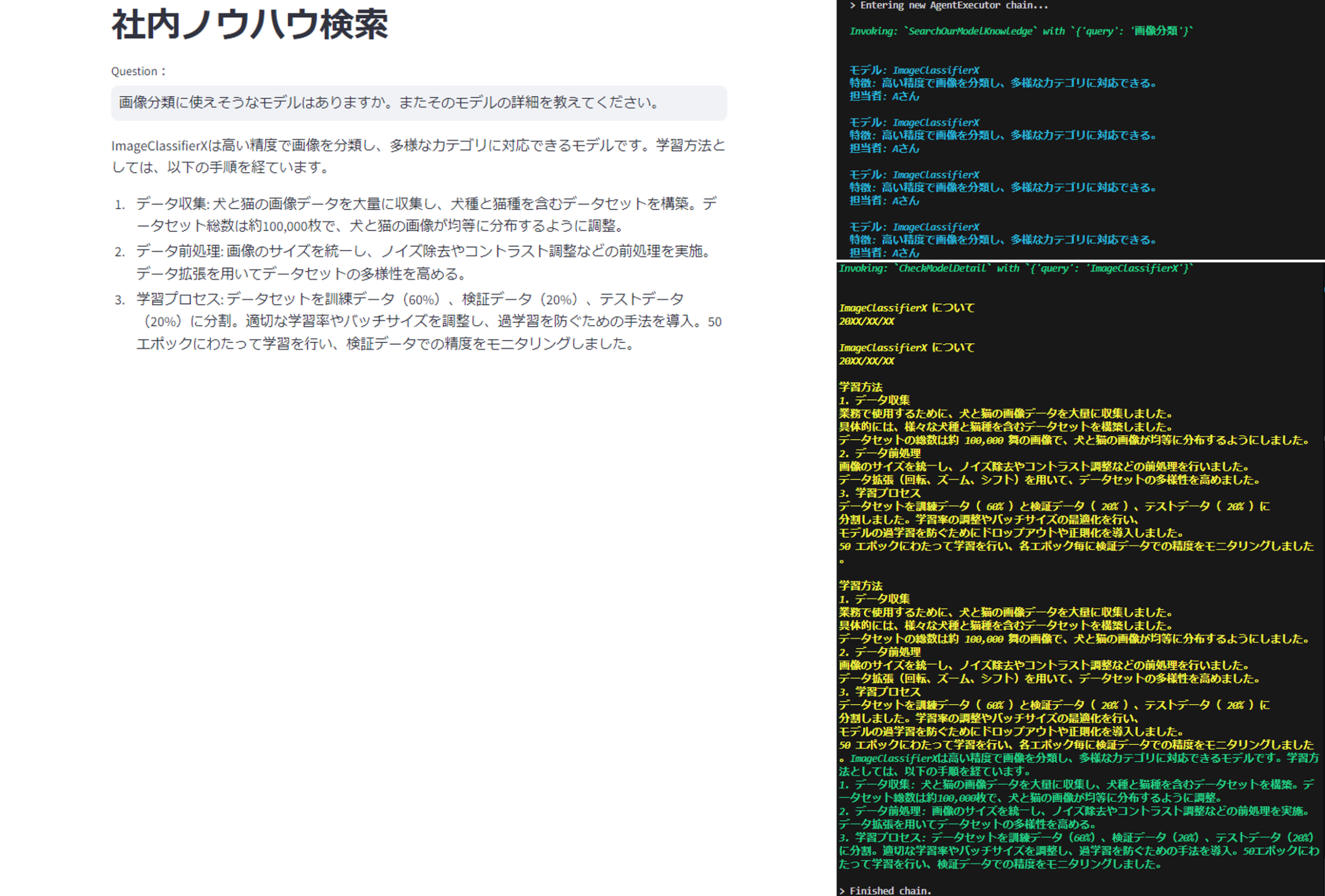
まずAgentは、姿勢推定モデルの検索時と同様に「画像分類」というクエリをCSV Retrieverに入力してImageClassifierXという画像分類モデルのチャンクを取得しています。
その後、AgentはさらにImageClassifierXについての詳細を知るためにPDF Retrieverから情報を取得しています。
そして最終的にAgentはこれらの情報を利用して回答を生成していることがわかります。
3. 二つのモデルの比較
システムに「時系列予測に使えそうなモデルはありますか。また、姿勢推定に使えそうなモデルはありますか。二つのモデルが存在した場合、それらの差異について記述してください。」という質問をしてみました。
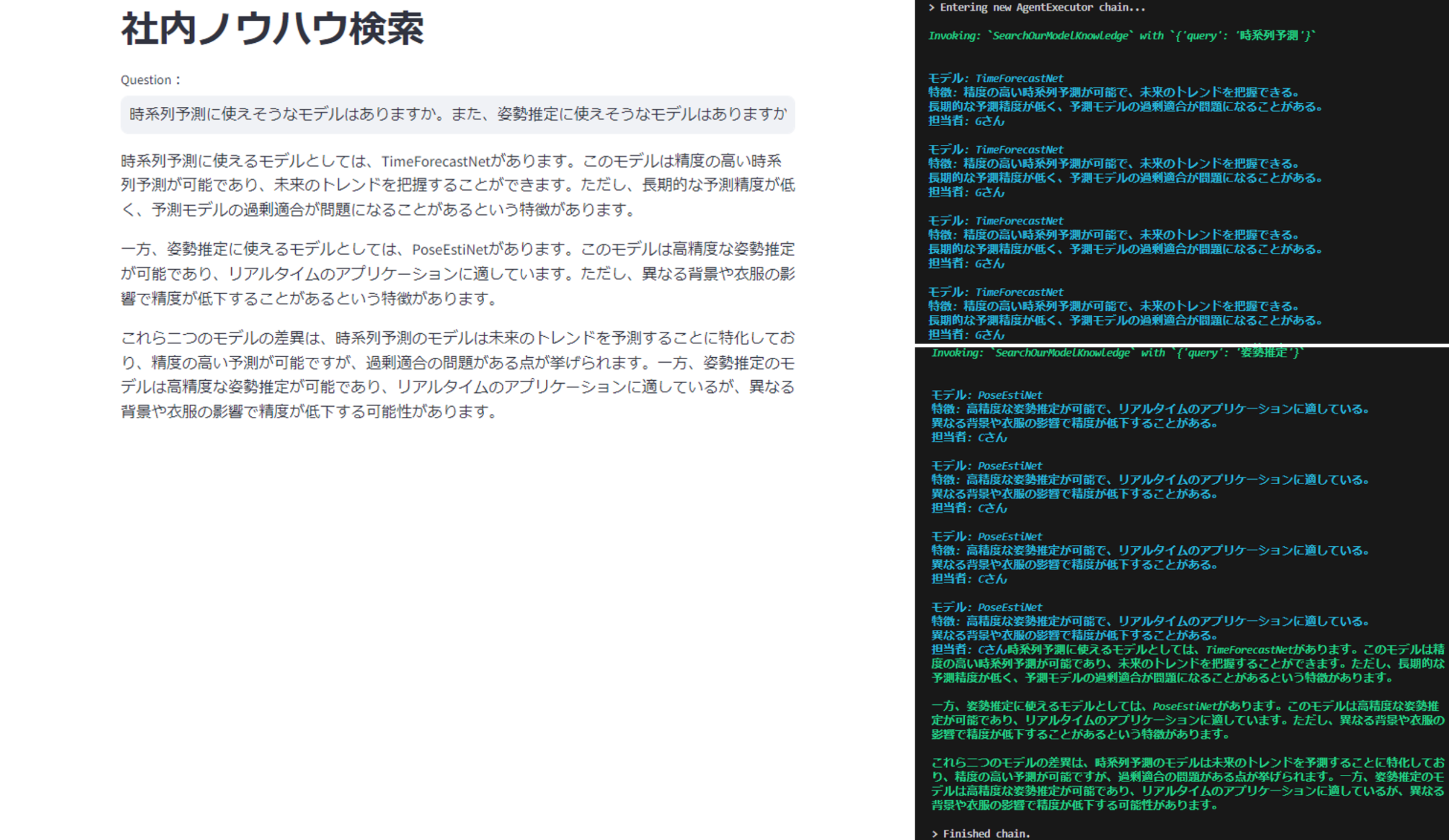
Agentは「時系列予測」というクエリでTimeForcastNetというモデルについてのチャンクを得たのち、「姿勢推定」というクエリでPoseEstiNetというモデルについてのチャンクを取得しています。
最終的に取得した二つのチャンクを利用して回答を生成していることがわかります。
作成したシステムの課題点
先ほどは作成したシステムが適切な回答を生成できていた例を示しました。一方、質問によっては、依然として人手による微調整が必要と感じる課題点もありました。
そのいくつかの課題点について以下に示します。
1. 質問方法で回答の精度が変化する

CSVファイルの中には存在しない「音声認識」に利用できそうなモデルをシステムに質問してみました。
このとき、ノウハウ中にそのようなモデルが「存在しなければ無いと回答してください」という一文を付加することで、システムは「音声認識に利用できるモデルは見つかりませんでした。」と正しく回答を行う事ができています。一方、一文を付加しなかった場合は姿勢推定やエンティティ抽出のAIモデルについての誤った回答を行ってしまっています。
このようにRetrieverで外部情報を検索する場合でも質問方法によって回答の精度が変化することがわかります。 精度の高い検索システムを作成するためには、質問のテンプレートを用意しておくなど設計側の調整が必要なことが考えられます。
2. Toolのdescriptionの記述がAgentの振る舞いに影響を与える
先ほど、Agentはdescriptionを参考にしてどのToolを利用するか判断していることを説明しました。
本システムにおいてCSV Readerは「社内にノウハウがあるモデルについて検索するために役立ちます。」
PDF Readerは「ImageClassifierXを用いた業務についての詳細を得るために役立ちます。」というdescriptionを設定していました。
このような条件下で「TimeForcastNetのノウハウはありますか。」と「TimeForcastNetの特徴や詳細についての情報はありますか。」という二つの質問をした場合の、それぞれの回答を比較してみました。

「TimeForcastNetのノウハウはありますか。」と質問した場合、システムはCSV Retrieverを利用して正しい回答を生成できていることがわかります。
一方、「TimeForcastNetの特徴や詳細についての情報はありますか。」と質問した場合、システムはPDF Retrieverを利用してしまい、その詳細はないということを回答しています。
上記の例では、質問に「ノウハウ」と「詳細」のどちらが含まれているのかで選択するToolが変化していると考えられます。
このように、Agentによって適切なToolが適切なタイミングで使用されるかはdescriptionの記述に依存していることがわかります。
従って、その記述には慎重な設計が必要であることが考えられます。
また上記の例から、本システムで用いたPDF RetrieverのdescriptionについてImageClassifierXの部分を書き換えて複数のRetrieverを用意した場合に、
Agentが正しいToolを選択可能であるかは検証の余地があると考えられます。
3. その他
観察された点以外にも、各種パラメータを設計する課題もあります。
例えば、Retrieverは外部情報の文書をいくつかのチャンクに分割することを説明しました。
このチャンク分割を改行、句点、ピリオドなどどのタイミングで行うのか、またチャンク間でどれほどのオーバーラップを許容するのかといったパラメータは設計時に決定する必要があります。
この分割方法によっても回答の精度が変化することが予想されます。
まとめ
本記事では、LangChainを活用してLLMを用いた社内ノウハウ検索システムを構築しました。
AgentやRetrieverの組み合わせにより、自然言語による質問に対して柔軟に対応できる仕組みを実現しています。
一方で、回答の精度は質問形式やToolの選択に依存する部分があり、さらなる精度向上のためには人手の微調整が必要だということがわかりました。
最後に
私たちのTech Blogを最後までお読みいただき、ありがとうございます。
私たちのチームでは、AI技術を駆使してお客様のニーズに応えるため、常に新しい挑戦を続けています。 最近では、受託開発プロジェクトにおいて、LLM(大規模言語モデル)を活用したソリューションの開発ニーズが高まっております。
新卒、キャリア募集しています!
AI開発経験のある方やLLM開発に興味のある方は、ぜひご応募ください。あなたのスキルと情熱をお待ちしています。
自動運転/先進運転支援システム(AD / ADAS)、医療機器、FA、通信、金融、物流、小売り、デジタルカメラなど、組込み機器やIoT、Webシステムなど様々なソフトウェア開発を受託しており、言語やOS、業務知識の幅を広げることが可能です。また、一次請けの案件が多く上流工程から携わることができます。客先常駐でも持ち帰りでも、Sky株式会社のチームの一員として参画いただきますので、未経験の領域も上司や仲間がサポートします。
