

システム概要
作成したシステムは「特定の家族がお部屋に入った時間を記録するシステム」です。
システム構成は以下の通り。
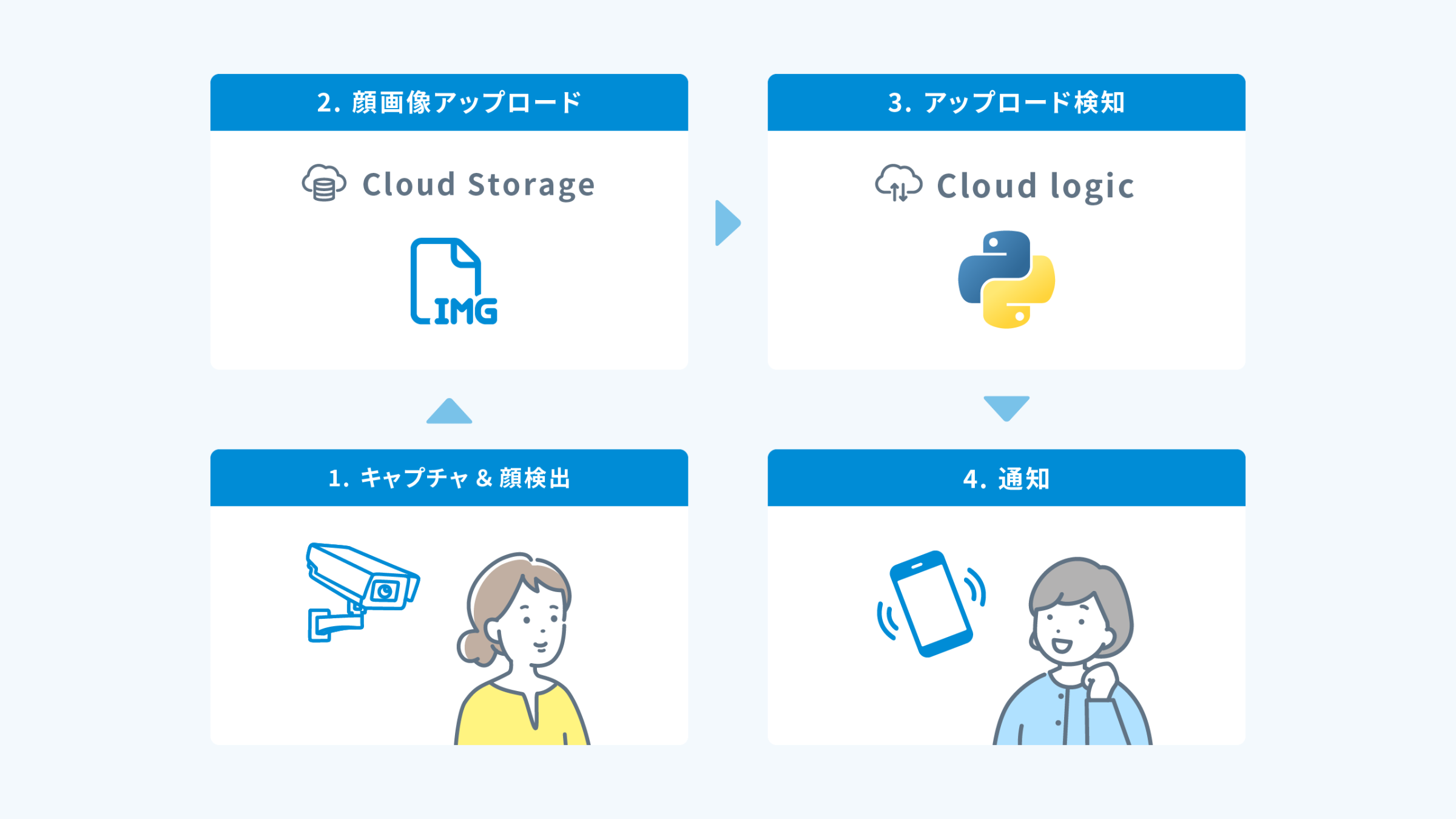
OpenCVを使って顔検出
カメラプレビュー画像の取得
AndroidManifestにPermission追加
<uses-permission android:name="android.permission.CAMERA" />
<uses-permission android:name="android.permission.CAMERA.AUTOFOCUS" />
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/> ①
・ストレージに画像を保存する為、ストレージ書き込み権限も追加しています (①)。
SurfaceHolder.Callback 実装クラス作成
public class CameraPreview implements SurfaceHolder.Callback {
private Camera mCam;
@Override
public void surfaceCreated(SurfaceHolder holder) {
int cameraId = 0;
mCam = Camera.open(cameraId);
mCam.setDisplayOrientation(90); ①
//mCam.startPreview(); ②
}
@Override
public void surfaceChanged(SurfaceHolder holder, int format, int width, int height) {
//mCam.stopPreview(); ②
Camera.Parameters params = mCam.getParameters();
//params.setRotation(90); ③
params.setPreviewSize(640, 480); ④
mCam.setParameters(params);
mCam.startPreview();
}
-
プレビュー画像を取得して表示するとデフォルトで横向きになるため、Camera.setDisplayOrientaion(90)で縦向きにしています(①)。
-
surfaceChangedの先頭でCamera.stopPreviewしているサンプルがありましたが、stopPreviewするとプレビュー画像を取得するコールバックが呼ばれなくなったため、surfaceChangedの最後でstartPreviewするようにしています(②)。
-
この後で取得するプレビュー画像もデフォルトで横向きになります。Camera.Parameters.setRotaion(90)で向きを補正できると書かれているWebページもありますが、使用した環境では横向きになりませんでした。かわりにプレビュー画像取得する際に向きを補正します。(③)。
-
Camera.Parameters.getSupportedPreviewSizes()で取得したサイズをsetParametersでセットするサンプルもありましたが、この後で取得するプレビュー画像のサイズと同期されない為、640×480固定にしています(④)。
プレビュー画像の取得
@Override
public void onPreviewFrame(byte[] data, Camera camera) {
int w = camera.getParameters().getPreviewSize().width;
int h = camera.getParameters().getPreviewSize().height;
// BMP変換
Bitmap bmp = getBitmapImageFromYUV(data, w, h);
}
private static Bitmap getBitmapImageFromYUV(byte[] data, int width, int height) {
YuvImage yuvimage = new YuvImage(data, ImageFormat.NV21, width, height, null);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
yuvimage.compressToJpeg(new Rect(0, 0, width, height), 80, baos);
byte[] jdata = baos.toByteArray();
BitmapFactory.Options bitmapFatoryOptions = new BitmapFactory.Options();
bitmapFatoryOptions.inPreferredConfig = Bitmap.Config.RGB_565;
Bitmap bmp = BitmapFactory.decodeByteArray(jdata, 0, jdata.length, bitmapFatoryOptions);
Mat mat = new Mat();
org.opencv.android.Utils.bitmapToMat(bmp, mat);
Imgproc.cvtColor(mat, mat, Imgproc.COLOR_RGB2GRAY);
Imgproc.cvtColor(mat, mat, Imgproc.COLOR_GRAY2RGBA, 4);
org.opencv.android.Utils.matToBitmap(mat, bmp);
Matrix rotate = new Matrix();
rotate.setRotate(90);
bmp = Bitmap.createBitmap(bmp, 0, 0, width, height, rotate, true); ①
return bmp;
}
- 上記で取得するプレビュー画像はデフォルトで横向きになるため、縦向きに補正しています(①)。
顔検出 (OpenCV)
カスケード分類器の学習済みファイル出力
InputStream inStream = getResources().openRawResource(R.raw.haarcascade_frontalface_default);
File cascadeDir = getDir("cascade", Context.MODE_PRIVATE);
File cascadeFile = new File(cascadeDir, "haarcascade_frontalface_alt.xml");
FileOutputStream outStream = new FileOutputStream(cascadeFile);
byte[] buf = new byte[2048];
int rdBytes;
while ((rdBytes = inStream.read(buf)) != -1) {
outStream.write(buf, 0, rdBytes);
}
outStream.close();
inStream.close();
CascadeClassifierにcascadeファイルのパスを設定する為、一度ファイルに出力します。
顔検出
public class FaceClassifier {
static {
System.loadLibrary("opencv_java3");
}
public android.graphics.Rect[] checkFaceExistence (Bitmap bmp) {
Mat mat = new Mat();
Utils.bitmapToMat(bmp, mat);
MatOfRect rects = new MatOfRect();
mFaceDetetcor.detectMultiScale(mat, rects, 1.1, 2, CASCADE_SCALE_IMAGE,
new Size(30, 30), new Size(640, 480));
return openCVRectsToGraphicsRects(rects.toArray());
}
private android.graphics.Rect[] openCVRectsToGraphicsRects(Rect[] cvRects) {
android.graphics.Rect[] gRects = new android.graphics.Rect[cvRects.length];
if (cvRects.length > 0) {
int i = 0;
for (Rect cvRect : cvRects) {
gRects[i] = new android.graphics.Rect(cvRect.x, cvRect.y,
cvRect.x + cvRect.width, cvRect.y + cvRect.height);
}
}
return gRects;
}
試してみると、顔でない部分を顔として検出することがありました。人がいないとき(動きがないとき)の画像を保持しておいて、動きがあった部分に対して顔検出することで検出精度を上げられるのではと考えましたが、試すことまではできていません。
顔検出 (Android API)
Bitmap bmp = getBitmapImageFromYUV(data, w, h);
int bw = bmp.getWidth();
int bh = bmp.getHeight();
android.media.FaceDetector.Face faces[] = new android.media.FaceDetector.Face[10];
android.media.FaceDetector detector = new android.media.FaceDetector(bw, bh, faces.length);
detector.findFaces(bmp, faces);
for (android.media.FaceDetector.Face face : faces) {
if (face != null && face.confidence() >= 0.3) {
float dist = face.eyesDistance();
PointF mid = new PointF();
face.getMidPoint(mid);
float d2 = dist * (float)1.5;
float d4 = d2 * (float)2;
int fx = (int)(mid.x - d2);
int fy = (int)(mid.y - d2);
int fw = (int)d4;
int fh = (int)d4;
OpenCVの顔検出精度が低かった為、AndroidのAPIを使った顔検出も試してみましたが、誤検出が多くなっただけでした。
顔分類器を作成
環境構築(Azure Functions インスタンス作成)
Androidで顔検出した画像を分類する処理をAzure Functionsで実装しました。
以下の手順でインスタンスを作成します。
- Azure Portalにログイン
- [新規]-[Serverless Function App]を選択
- インスタンス情報を入力して作成(OSは、Windowsで作成しました)
環境構築(Blob Storage トリガー設定)
下記の参考サイトに記載の手順でPython Function作成、Blob Storage トリガーの設定をします。
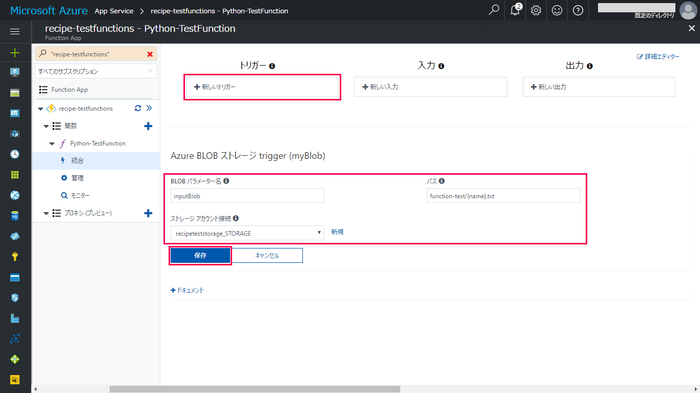
これで、Blobストレージに画像をアップロードすると、作成したPython Functionが実行されます。
環境構築(Python3/OpenCV/Tensorflow インストール)
Azure Portal でKuzu画面を開く
https://YOUR_APP_NAME.scm.azurewebsites.net/DebugConsole
YOUR_APP_NAME の部分は、作成したAzure FunctionのURLを入力します。
Python3 インストール
以下のコマンドを実行する。
cd D:\home\site\tools
nuget.exe install -Source https://www.siteextensions.net/api/v2/ -OutputDirectory D:\home\site\tools python361x64
mv /d/home/site/tools/python361x64.3.6.1.3/content/python361x64/* /d/home/site/tools/
OpenCV インストール
以下のコマンドを実行する。
D:\home\site\tools\python.exe -m pip install opencv-python
OpenCV インストール確認
作成したAzure Functionのrun.pyに以下記載して保存、実行します。 penCVのバージョンが表示されればインストール完了です。
import cv2
print(cv2.__version__)
Tensorflow インストール
以下のコマンドを実行する。
D:\home\site\tools\python.exe -m pip install tensorflow
Tensorflow インストール確認
作成したAzure Functionのrun.pyに以下の記載をして保存、実行します。
「Hello, TensorFlow!」と表示されればインストール完了です。
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
学習/検証用データ準備
画像データ用意
学習用/検証用の画像データを以下のディレクトリ構成で保存します。
/train
/Taro
img001.jpg
img002.jpg
・・・
/Hanako
img001.jpg
img002.jpg
・・・
/test
/Taro
img001.jpg
img002.jpg
・・・
/Hanako
img001.jpg
img002.jpg
・・・
Taro、Hanako は、家族の名前(分類対象)毎にフォルダを作成したものです。各フォルダに、それぞれの顔画像を保存します。 今回、学習用、検証用でそれぞれ100枚ずつ画像を用意しました。
画像一覧用意
この後の、学習用に画像ファイルのパスと分類を記載したテキストファイルを作成します。画像一覧ファイル作成用にPythonプログラムを作成しました。
csv.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import os
if __name__ == '__main__':
outdir = sys.argv[1]
if not os.path.isdir(outdir):
sys.exit('%s is not directory' % outdir)
names = {
"Taro": 0,
"Hanako": 1,
"other": 2,
}
#exts = ['.PNG','.JPG','.JPEG']
exts = ['.JPG','.JPEG']
for dirpath, dirnames, filenames in os.walk(outdir):
for dirname in dirnames:
if dirname in names:
n = names[dirname]
member_dir = os.path.join(dirpath, dirname)
for dirpath2, dirnames2, filenames2 in os.walk(member_dir):
if not dirpath2.endswith(dirname):
continue
for filename2 in filenames2:
(fn,ext) = os.path.splitext(filename2)
if ext.upper() in exts:
img_path = os.path.join(dirpath2, filename2)
print('%s %s' % (img_path, n))
学習処理作成
学習処理用のプログラムを添付します(下記の参考ページとほぼ同じです)。
main.py
# coding=utf-8
import sys
import cv2
import random
import numpy as np
import tensorflow as tf
import tensorflow.python.platform
# 識別ラベルの数
NUM_CLASSES = 2
# 学習する時の画像のサイズ(px)
IMAGE_SIZE = 32
# 画像の次元数(32* 32*カラー)
IMAGE_PIXELS = IMAGE_SIZE*IMAGE_SIZE*3
# 学習に必要なデータのpathや学習の規模を設定
flags = tf.app.flags
FLAGS = flags.FLAGS
# 学習用データ
flags.DEFINE_string('train', 'C:/Work/train/data.csv', 'File name of train data')
# 検証用テストデータ
flags.DEFINE_string('test', 'C:/Work/test/data.csv', 'File name of train data')
# データを置いてあるフォルダ
flags.DEFINE_string('train_dir', 'C:/Work/dst', 'Directory to put the training data.')
# データ学習訓練の試行回数
flags.DEFINE_integer('max_steps', 100, 'Number of steps to run trainer.')
# 1回の学習で何枚の画像を使うか
flags.DEFINE_integer('batch_size', 20, 'Batch size Must divide evenly into the dataset sizes.')
# 学習率
flags.DEFINE_float('learning_rate', 1e-4, 'Initial learning rate.')
# AIの学習モデル部分(ニューラルネットワーク)を作成する
# images_placeholder: 画像のplaceholder, keep_prob: dropout率のplace_holderが引数になり
# 入力画像に対して、各ラベルの確率を出力して返す
def inference(images_placeholder, keep_prob):
# 重みを標準偏差0.1の正規分布で初期化する
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
# バイアスを標準偏差0.1の正規分布で初期化する
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 畳み込み層を作成する
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# プーリング層を作成する
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
# 今回はカラー画像なので3(モノクロだと1)
x_image = tf.reshape(images_placeholder, [-1, IMAGE_SIZE, IMAGE_SIZE, 3])
# 畳み込み層第1レイヤーを作成
with tf.name_scope('conv1') as scope:
# 引数は[width, height, input, filters]。
# 5px*5pxの範囲で画像をフィルター
# 32個の特徴を検出する
W_conv1 = weight_variable([5, 5, 3, 32])
# バイアスの数値を代入
b_conv1 = bias_variable([32])
# 特徴として検出した有用そうな部分は残し、特徴として使えなさそうな部分は
# 0として、特徴として扱わないようにする
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# プーリング層1の作成
# 2*2の枠を作り、その枠内の特徴を1*1分に圧縮させる。
# その枠を2*2ずつスライドさせて画像全体に対して圧縮作業を適用する
with tf.name_scope('pool1') as scope:
h_pool1 = max_pool_2x2(h_conv1)
# 畳み込み層第2レイヤーの作成
with tf.name_scope('conv2') as scope:
# 第一レイヤーでの出力を第2レイヤー入力にしてもう一度フィルタリング実施。
# 64個の特徴を検出する。
W_conv2 = weight_variable([5, 5, 32, 64])
# バイアスの数値を代入(第一レイヤーと同じ)
b_conv2 = bias_variable([64])
# 検出した特徴の整理(第一レイヤーと同じ)
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# プーリング層2の作成(ブーリング層1と同じ)
with tf.name_scope('pool2') as scope:
h_pool2 = max_pool_2x2(h_conv2)
# 全結合層1の作成
with tf.name_scope('fc1') as scope:
W_fc1 = weight_variable([8*8*64, 1024])
b_fc1 = bias_variable([1024])
# 画像の解析を結果をベクトルへ変換
h_pool2_flat = tf.reshape(h_pool2, [-1, 8*8*64])
# 第一、第二と同じく、検出した特徴を活性化させている
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# dropoutの設定
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 全結合層2の作成(読み出しレイヤー)
with tf.name_scope('fc2') as scope:
W_fc2 = weight_variable([1024, NUM_CLASSES])
b_fc2 = bias_variable([NUM_CLASSES])
# ソフトマックス関数による正規化
# ここまでのニューラルネットワークの出力を各ラベルの確率へ変換する
with tf.name_scope('softmax') as scope:
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# 各ラベルの確率を返す
return y_conv
# 予測結果と正解にどれくらい「誤差」があったかを算出する
# logitsは計算結果: float - [batch_size, NUM_CLASSES]
# labelsは正解ラベル: int32 - [batch_size, NUM_CLASSES]
def loss(logits, labels):
# 交差エントロピーの計算
cross_entropy = -tf.reduce_sum(labels*tf.log(logits))
# TensorBoardで表示するよう指定
tf.summary.scalar("cross_entropy", cross_entropy)
# 誤差の率の値(cross_entropy)を返す
return cross_entropy
# 誤差(loss)を元に誤差逆伝播を用いて設計した学習モデルを訓練する
def training(loss, learning_rate):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
return train_step
# inferenceで学習モデルが出した予測結果の正解率を算出する
def accuracy(logits, labels):
# 予測ラベルと正解ラベルが等しいか比べる。同じ値であればTrueが返される
# argmaxは配列の中で一番値の大きい箇所のindex(=一番正解だと思われるラベルの番号)を返す
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(labels, 1))
# booleanのcorrect_predictionをfloatに直して正解率の算出
# false:0,true:1に変換して計算する
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# TensorBoardで表示する様設定
tf.summary.scalar("accuracy", accuracy)
return accuracy
def get_logits(logits, labels):
return logits
if __name__ == '__main__':
# ファイルを開く
f = open(FLAGS.train, 'r')
# データを入れる配列
train_image = []
train_label = []
for line in f:
# 改行を除いてスペース区切りにする
line = line.rstrip()
l = line.split()
# データを読み込む
img = cv2.imread(l[0])
# 一列にした後、0-1のfloat値にする
train_image.append(img.flatten().astype(np.float32)/255.0)
# ラベルを1-of-k方式で用意する
tmp = np.zeros(NUM_CLASSES)
tmp[int(l[1])] = 1
train_label.append(tmp)
# numpy形式に変換
train_image = np.asarray(train_image)
train_label = np.asarray(train_label)
f.close()
f = open(FLAGS.test, 'r')
test_image = []
test_label = []
for line in f:
line = line.rstrip()
l = line.split()
img = cv2.imread(l[0])
test_image.append(img.flatten().astype(np.float32)/255.0)
tmp = np.zeros(NUM_CLASSES)
tmp[int(l[1])] = 1
test_label.append(tmp)
test_image = np.asarray(test_image)
test_label = np.asarray(test_label)
f.close()
#TensorBoardのグラフに出力するスコープを指定
with tf.Graph().as_default():
# 画像を入れるためのTensor(32*32*3(IMAGE_PIXELS)次元の画像が任意の枚数(None)分はいる)
images_placeholder = tf.placeholder("float", shape=(None, IMAGE_PIXELS))
# ラベルを入れるためのTensor(4(NUM_CLASSES)次元のラベルが任意の枚数(None)分入る)
labels_placeholder = tf.placeholder("float", shape=(None, NUM_CLASSES))
# dropout率を入れる仮のTensor
keep_prob = tf.placeholder("float")
# inference()を呼び出してモデルを作る
logits = inference(images_placeholder, keep_prob)
# loss()を呼び出して損失を計算
loss_value = loss(logits, labels_placeholder)
# training()を呼び出して訓練して学習モデルのパラメーターを調整する
train_op = training(loss_value, FLAGS.learning_rate)
# 精度の計算
acc = accuracy(logits, labels_placeholder)
# 保存の準備
saver = tf.train.Saver()
# Sessionの作成
sess = tf.Session()
# 変数の初期化
sess.run(tf.global_variables_initializer())
# TensorBoard表示の設定
summary_op = tf.summary.merge_all()
# train_dirでTensorBoardログを出力するpathを指定
summary_writer = tf.summary.FileWriter(FLAGS.train_dir, sess.graph)
# 実際にmax_stepの回数だけ訓練の実行していく
for step in range(FLAGS.max_steps):
for i in range(int(len(train_image)/FLAGS.batch_size)):
# batch_size分の画像に対して訓練の実行
batch = FLAGS.batch_size*i
# feed_dictでplaceholderに入れるデータを指定する
sess.run(train_op, feed_dict={
images_placeholder: train_image[batch:batch+FLAGS.batch_size],
labels_placeholder: train_label[batch:batch+FLAGS.batch_size],
keep_prob: 0.5})
# 1step終わるたびに精度を計算する
train_accuracy = sess.run(acc, feed_dict={
images_placeholder: train_image,
labels_placeholder: train_label,
keep_prob: 1.0})
print("step %d, training accuracy %g"%(step, train_accuracy))
# 1step終わるたびにTensorBoardに表示する値を追加する
summary_str = sess.run(summary_op, feed_dict={
images_placeholder: train_image,
labels_placeholder: train_label,
keep_prob: 1.0})
summary_writer.add_summary(summary_str, step)
# 訓練が終了したらテストデータに対する精度を表示する
print("test accuracy %g"%sess.run(acc, feed_dict={
images_placeholder: test_image,
labels_placeholder: test_label,
keep_prob: 1.0}))
# データを学習して最終的に出来上がったモデルを保存
# "model.ckpt"は出力されるファイル名
save_path = saver.save(sess, 'C:/work/model2.ckpt')
上記のプログラムを実行すると準備した学習用画像を元に学習し、 検証用画像を使った検証結果の精度が表示されます。
100ステップの学習を繰り返すようにしていますが、30ステップ程度で100%の精度になっています。 検証用画像を使った検証結果の精度は、98% です。
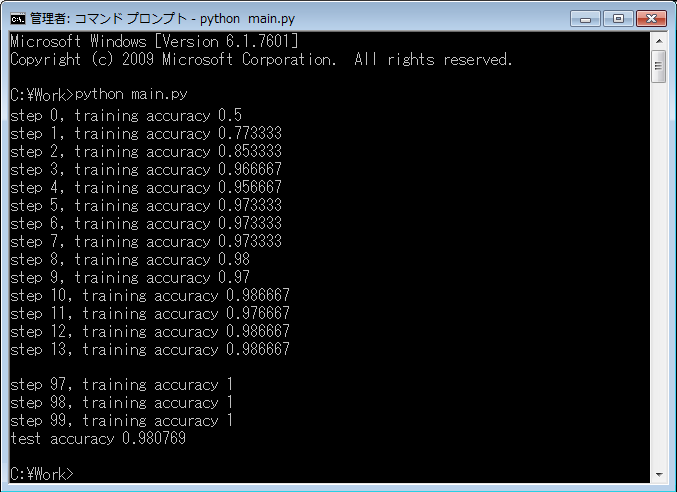
学習実施後、C:\Workの下に以下のファイルが作成されます。
- model2.ckpt.data-00000-of-00001
- model2.ckpt.index
- model2.ckpt.meta
分類処理作成
学習したモデルを使って画像を分類するプログラムです。
run.py
# coding=utf-8
import sys
import numpy as np
import cv2
import tensorflow as tf
import os
import random
import main
import requests
HUMAN_NAMES = {
0: u"Taro",
1: u"Hanako",
}
img_path = os.environ['inputBlob']
ckpt_path = 'model2.ckpt'
tf.reset_default_graph()
f = open(img_path, 'r')
img = cv2.imread(img_path)
image = []
image.append(img.flatten().astype(np.float32)/255.0)
image = np.asarray(image)
logits = main.inference(image, 1.0)
sess = tf.InteractiveSession()
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
saver.restore(sess, ckpt_path)
softmax = logits.eval()
result = softmax[0]
rates = [round(n * 100.0, 1) for n in result]
if rates[1] > rates[0]:
print('Taro')
else:
print('not Taro')
run.py、main.py、model2.ckpt をAzure Functionにアップロードして実行。 Blob Storageに顔画像をアップロードすると分類されます。
Line Notify で通知
アクセストークンを作成する
今回、Line Notify を使って通知するようにしました。
まず、Line Notify のアクセストークンを発行します。
- Line Notify のマイページ にアクセス
- トップ画面右上のメニューから[マイページ]を選択
- [アクセストークンの発行(開発者向け)] の[トークンを発行する]ボタンを押下
分類した結果を通知する
顔分類器を作成で作った run.py にLine通知する処理を追加します。
if rates[1] > rates[0]:
url = 'https://notify-api.line.me/api/notify'
token = 'ここにアクセストークンを設定'
headers = {'Authorization' : 'Bearer '+ token}
message = '通知メッセージ'
payload = {'message' : message}
#バイナリで画像ファイルを開きます。対応している形式はPNG/JPEGです。
files = {'imageFile': open(img_path, 'rb')}
r = requests.post(url ,headers = headers ,params=payload, files=files)
else:
print('not Taro')
参考
- Androidプログラマへの道 プレビュー画像を取得する
- OpenCVを使って、簡単顔認識Androidアプリを作ってみた
- Azure Functions: BlobコンテナーをトリガーとするPython関数を作成してみる
- Azure FunctionsでPython3とpipを使う
- TensorFlowを使ってDir en greyの顔分類器を作ってみた
- TensorFlowによるディープラーニングで、アイドルの顔を識別する
- Google Apps ScriptからLINE NotifyでLINEにメッセージを送る
- PythonからLINE NotifyでLINEにメッセージを送る
以上、宜しくお願い致します。
