

業務でAIモデルの検索を行う機会があるため、DifyというオープンソースのLLM(大規模言語モデル)アプリケーション開発プラットフォームを用いて、論文検索自動化を実施してみました。Difyのワークフロー機能を用いて作成しています。(所要時間は2h程度)
ワークフローで実施している処理は以下になります。
処理の流れ
検索ワードの入力 ー DuckDuckGoで論文ID検索 ー arXivから内容取得 ー LLMで論文内容要約 ー 結果出力
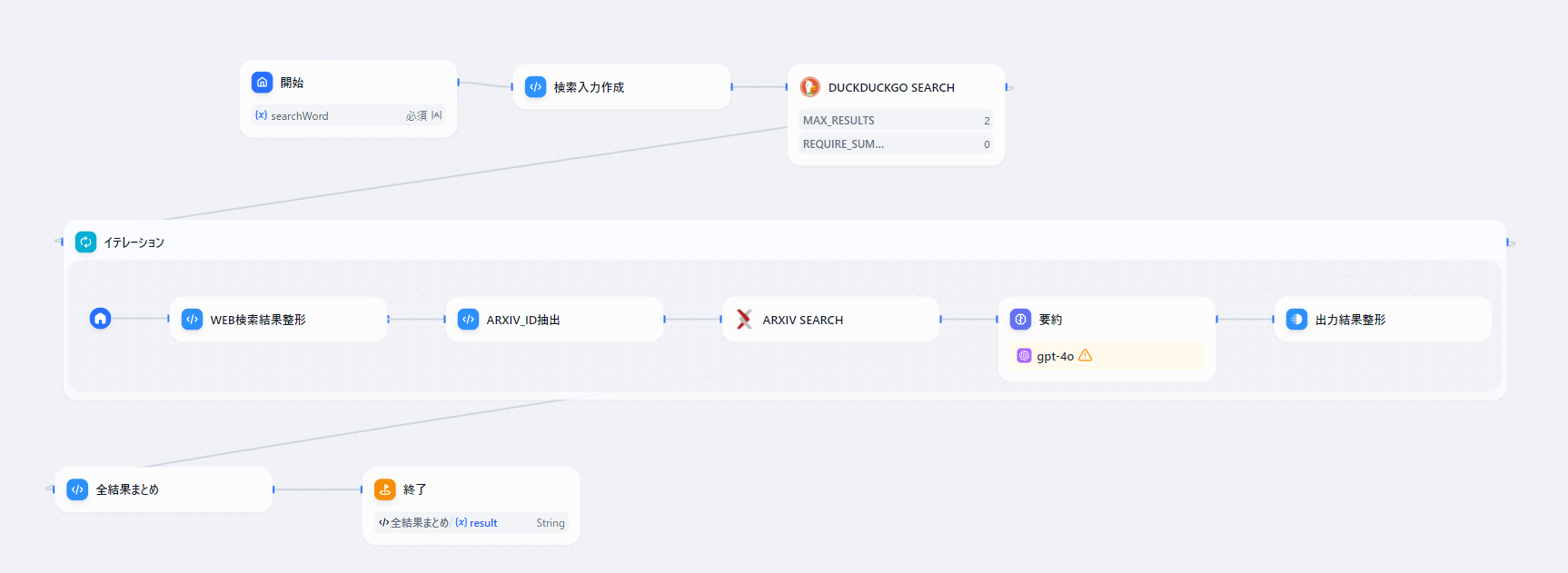
アプリ動作例
検索ワードに「transformer introduction」と入れてみると……
2件(検索件数はworkflow内のDuckDuckGo設定値で変更できます)の検索結果を元に、以下のように論文内容をまとめてくれます!
↓出力結果
検索ワード:transformer introduction
----------------------
web検索結果
No.1
タイトル: [2304.10557] An Introduction to Transformers - arXiv.org
リンク: https://arxiv.org/abs/2304.10557
概要: View a PDF of the paper titled An Introduction to Transformers, by Richard E. Turner. The transformer is a neural network component that can be used to learn useful representations of sequences or sets of data-points. The transformer has driven recent advances in natural language processing, computer vision, and spatio-temporal modelling.
arxiv検索結果
Published: 2024-02-08
Title: An Introduction to Transformers
Authors: Richard E. Turner
Summary: The transformer is a neural network component that can be used to learn
useful representations of sequences or sets of data-points. The transformer has
driven recent advances in natural language processing, computer vision, and
spatio-temporal modelling. There are many introductions to transformers, but
most do not contain precise mathematical descriptions of the architecture and
the intuitions behind the design choices are often also missing. Moreover, as
research takes a winding path, the explanations for the components of the
transformer can be idiosyncratic. In this note we aim for a mathematically
precise, intuitive, and clean description of the transformer architecture. We
will not discuss training as this is rather standard. We assume that the reader
is familiar with fundamental topics in machine learning including multi-layer
perceptrons, linear transformations, softmax functions and basic probability.
LLM要約結果
---
### イントロダクション
#### 1. はじめに
- トランスフォーマー(Transformer)は、自然言語処理(NLP)、コンピュータビジョン、および空間時間モデリングなどの分野で最近の進歩をもたらしたニューラルネットワークコンポーネントです。
- この論文では、数学的に正確で直感的かつ清潔なトランスフォーマーのアーキテクチャの説明を提供することを目指しています。
- トレーニング手法については触れないが、基本的なトピック(例えば多層パーセプトロン、線形変換、ソフトマックス関数、および基本的な確率)に慣れていることを前提としています。
#### 2. トランスフォーマーの概要
- トランスフォーマーはシーケンスやデータポイントのセットから有用な表現を学習することができます。
- NLPにおけるBERT、GPTなどのモデルの基盤となっています。
- トランスフォーマーの構成要素についての説明が不正確または一貫性がないことが多いため、明確な数学的説明と直感的な理解を提供します。
### 本文
#### 3. Transformer Architecture
- Input Embedding:
- 各トークンに対して固定サイズのベクトル埋め込み(Embedding)を付与します。
- Positional Encoding:
- シーケンスの順序情報を保持するためのポジショナルエンコーディングを追加します。
- 時間的な位置や空間的な位置に関する情報が含まれます。
- Multi-Head Attention Mechanism:
- 各入力シーケンスから複数の情報を抽出するためのメカニズムです。
- 異なる注意ヘッドが並列に動作し、情報の相互作用を促進します。
- Feed Forward Network:
- マルチヘッドアテンションの出力を完全に接続された層に入力し、非線形変換を行います。
- Output Layer and Normalization Layers:
- ソフトマックス関数を用いて最終出力を取得し、正規化レイヤーを追加してモデルを安定させます。
#### 4. Mathematical Description
- Input Embedding and Positional Encoding:
- \( E_{\text{in}} \): 入力埋め込み行列(固定サイズ)。
- \( e_i \): 各トークンの埋め込みベクトル(\(\mathbb{R}^d\))。
- \( PE_{\text{pos}}(pos) = \text{sin}(pos/10000^{\frac{2}{d}}) \) のように、位置情報を含むエンコーディング。
- Multi-Head Attention Mechanism:
- 各ヘッドの出力を結合して最終的な注意出力を取得します。
- Q, K, V行列を用いて注意重みを計算し、スケーリングと和を計算する。
- Feed Forward Network:
- 全接続層(Fully Connected Layer)を適用して非線形変換を行います。
#### 5. Conclusion
- この論文ではトランスフォーマーの基本的なアーキテクチャを詳細に説明しました。
- 数学的記述を通じて、直感的な理解と設計の選択の背景を提供しました。
- トレーニング手法については触れていませんが、他の文献を参考にしてください。
---
### 最終結果:
1. イントロダクション
- Transformerの概要とその意義について紹介しています。
2. Architecture
1. Input Embedding
- 各トークンに対して固定サイズのベクトル埋め込みを提供します。
2. Positional Encoding
- シーケンスの順序情報を保持するためのポジショナルエンコーディングを追加します。
3. Multi-Head Attention Mechanism
- 各入力シーケンスから複数の情報を抽出するためのメカニズムで、異なる注意ヘッドが並列に動作します。
4. Feed Forward Network
- マルチヘッドアテンションの出力を完全に接続された層に入力し、非線形変換を行います。
5. Output Layer and Normalization Layers
- ソフトマックス関数を用いて最終出力を取得し、正規化レイヤーを追加してモデルを安定させます。
3. Mathematical Description
1. Input Embedding and Positional Encoding
- \( E_{\text{in}} \): 入力埋め込み行列(固定サイズ)。
- \( e_i \): 各トークンの埋め込みベクトル(\(\mathbb{R}^d\))。
- \( PE_{\text{pos}}(pos) = \text{sin}(pos/10000^{\frac{2}{d}}) \) のように、位置情報を含むエンコーディング。
2. Multi-Head Attention Mechanism
- 各ヘッドの出力を結合して最終的な注意出力を取得します。
- Q, K, V行列を用いて注意重みを計算し、スケーリングと和を計算する。
3. Feed Forward Network
- 全接続層(Fully Connected Layer)を適用して非線形変換を行います。
4. Conclusion
- この論文ではトランスフォーマーの基本的なアーキテクチャを詳細に説明しました。
- 数学的記述を通じて、直感的な理解と設計の選択の背景を提供しました。
---
### 箇条書き結果:
1. イントロダクション: Transformerの概要とその意義について紹介しています。
2. Architecture:
1. Input Embedding: 各トークンに対して固定サイズのベクトル埋め込みを提供します。
2. Positional Encoding: シーケンスの順序情報を保持するためのポジショナルエンコーディングを追加します。
3. Multi-Head Attention Mechanism: 各入力シーケンスから複数の情報を抽出するためのメカニズムで、異なる注意ヘッドが並列に動作します。
4. Feed Forward Network: マルチヘッドアテンションの出力を完全に接続された層に入力し、非線形変換を行います。
5. Output Layer and Normalization Layers: ソフトマックス関数を用いて最終出力を取得し、正規化レイヤーを追加してモデルを安定させます。
3. Mathematical Description:
1. Input Embedding and Positional Encoding: \( E_{\text{in}} \) 入力埋め込み行列(固定サイズ)、\( e_i \) 各トークンの埋め込みベクトル(\(\mathbb{R}^d\))、位置情報を含むエンコーディング。
2. Multi-Head Attention Mechanism: Q, K, V行列を用いて注意重みを計算し、スケーリングと和を計算する。
3. Feed Forward Network: 全接続層(Fully Connected Layer)を適用して非線形変換を行う。
4. Conclusion: この論文ではトランスフォーマーの基本的なアーキテクチャを詳細に説明しました。数学的記述を通じて、直感的な理解と設計の選択の背景を提供しました。
----------------------
web検索結果
No.2
タイトル: [2311.17633] Introduction to Transformers: an NLP Perspective - arXiv.org
リンク: https://arxiv.org/abs/2311.17633
概要: Introduction to Transformers: an NLP Perspective. Transformers have dominated empirical machine learning models of natural language processing. In this paper, we introduce basic concepts of Transformers and present key techniques that form the recent advances of these models. This includes a description of the standard Transformer architecture ...
arxiv検索結果
Published: 2023-11-29
Title: Introduction to Transformers: an NLP Perspective
Authors: Tong Xiao, Jingbo Zhu
Summary: Transformers have dominated empirical machine learning models of natural
language processing. In this paper, we introduce basic concepts of Transformers
and present key techniques that form the recent advances of these models. This
includes a description of the standard Transformer architecture, a series of
model refinements, and common applications. Given that Transformers and related
deep learning techniques might be evolving in ways we have never seen, we
cannot dive into all the model details or cover all the technical areas.
Instead, we focus on just those concepts that are helpful for gaining a good
understanding of Transformers and their variants. We also summarize the key
ideas that impact this field, thereby yielding some insights into the strengths
and limitations of these models.
LLM要約結果
---
### 1. 序論
Transformersは自然言語処理(NLP)の分野において、実験的な機械学習モデルとして支配的な存在となっています。この論文では、基本的な概念と最近の進歩を形成する技術に焦点を当てて、Transformersについて詳しく説明します。具体的には、標準的なTransformerアーキテクチャの紹介、いくつかのモデルの改良、および一般的な応用について取り上げます。また、Transformersやその関連の深層学習技術がどのように進化しているかを考慮し、全ての技術を網羅することはできませんが、理解を助けるための基本的な概念に絞ります。さらに、この分野における主要なアイデアを要約し、これらのモデルの強みと限界に関する洞察を提供します。
### 2. 基本的な概念とアーキテクチャ
Transformersは、アテンションメカニズムを使用して入力シーケンス全体を考慮に入れることができるモデルです。具体的には、セルフアテンション(自己注意)機構を用いて、各単語が他の単語にどれだけ関連しているかを計算し、その結果を用いて出力を生成します。これにより、文脈情報を効果的に捉えることができます。
### 3. 改良と技術
Transformersにはいくつかの改良点があります。例えば、BERT(Bidirectional Encoder Representations from Transformers)やGPT-2などのモデルでは、双方向の文脈を考慮に入れることで、より豊かな意味情報を提供します。また、RoBERTaなどのモデルでは、大規模なデータセットでのトレーニングとアテンションヘッダーの最適化が行われています。
### 4. 応用
Transformersは様々なNLPタスクに応用されており、例えば機械翻訳、テキスト要約、質問応答システムなどがあります。これらのモデルは、従来のRNNやCNNベースのモデルよりも高い性能を示しています。
### 5. 強みと限界
Transformersの強みには、長い文脈を効果的に扱えること、並列処理が可能であること、そして大規模なデータセットでのトレーニングが効果的であることなどがあります。一方で、弱みとしては計算コストが高いことや、特定のドメインでの汎用性が限られていることが挙げられます。
---
### 結果(箇条書き形式)
1. Transformersは自然言語処理において支配的なモデルである。
2. 基本的な概念としてセルフアテンション機構を使用し、文脈情報を効果的に捉える。
3. BERTやGPT-2などのモデルは双方向の文脈を考慮し、RoBERTaは大規模データと最適化を行う。
4. 応用範囲には機械翻訳、テキスト要約、質問応答システムなどがある。
5. Transformersの強みは長い文脈の扱い、並列処理、大規模なデータセットでのトレーニングであるが、計算コストやドメイン特化性が課題である。
---
### 追加のコメント
Transformersとその関連技術は急速に進化しており、常に新しい手法や改良が登場しています。そのため、全ての技術を網羅するのは困難ですが、基本的な概念と最近の進歩を理解することで、今後の研究や応用に役立てることができます。
## まとめ
Transformersは自然言語処理において非常に強力なツールであり、多くの応用分野で高い性能を示しています。この論文を通じて、その基本的な概念から最新の技術までを理解し、さらなる研究や実用化に役立ててください。
---
### 参考文献
[ここに参考文献リストを記載してください]
---
### 著者情報
Tong Xiao, Jingbo Zhu
---
----------------------
最後に
私たちのTech Blogを最後までお読みいただき、ありがとうございます。私たちのチームでは、AI技術を駆使してお客様のニーズに応えるため、常に新しい挑戦を続けています。最近では、受託開発プロジェクトにおいて、LLM(大規模言語モデル)を活用したソリューションの開発ニーズが高まっております。
新卒、キャリア募集しています!
AI開発経験のある方やLLM開発に興味のある方は、ぜひご応募ください。あなたのスキルと情熱をお待ちしています。
自動運転/先進運転支援システム(AD / ADAS)、医療機器、FA、通信、金融、物流、小売り、デジタルカメラなど、組込み機器やIoT、Webシステムなど様々なソフトウェア開発を受託しており、言語やOS、業務知識の幅を広げることが可能です。また、一次請けの案件が多く上流工程から携わることができます。客先常駐でも持ち帰りでも、Sky株式会社のチームの一員として参画いただきますので、未経験の領域も上司や仲間がサポートします。
