

音声認識とは「人の言葉をコンピューターが聞き取り、理解し、行動する」技術です。一般的には「音声認識」=「音声を文字に変える技術」を指すこともありますが、これだけでは「聞き取り」に留まります。
「理解し」「行動する」という点を踏まえて、音声認識と位置付けし、ご紹介していきたいと思います。
まずは音声認識を以下の4つの技術領域に分類していきます。
| 対話処理技術 |
|---|
| 音声の入出力、および、変換処理に関わる技術です。OSに応じた音声入出力ライブラリ制御、入力音声のノイズ除去、音声→文字への変換、音声区間の検出、文字→音声へ変換、音声による起動制御等の技術が属します。 |
| 音響処理技術 |
|---|
| ユーザーの発話内容から次のアクションを導き出し実行する技術です。認識辞書、クライアント情報管理、意図解釈、意図情報管理を用いて対話判断を行い、判断結果に応じた実行制御を行う技術であり、音声認識ユースケース実現の根幹部分を担う領域です。 |
| ソリューション制御技術 |
|---|
| 3rdベンダー提供の音声認識ソリューションを制御する技術です。各ソリューションのポーティング、音響/対話制御、データ管理等の技術が属します。Onboard/Offboardともに数多く存在しており、性能/構成等が異なりますので、実現したいサービスに応じた選定が必要です。 |
| 性能改善技術 |
|---|
| 音声認識の性能改善に関する技術です。認識率改善、パフォーマンス改善に関わる技術が属します。音声認識にとって利便性は最重要要素であり、性能改善技術は必須となります。 |
今回は「音響処理技術」の中の「音声変換」について触れていきたいと思います。
「音声変換」とは文字の通り、音声をテキストに変換することを指します。一般的には、ASR(Automatic Speech Recognition)とも呼ばれます。
ASRの流れとして、まずは発話と終話の検知を行います。この技術は、VAD(Voice Activity Detection)と呼ばれ、音声データから発話区間のデータを取り出します。
次に取り出した音声データを入力として、声の情報と言語の情報を組み合わせながら、発話された音(波)を音素と呼ばれる音の最小単位に変換します。
ここで音素に変換するために、音響モデルと言語モデルと呼ばれるモデルを使用します。
音響モデルには、言語の周波数成分のパターンが定義されています。このモデルと発話された音声の音を比較して、どの音素に近いかを判定します。
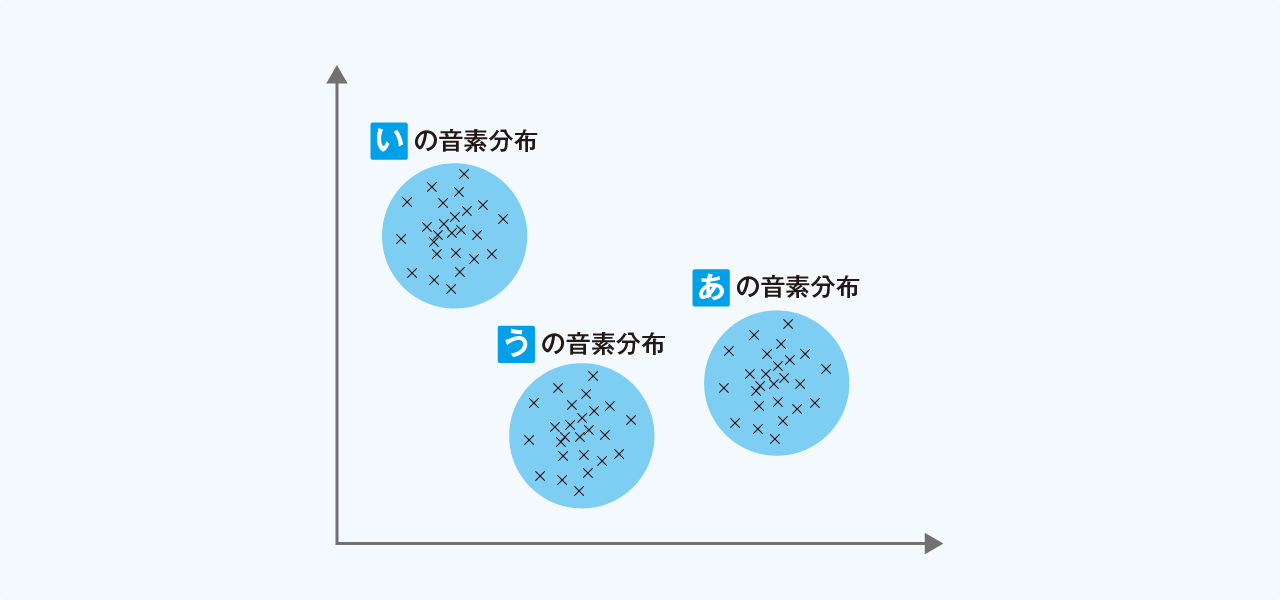
言語モデルは「大量の言語テキストを統計処理したもの」です。
次にどのような音素がきそうか予測するために使用し、文字列や単語列が文法的に適切なかどうかを判定します。
| 第1語 | 第2語 | 統計 |
|---|---|---|
| きょう | の | 19.0% |
| は | 15.0% | |
| が | 8.0% | |
| あ | 0.5% |
こうして変換されたテキストデータを後工程である、対話処理のインプットとしていく流れとなります。
昨今では準備されているASRを利用することが多いですが、仕組みを知ることで、認識率に対するチューニング等にも役立つことは多いと思います。
その他の技術領域に対する仕組みも今後ご紹介していきます。
