

テレビ放送設備は、デジタル化・IP化が進んでおり、これに伴いサイバー攻撃を受けて放送の継続への影響が出る危険性が高まっています。
実際にいくつかのテレビ局で、サイバー攻撃を受け、データが暗号化され正常に動作しなくなるという事案も発生しています。
テレビ放送を支えているマスタ設備には、Windowsマシンも構成に含まれますが、専用設備であるためアンチウィルスソフトの導入や、Windows Update等が実施できないという制約があったり、 Windows以外のマシンであるため、同様にエンドポイントセキュリティ対策ソフトが使えないという課題があります。
このような、特殊な端末で構成されるシステムでのネットワークに対して、AIによる監視を行うシステムを構築できないか、Sky株式会社と九州朝日放送株式会社様とで共同研究を行いました。
AIによる自己学習型ネットワーク統合監視概要
今回取り組んだ、ネットワーク統合監視の概要になります。
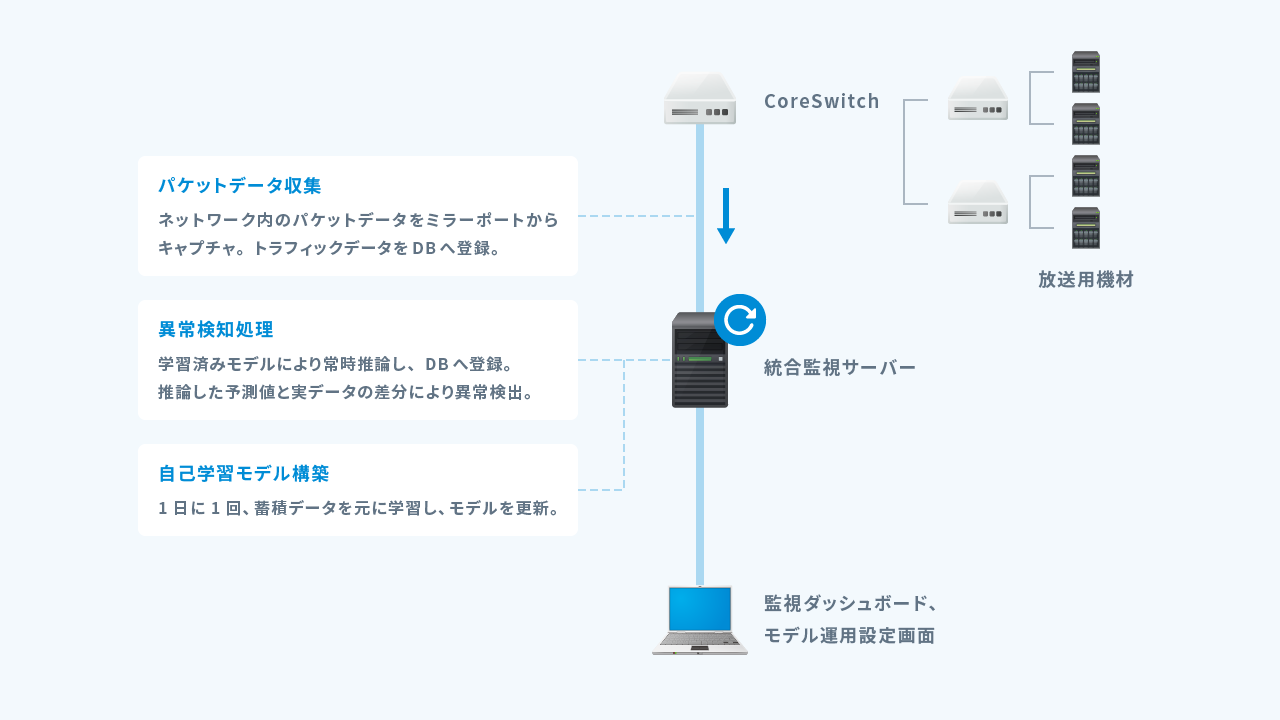
- 放送設備IPネットワークのコアスイッチからミラーパケットを取得し、時系列にデータ化してDBに収集。
- 収集したトラフィックデータを機械学習してモデル作成を継続的に行い、日々更新される学習済みモデルを使って、直近のトラフィックデータから異常傾向を検出。異常が確認された場合、管理者にメール送信。
- 管理者は管理画面を開き、受け取ったメールに記載されたモデルのノードを調査する。
AIモデル構築方法
放送設備内のコアスイッチのミラーリングポートを使ってパケットをキャプチャーし、実際のネットワークトラフィックが、どのような傾向になっているのかを調査しました。
その結果、機器ごとに通信データに特性がみられることがわかってきたため、特性別に分類を行い、それぞれどのような方法で異常検知するのか検討しました。最終的には、すべてのケースに対して同一の手法で異常検知するようにしました。
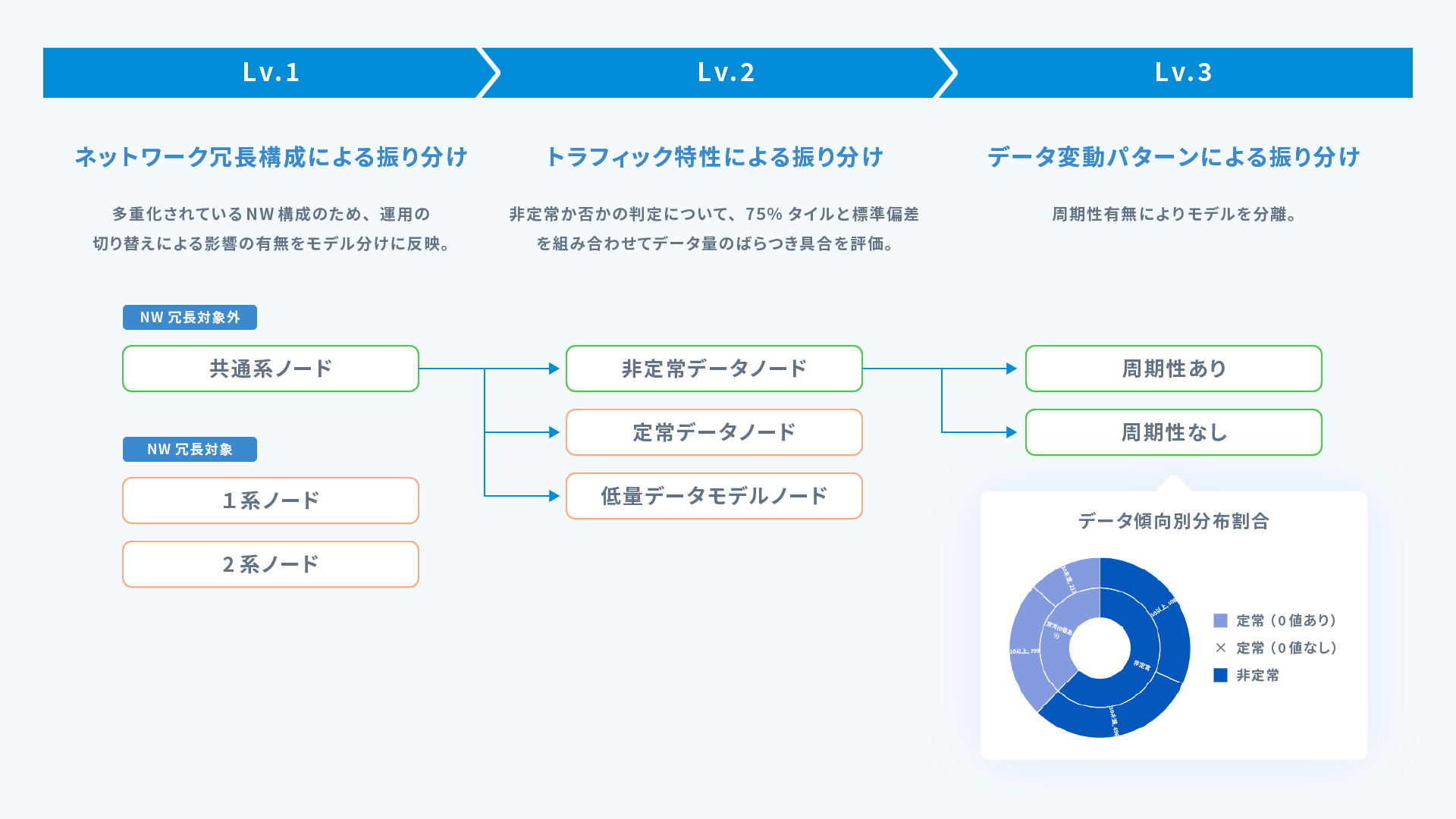
今回は、プロトコルレベルの解析までは行わずに、パケットデータの変動パターンにより、異常を検出するという手法を取りました。時系列データ予測値からの外れ値により異常判定するというアプローチとして、以下の方法が考えられます。
- 移動平均法や、AR / ARIMAなど自己再帰モデルによる予測値から外れ値を検出
- LSTMモデルによる予測値から外れ値を検出
短期的な時系列データであれば従来手法であるARIMAモデルが有効なのですが、放送設備の場合は曜日によるデータ量変動が存在します。
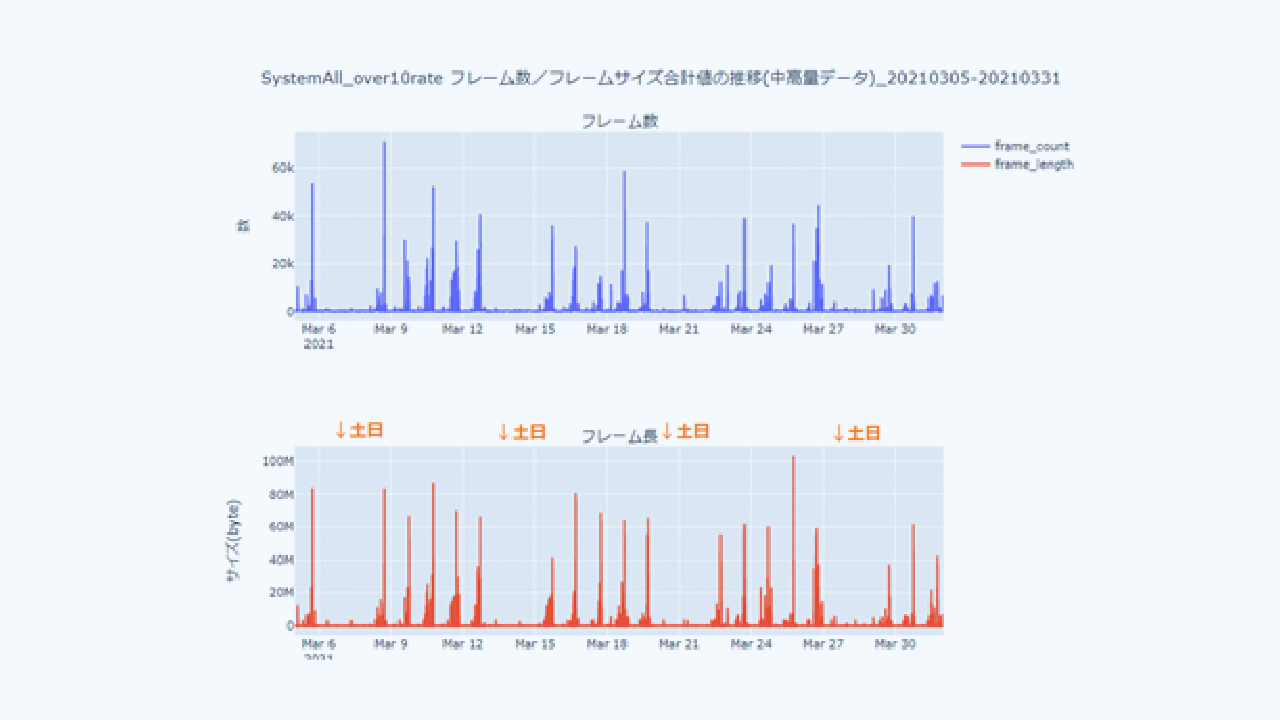
- 月曜日~金曜日は、翌日分の放送データを夕方に転送 / 登録する操作を行うために通信量が増える。
- 金曜は週末分も含めて対応するため、特に通信量が増える。
これらを考慮した予測を行いつつ、直近のデータ量を元にした異常検知を実現するため、過去2週間分のデータを使うことで曜日特性を取り入れようとしましたが、 ARIMAなどの従来手法は長期間データを使ったモデルへの対応が難しいことがわかりました。
LSTMによる時系列データ予測
ディープラーニングのモデルであるLSTM(Long Short Term Memory)を採用しました。LSTM は、RNN(リカレントニューラルネットワーク)の勾配消失問題を解消した再帰型ニューラルネットワークモデルです。 RNNに比べてLSTMは長期の時系列データの特徴を学習できるようになっているのが特徴です。

学習データのデータセットの作成方法
最長で過去2週間分のパケットデータを1分ごとにパケット数、パケットサイズの合計値に集約し、30分ごとにデータを学習データ、未来1分のデータを予測値に対するバリデーションデータとして使用するようにしました。
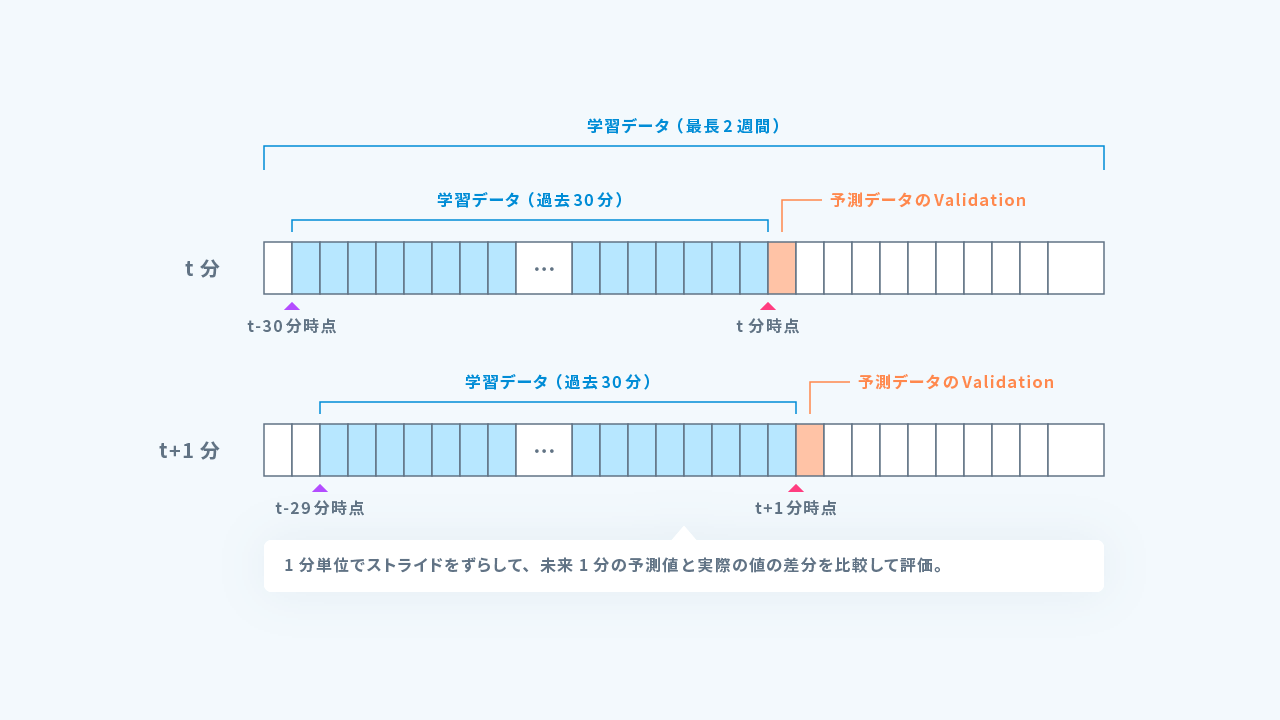
推論データのデータセットの作成方法と、推論方法
直近の60分のデータを取得し、学習同様に30分ごとに分割したデータを使って未来1分の予測を行う処理を1分ごとにずらして実施することにより、後半30分の予測値と実際のデータを比較することで、予測値との残差を評価しました。
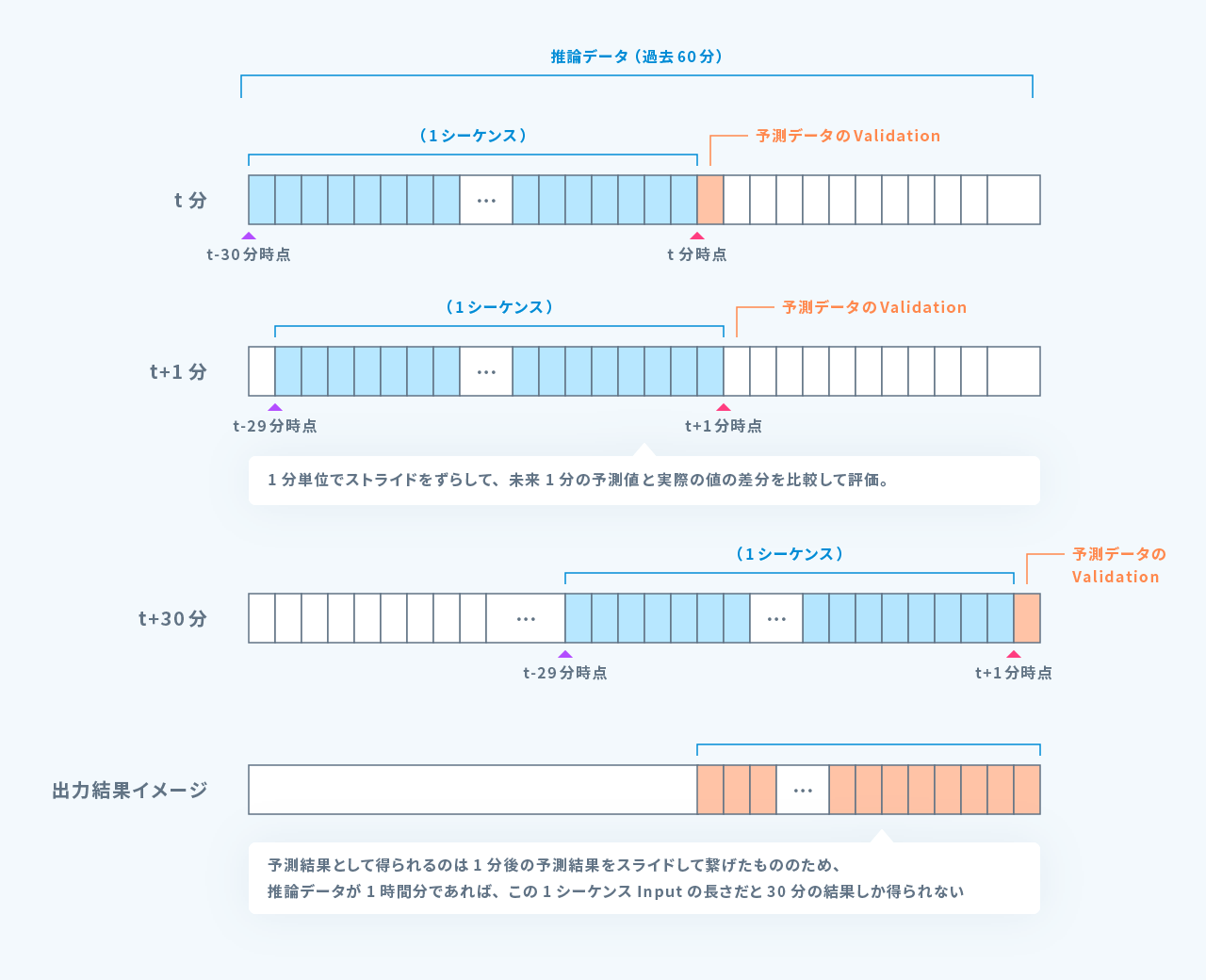
このように収集データを元に、任意の時間のデータを集約したデータセットを作る必要があったため、本取り組みでは時系列データベースを活用してデータを取り出すことができるようにしました。
実際のパケットデータが、予測値よりも大幅にかけ離れた値となっているところが検出されると、普段と異なるデータ変化がみられた箇所として、保守者へメールで知らせる仕組みを構築しました。
予測モデルを構築するにあたって、当初はパケットデータの波形予測がなかなかうまくできなかったのですが、活性化関数としてTanhshrinkを採用する等、いくつかの工夫を行うことで期待する結果が得られるようになりました。
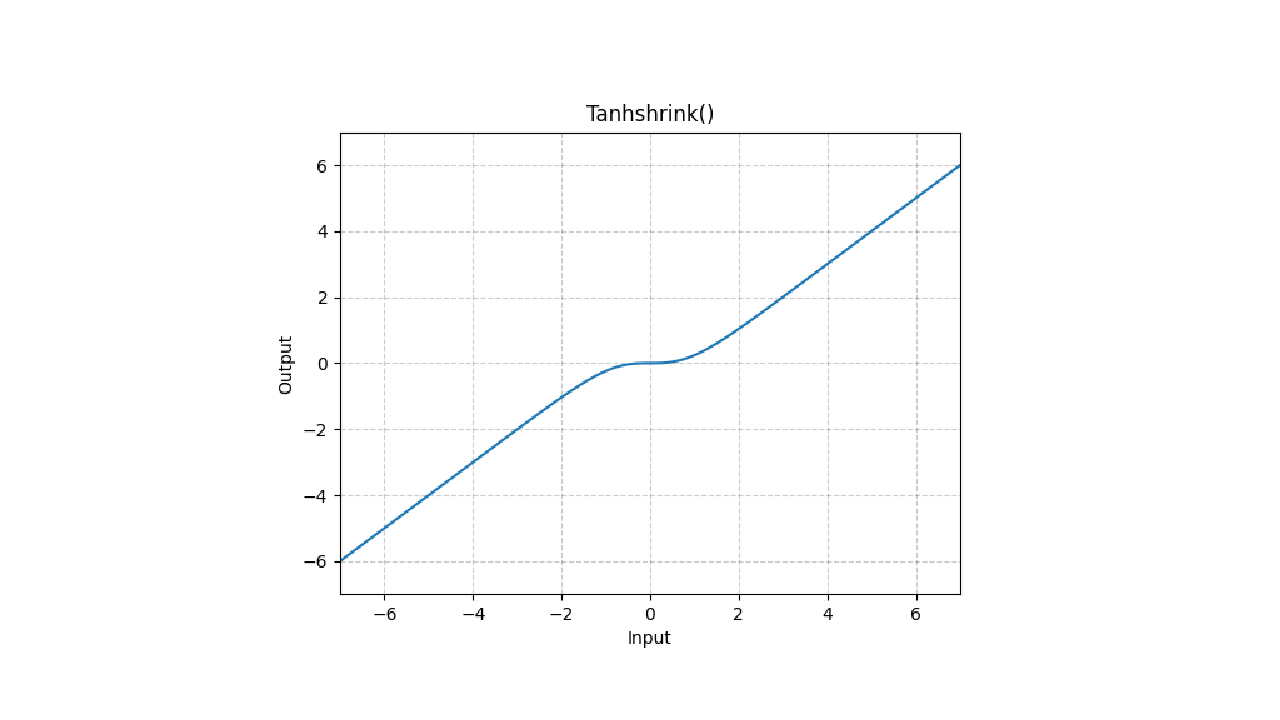
出典: https://pytorch.org/docs/stable/generated/torch.nn.Tanhshrink.html#torch.nn.Tanhshrink
モデル開発で苦労した点
モデル開発の段階では曜日ごとの特徴が適合できるモデルを目指すために、数週間以上のデータを集める必要があり、キャプチャーデータのサイズが大きくてデータのやり取りや前処理で苦労しました。 運用段階では再学習システムを構築し、データの収集と前処理、モデル学習と推論処理の一連の流れを自動化することができたことで、放送設備の機器入れ替えが行われた場合でも、しばらくすると自動的に通信パターンを学習することが可能になりました。
この時に開発した学習システムのモデル管理にはMLflowを活用しており、現在では他のAIモデル開発でも学習結果の管理をMLflowでのモデルトラッキングを導入して、効率よく精度改善が行えるようになっています。
まとめ
今回開発したシステムは、セキュリティインシデントを防止することはできないのですが、初期段階から何らかの異変をとらえることが可能となりました。 実際に発生したアラートは、機器故障やいつもと異なるオペレーションが原因であることがわかっていますが、これらを発見できる意味も大きいです。 時系列データ予測をディープラーニング手法で予測するノウハウと、AIモデル運用に必要となるMLOpsに必要な技術の知見も得ることができました。
