

2022年にOpenAI社がChatGPTを公開して以降、生成AIは一大ムーブメントとなり、企業で実証実験を行ったり、実際に導入されたりする事例が増えてきました。
この流れは、GPTやClaude、Geminiといったクローズドな大規模言語モデル(LLM)が、Azure、AWS、GCPといったクラウドサービスでAPIとして使いやすく整備されていることが大きな要因として挙げられます。
ローカルLLMとクラウドLLM
話は少し変わりまして、ローカルLLMとクラウドLLMについてお話しいたします。 ローカルLLMは、オープンなLLMモデル(例えばMeta社のLlama)を自社で管理する環境に実装するLLMを指します。 また、クラウドLLMは、GPTやClaude、GeminiといったクローズドなモデルをAzure、AWS、GCPといったクラウド上で提供されるLLMを指します。
クラウドLLMのメリットとデメリット
クラウドLLMは圧倒的な計算リソースを武器に巨大なパラメータ数で学習され、汎用的かつ高精度なモデルをAPIから気軽に使用することが可能です。
一方で、データがクラウドサービスに曝されることや、モデルがクラウド事業者の管理下に置かれてブラックボックスになってしまう面もあります。 自社のサービスの根幹を成す部分をブラックボックスなAIに任せることは、安全性の面でリスクがあるとも言えます。
ローカルLLMのメリットとデメリット
ローカルLLMでは、データやモデルを管理下に置けることがメリットとなります。
一方で、クローズドな大規模言語モデルが持つ巨大なパラメータ数を扱うのは計算リソースの面で非常に難しく、汎用かつ高精度なモデルの実現やローカル環境への実装は現実的ではありません。
ローカルLLMのモデルを業務に適合させる
前述したように、巨大なパラメータ数のモデルを汎用的に使えるようローカルLLMとして扱うのは現実的ではありません。
一方で、巨大なパラメータ数ではないモデルを、継続事前学習やファインチューニングを用いることで、 日本語が得意でユースケースに即したモデルに特化させるという戦略を取ることも可能になってきています。
ローカルLLMを支えるライブラリ
ローカルLLMの環境を構築する際に、キーとなるライブラリがllama.cppです。このライブラリは、CPUおよびGPUの任意のデバイスで最適化された状態で動作が可能で、CPUとGPUのメモリを併用した動作も可能です。LLMはメモリ使用量が大きいため、GPUメモリで不足する分をCPUメモリで補いながら高速な動作が可能です。
また、GGUFというツールで量子化したモデルを使用することで、メモリ使用量の削減も可能です。
Sky株式会社における取組
弊社では2017年からDeep Learningの社内検証および受託検証に取り組んでおり、2023年からは生成AIの検証に取り組み始めました。クライアント・システム開発事業部では受託開発を本業としており、AIチームにおいては生成AIの社内検証、お客様側の受託検証(PoC)やシステム化対応の受託開発に取り組んでおります。
弊社ではクラウドLLM、ローカルLLMのどちらにも対応しており、LLMやマルチモーダル対応のLLMをローカル環境に構築したり、 OSSのローコードAIプラットフォームDifyを用いた検証も実施しております。
以下は検証用に社内で作成したLLM、マルチモーダル対応のLLMアプリケーションをローカル環境で構築した例です。 GUIにStreamlit(Pythonを使用して簡単にWebアプリケーションを作成するためのオープンソースフレームワーク)を使用しています。
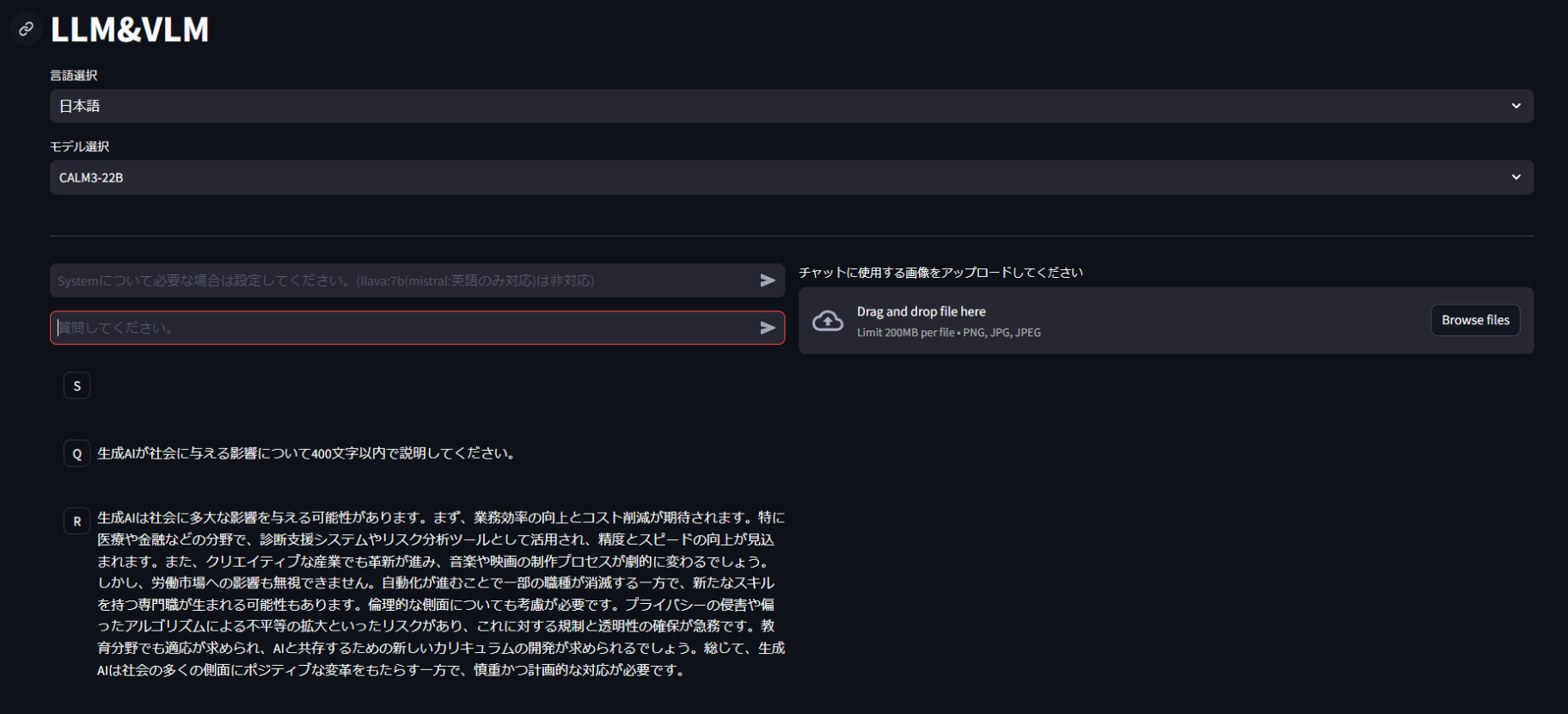
LLM
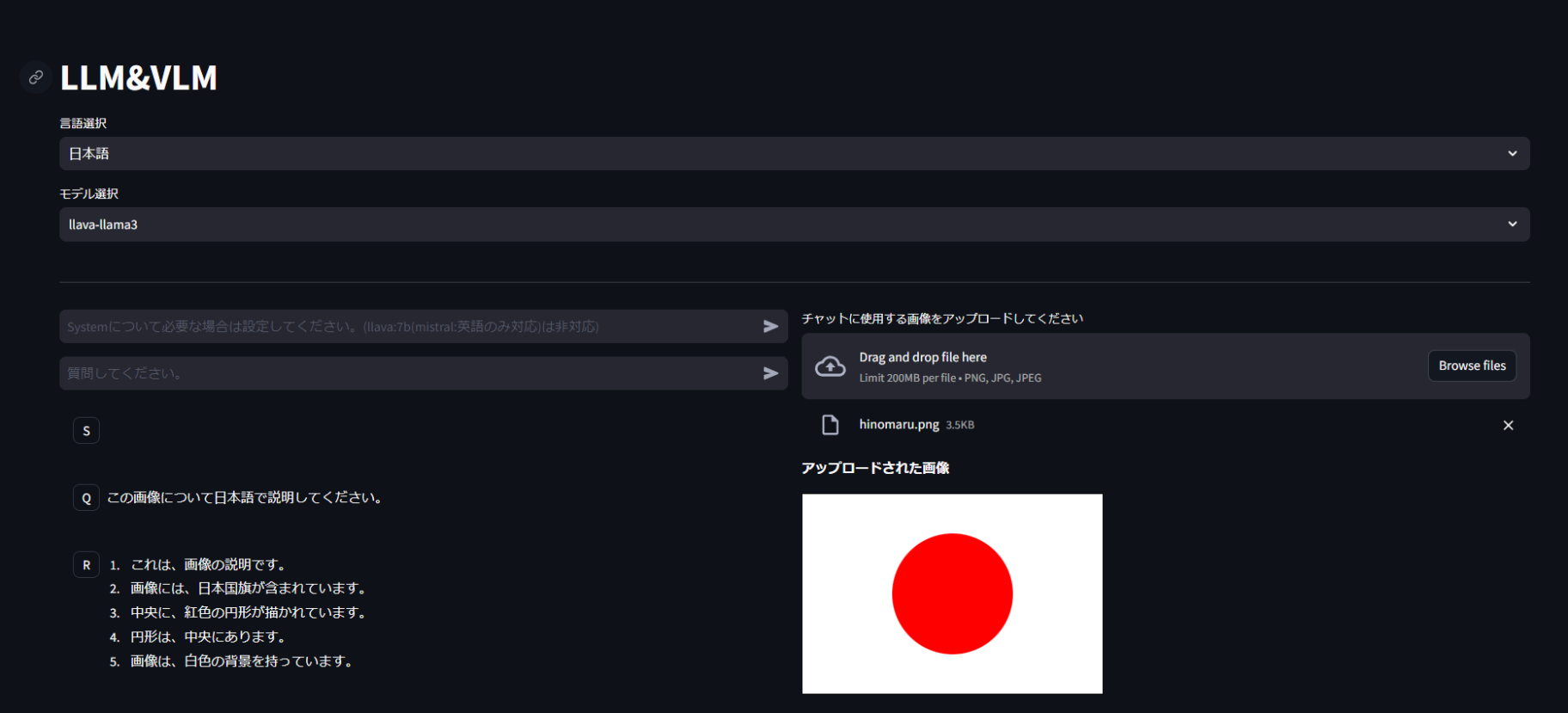
マルチモーダル対応のLLM
最後に
私たちのTech Blogを最後までお読みいただき、ありがとうございます。
私たちのチームでは、AI技術を駆使してお客様のニーズに応えるため、常に新しい挑戦を続けています。 最近では、受託開発プロジェクトにおいて、LLM(大規模言語モデル)を活用したソリューションの開発ニーズが高まっております。
新卒、キャリア募集しています!
AI開発経験のある方やLLM開発に興味のある方は、ぜひご応募ください。あなたのスキルと情熱をお待ちしています。
自動運転/先進運転支援システム(AD / ADAS)、医療機器、FA、通信、金融、物流、小売り、デジタルカメラなど、組込み機器やIoT、Webシステムなど様々なソフトウェア開発を受託しており、言語やOS、業務知識の幅を広げることが可能です。また、一次請けの案件が多く上流工程から携わることができます。客先常駐でも持ち帰りでも、Sky株式会社のチームの一員として参画いただきますので、未経験の領域も上司や仲間がサポートします。
