

業務でCUDAを用いた画像処理の高速化を行いました。その際に勉強したことをまとめました。 ここでは CUDA の基礎的な語句等について説明します。
CUDA とは
CUDA(Compute Unified Device Architecture)は、GPU を利用して汎用の並列計算を行うための開発環境で、NVIDIA社製GPUで汎用的な並列計算を行うためのプログラミング言語やコンパイラ、ライブラリなどで構成されています。
なぜGPUを使うと高速化できるのか
GPUが速いと言われる理由の1つは、コアの多さです。CPUのコア数は8~24コア程度ですが、GPUのコア(CUDAコア)は数千~数万コア搭載されています。これらのコアが並列に計算することで、CPUよりもはるかに速く計算することができます。 ただし、コア単体の性能はCPUの方が高いため、GPUで分岐処理などをさせると途端に遅くなります。したがって、GPUの計算能力を最大限に引き出すためには、GPUの特性を意識したコーディングや、十分に計算リソースを利用するためのチューニングが必要になります。
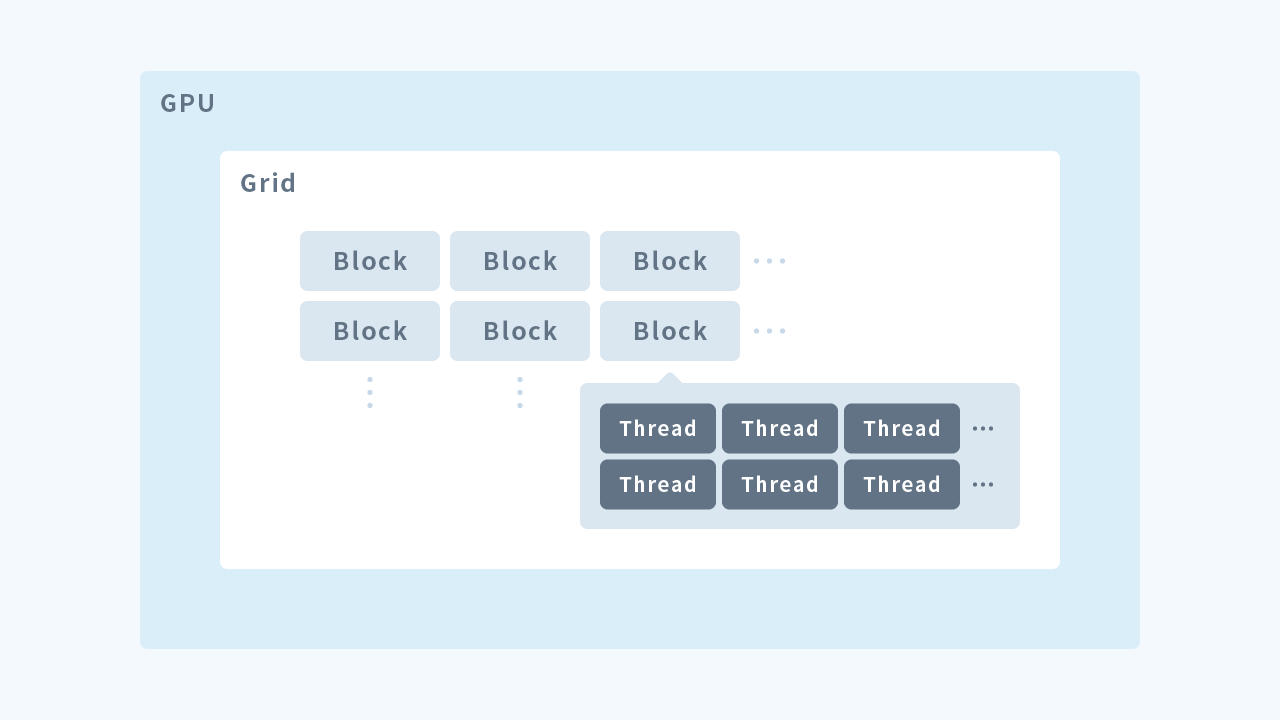
グリッド・ブロック・スレッド
CUDA を用いてGPU を用いた並列処理を行うとき、GPU 側では多数のスレッドが生成され、各スレッドがその処理を実行することで並列化を実現します。 GPUにおいて計算処理を行うカーネルは処理を行うスレッド、スレッドを束にしたブロック、ブロックを束にしたグリッドの三層構造となっており、GPU で処理を行うには、これらを指定してカーネルを実行する必要があります。
GPUメモリについて
GPU を使ったプログラムを作成する場合、メモリと一口に言っても、CPUのメモリとGPUのメモリの2種類があります。CPUのメモリをホストメモリ、GPUのメモリをデバイスメモリと呼びます。デバイスメモリには用途に応じたいくつかの種類があります。ここでは、使用頻度が高いと思われるグローバルメモリ、コンスタントメモリ、シェアードメモリについて説明します。
- グローバルメモリ:GPU 内で最も大容量かつ低速なメモリ
- 動的に確保するには cudaMalloc を使う
- 静的に確保するには __device__ 修飾子をつける
- 解放には cudaFree を使う
- コンスタントメモリ:GPU 側から書き換えられず、動的に割付できないため、定数用に確保する
- __constant__ で修飾して宣言
- cudaMemcpyToSymbol メソッドで初期化(指すのはシンボル)
- cudaGetSymbolAddress でアドレスに変換
- シェアードメモリ:同一ブロック内のスレッドが読み書きできるメモリで、高速 グローバルメモリからシェアードメモリにコピーして参照する
- __shared__ で修飾して宣言
CUDAプログラムの構成
CUDA C で記述したファイルの拡張子は cu で、*.cu 内には2種類の関数を定義できます。
- ホスト関数
- CPU 上で実行される
- GPU に対し、データ転送、GPU カーネル関数呼び出しを実行
- GPU カーネル関数
- GPU 上で実行される
- ホストプログラムから呼び出されて実行
- __global__ で修飾する必要がある(ホストから呼び出す)
- 戻り値は void である必要がある
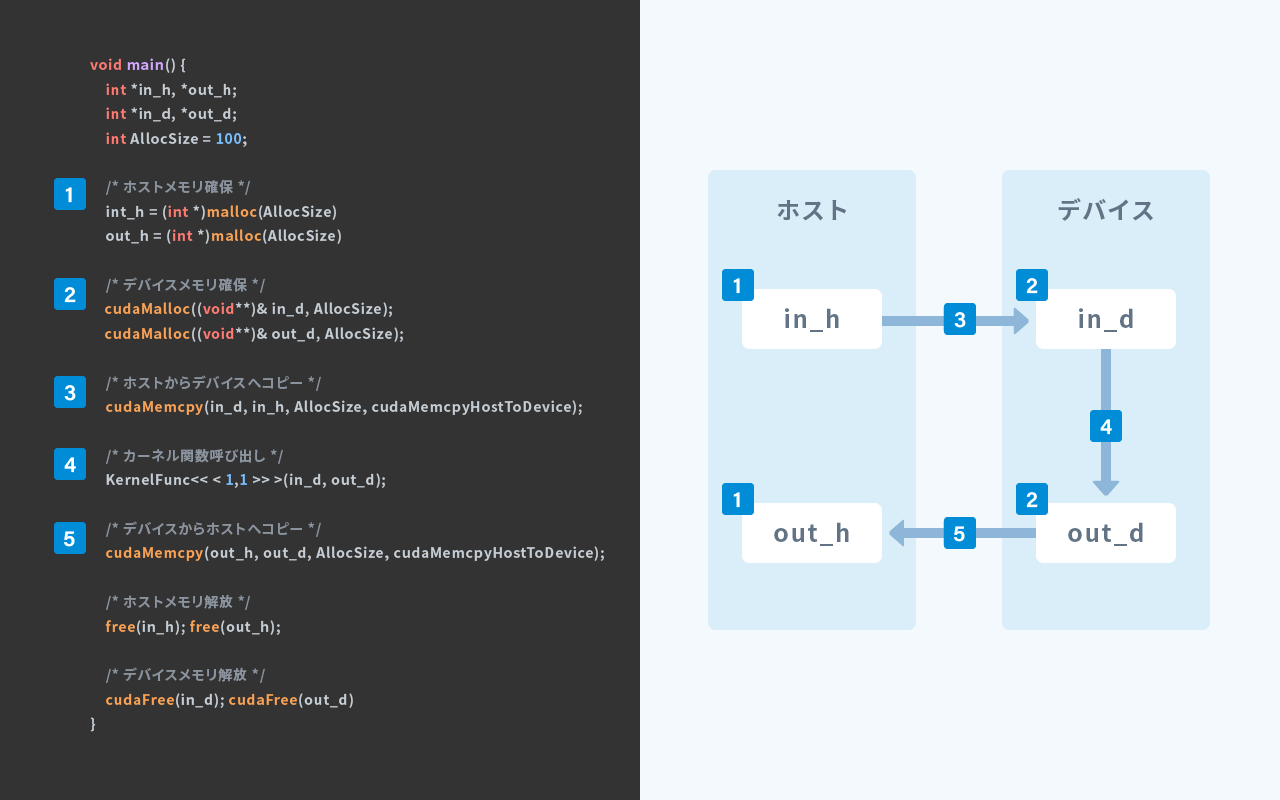
プログラムの流れ
ここでは、単純な CUDA プログラムの処理の流れを記述します。デバイスとホストのどちらにデータがあるかを把握しておくことが大切です。ホスト側でデバイスのメモリにアクセスすることはできませんし、逆にデバイス側でホストのメモリにアクセスすることもできません。
- ホストメモリを確保する
- デバイスメモリを確保する
- ホストメモリからデバイスメモリへデータをコピーする
- ホストからカーネル関数を実行する
- 実行結果をデバイスメモリからホストメモリへコピーする
模式図を以下に示します。 (図中のプログラムを実行しても動作しません。)
まとめ
CUDAを使用してプログラミングする際の基本的な事柄について説明しました。
