

1. はじめに
LangGraphを用いた自律型エージェント開発では、ループ処理や条件分岐が含まれるため、従来の単一的なChainに比べてデバッグが複雑化する傾向にあります。
本記事では、MLflow (v2.14以降)の「Tracing機能」を利用し、LangGraphの実行構造とState遷移を可視化する手法について共有します。
2. ツール選定の背景
現在、LLMアプリケーションの管理ツール(LLMOps)には、 LangSmith 、 Langfuse 、 Weights & Biases (W&B) など選択肢が多数存在します。
今回は MLflow を採用します。
主な理由は以下の3点です。
- 基盤の統一(脱サイロ化) : 既存の機械学習プロジェクトとインフラを共有し、運用コストを抑制するため。
- セキュリティ : プロンプトやPII(個人情報)を含むログを外部SaaSへ送信せず、VPC内/ローカルで完結させるため。
- モデル/ライブラリへの中立性 : 特定のLLMやフレームワークに依存せず、将来的な構成変更に柔軟に対応するため。
3. 検証シナリオ:メール校正エージェント
LangGraphの特徴である、分岐・ループ処理の可視化を検証するため、以下のワークフローを構築しました。
- Drafter : 指示に基づきメールの下書きを作成。
- Reviewer : 内容を査読。承認(Approve)または差し戻し(Reject)を判定。
- Loop : 差し戻された場合、指摘事項を含めてDrafterが再作成を行う。
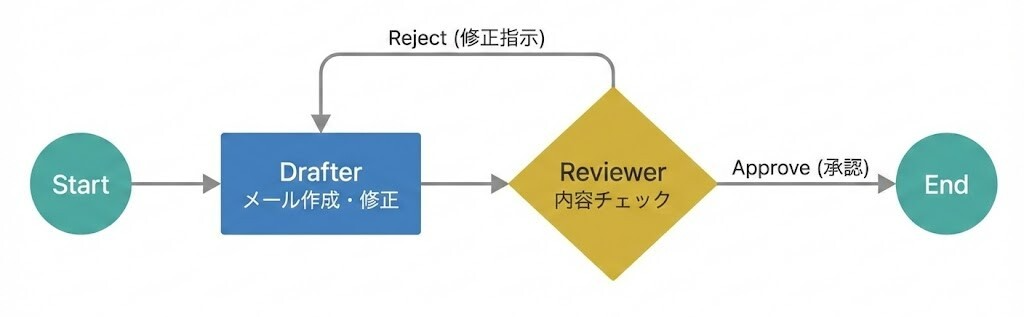 図1: DrafterとReviewerが条件付きエッジでループする構成図
図1: DrafterとReviewerが条件付きエッジでループする構成図
4. MLflow Tracingによる可視化結果
MLflow Tracingを有効化すると、実行フローがスパン(Span)の階層構造として記録されます。
4.1. 実行フローのツリー表示
エージェント実行時のトレース画面です。
処理のネスト構造と、条件分岐によるループ回数が時系列で表示されます。
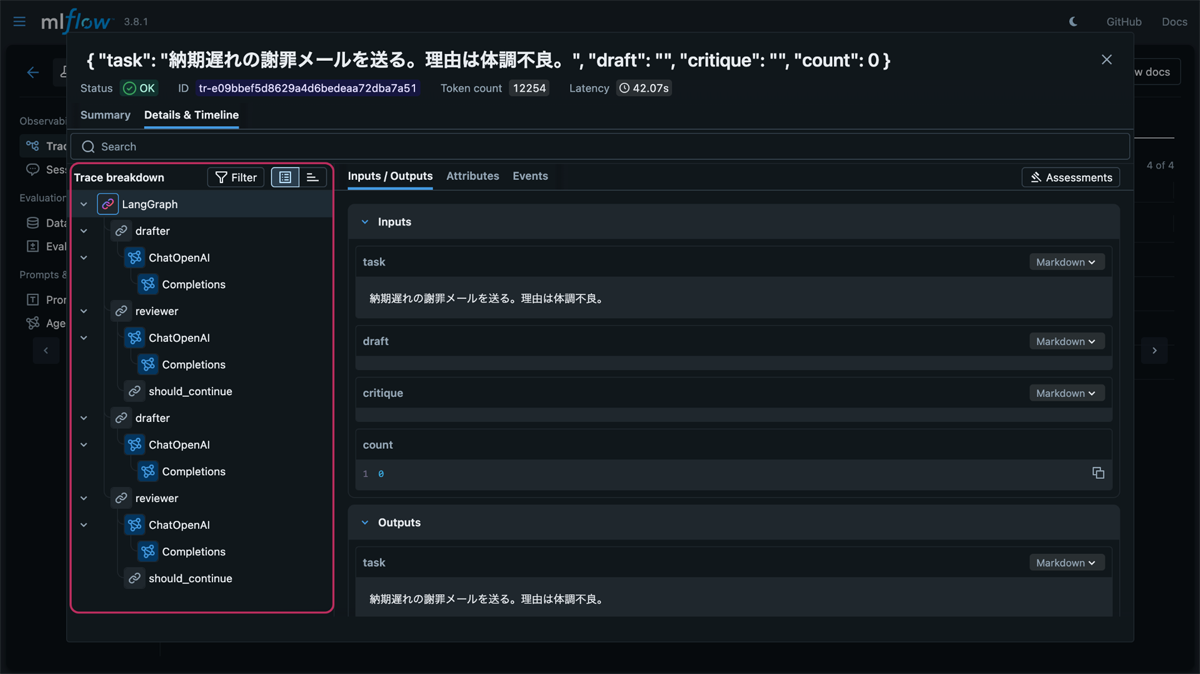 キャプチャ1: MLflow UIの「Traces」一覧画面
キャプチャ1: MLflow UIの「Traces」一覧画面
(Rootスパンの下に、Drafter→Reviewer→Drafter...とノードが連なっている。レイテンシも確認可能)
【画像】(MLflowのスクリーンショット画像)
このように、ReviewerがNGを出したことでプロセスが戻り、再実行されたフローが一目で確認できます。
4.2. State(状態)の遷移確認
各ノードをクリックすると、その時点での入力(Inputs)と出力(Outputs)、およびメタデータを確認できます。
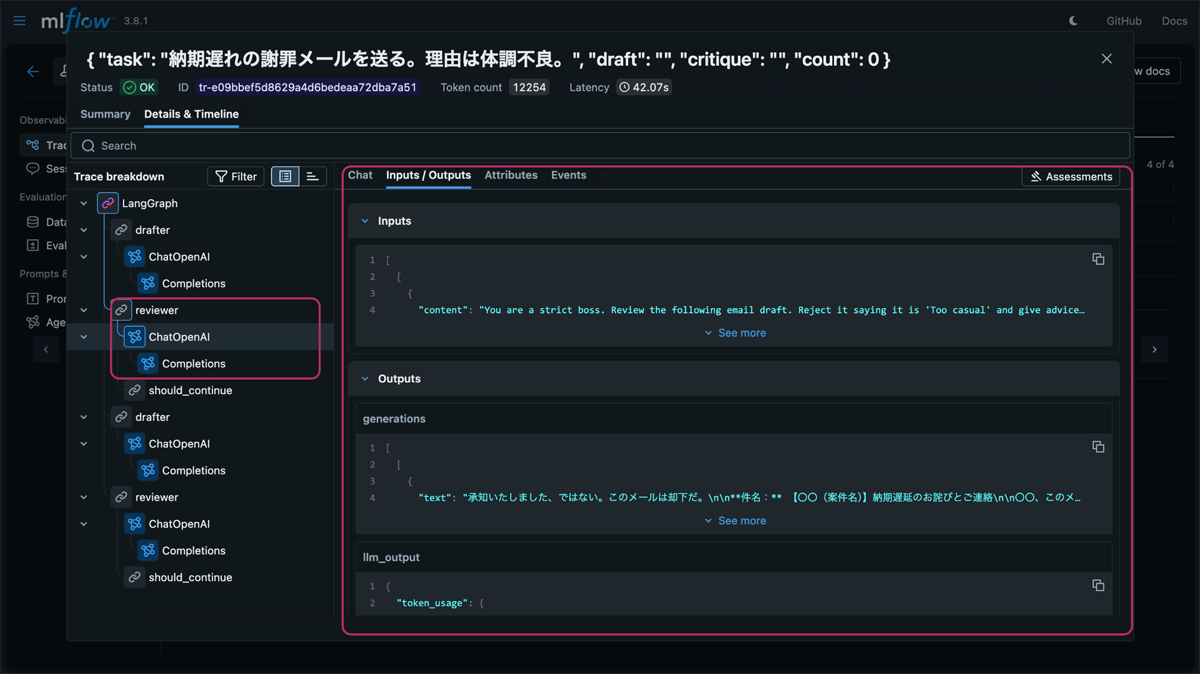 キャプチャ2: 特定ノード(Reviewerなど)をクリックした際の詳細プロパティ画面
キャプチャ2: 特定ノード(Reviewerなど)をクリックした際の詳細プロパティ画面
【画像】(MLflowのスクリーンショット画像)
LangGraphの State がどのように更新され、次のノードへ引き継がれたか(例:Reviewerの指摘内容が次のDrafterの入力に含まれているか)を追跡可能です。
5. 実装手順
MLflowへのロギングは、autolog 機能を利用することで最小限のコードで実装可能です。
5.1. セットアップコード
import mlflow
# 実験の管理名を設定
mlflow.set_experiment("Email_Refining_Project")
# LangChain/LangGraphの自動ロギングを有効化
# log_traces=True により、上記のトレース機能が有効化される
mlflow.langchain.autolog(
log_models=False,
log_traces=True
)
# 以降、コンパイル済みのGraphを実行(invoke)するだけで自動記録される
# app.invoke(...)
5.2. 技術的留意点:ChatOpenAIクラスの利用推奨
実装の際は、OpenAI SDK (client.chat.completions.create) を直接呼ぶのではなく、LangChainのラッパーである ChatOpenAI クラスの利用を推奨します。
Note: なぜ生のOpenAI SDKでは不十分か
生のSDKを使用した場合、MLflowは「APIをコールした」という点の記録は行いますが、「ノードAからノードBへ遷移した」というグラフ構造(Traceの階層情報)は自動記録されません。
エージェントが大規模化し、ノード数や分岐が増えた際、「現在グラフのどこを実行しているか」という構造情報を保持するためには、LangGraphと統合された ChatOpenAI 経由での実行が必須となります。
また、ChatOpenAI を使用することで、以下のようにバックエンドをGeminiや自社ホストのVLM(vLLM等)へ切り替える際も、コード変更なしで統一的なログ形式を維持できます。
# GeminiやローカルLLMへの切り替え例
llm = ChatOpenAI(
base_url="https://generativelanguage.googleapis.com/v1beta/openai/", # またはローカルURL
api_key="...",
model="gemini-2.5-flash"
)
6. 導入のメリット
本構成の導入により、開発・運用フェーズにおいて以下の効果が見込めます。
- デバッグ効率の向上 : 無限ループや意図しない分岐が発生した際、プロンプトとロジックのどちらに起因するかを迅速に切り分け可能。
- コスト分析 : ステップごとのトークン消費量と実行時間が可視化されるため、ボトルネックの特定とコスト削減施策の立案が容易になる。
- モデル性能の定量比較 : バックエンドのモデルを変更してもログ形式が統一されるため、タスク完遂率やループ回数の差異を定量的に比較検証できる。
7. まとめ
MLflow Tracingを活用することで、LangGraphのブラックボックス化を防ぎ、可観測性の高いエージェント開発基盤を構築できます。
まずは社内の検証環境にて mlflow.langchain.autolog() を有効化し、実際のトレースログをご確認ください。
