

「確率的データ構造とログ検索の高速化(1)」の続きです。
グラム分割
ある日のある端末のログファイルに対してブルームフィルターを作成し、検索キーワードが含まれていない場合は検索処理を効率的にスキップできるようにします。ブルームフィルターの処理で検索キーワードが含まれているかも、という結果が出た場合、擬陽性の可能性があることも踏まえてそのログファイルをきちんと検索してやらなければなりませんが、ブルームフィルターの処理でキーワードが含まれていないことが判明すれば、重い検索処理をスキップできます。
さて、実際にフィルターを作成する際には、ログのデータを一定のバイトごとに区切ってn-gramにして、そのn-gramをフィルターに登録していきます。検索の際には、検索キーワードを同じ一定のバイトで区切り、その結果のn-gramがフィルターに含まれているかを見てやります。
たとえばログの内容がabcdefghだったとして、4バイトごとにグラム化してやるなら、abcd, bcde, cdef, defg, efghというグラムができます。これらがブルームフィルターに登録されます。
そして、検索キーワードがbcdefだったとすると、グラムとしてはbcdeとcdefができます。これらのグラムはフィルターに登録されていることがすぐにわかるので、あとは実際にログを検索して確認します。
フィルターの転置
実際にフィルターの処理を高速に行うために、もう一工夫が必要になります。ある日の複数の端末のログに対してフィルターを作成してファイルにすると、素直にやれば以下のような並びになります(後の転置操作をわかりやすくするために色を付けています)。
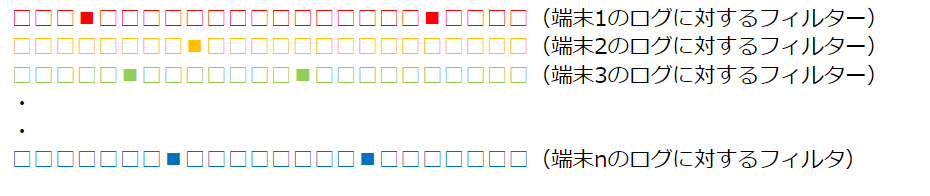
これに対して、検索しようとしたグラムのビットの並びが以下のようになったとします。
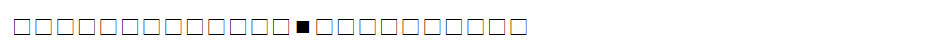
このビットの並びと、各端末のフィルターのビット列とANDをとって、ビットが立っていればその端末のログには検索しようとしたグラムが含まれている可能性があることになります。
ただ、このやり方だと各端末のフィルターの中身をすべて読まなければならなくなります。1つの端末の一日のログに対するフィルターのサイズをSKYSEA Client Viewでは128KBに設定しており(このサイズが大きいほど擬陽性が減ります)、ログ本体に比べればはるかに小さいものの、端末数が多くなるとそれなりに読み取りに時間がかかります。
そこで、フィルターのファイルの中身を縦横ひっくり返してやります。
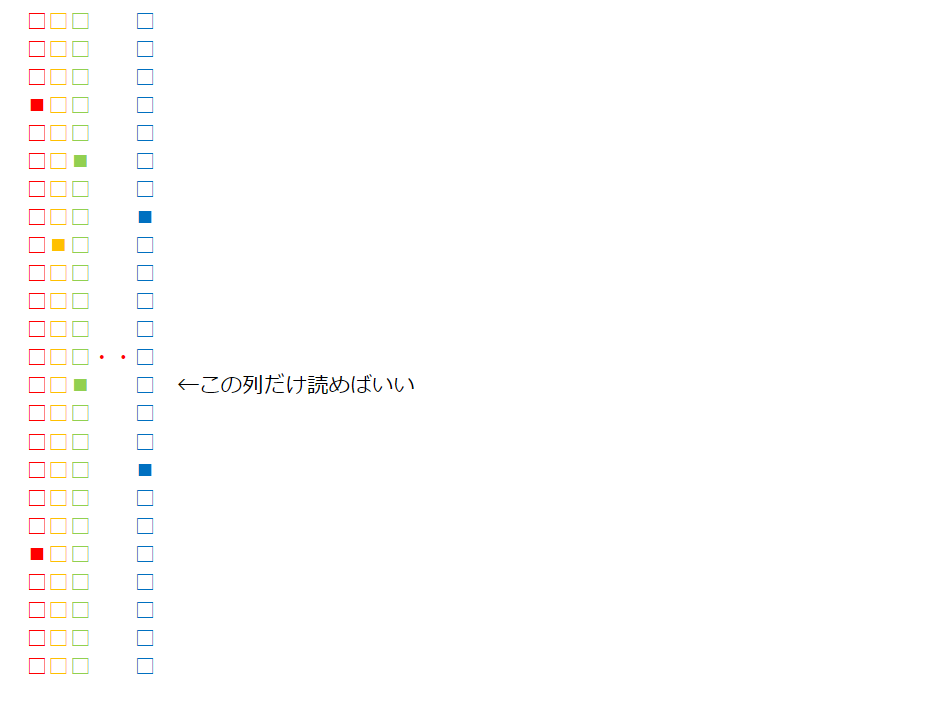
こうすると、判定のために読み込まなければならないのは、検索対象のグラムに対して立っているビットの列(上の例では14番目の列)だけにできます。大幅にI/Oを削減でき、きわめて高速に判定処理が行えることになります。
