

AI・データ分析コンペティションの世界最大級プラットフォーム「Kaggle(カグル)」で、心電図画像のデジタル化をテーマにした医療系コンペティションが開催されました。
- コンペティション名: PhysioNet - Digitization of ECG Images
- 主催: PhysioNet
- 期間: 2025年10月21日 - 2026年1月22日
- 参加者数: 1424チーム
このコンペティションは、AIと画像認識技術を駆使して「心電図画像から正確に波形信号を抽出(デジタル化)できるか」を競うものです(図1)。
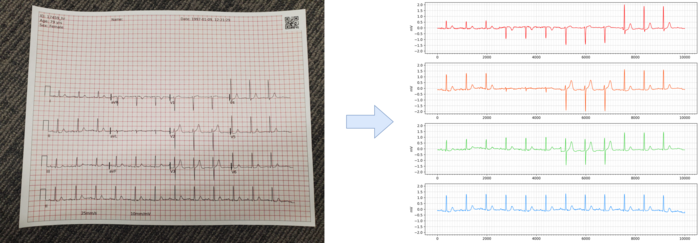 図1. 画像(左)と抽出した心電図信号(右、実際の読み取り結果)
図1. 画像(左)と抽出した心電図信号(右、実際の読み取り結果)
※(出典:Kaggle<https://www.kaggle.com/competitions/physionet-ecg-image-digitization/data>)
私はAIエンジニアとしてAI・画像認識技術をさらに高めたいと思い、今回のコンペティションに挑戦しました。
この記事では、コンペへの取り組み全体や活用したAI・画像認識の技術について、わかりやすくご紹介します。
最終的には全1424チーム中で2位という成績を収め、準優勝することができました。
Kaggleでは、成績上位の参加者にはメダルが贈られます。
上位約1%が金メダル、5%が銀メダル、10%が銅メダルの対象です。
今回のコンペで通算5枚目の金メダルを獲得し、Kaggleの最上位称号である“Kaggle Grandmaster”となりました。
デジタル化の精度は、信号対雑音比(SNR: Signal-to-Noise Ratio)で評価します。
ここでの雑音は、真の信号と復元(予測)信号との差(誤差)を指します。
SNRは、信号と雑音の比を対数表示した指標で、通常は dB(デシベル)で表されます。
値が高いほど、デジタル化の精度が高いことを意味します。
主催者は、SNRが15~20 dB を超えると人間の目では差異の判別が難しくなると述べており、実用化の目安とされています。
私のAIソリューションはSNR 23.27dBを達成し、前年のPhysioNetコンペティションの優勝スコア12.15dBを大幅に上回りました。
はじめに
Kaggleとは
Kaggleは、Google LLCが運営する世界最大規模のAI・データ分析コンペティションプラットフォームです。
企業や研究機関が提供する実データに対して、世界中の参加者が予測精度や分析手法を競い合います。
コンペティションのテーマは医療、教育、金融、生成AIなど多岐にわたり、学術的な研究課題から実社会の課題解決に直結するものまで幅広く開催されています。
参加者はコンペを通じて最先端の技術を実践的に習得できるだけでなく、世界中の参加者とのディスカッションを通じて知見を深めることができます。
また、上位に入賞するとメダルや賞金を獲得でき、世界中から多くのユーザーが高い精度を目指して競い合っています。
なぜ心電図のデジタル化が求められるのか
皆さんも健康診断で心電図を測定した経験があるのではないでしょうか。
近年、AIを活用して心電図データから心疾患を早期に発見する技術が発展してきています。
しかし、AIで解析するにはデータがデジタル形式である必要があります。
ここで課題となるのが、世界にはまだ膨大な量の「紙の心電図」が残っているという事実です。
The George B. Moody PhysioNet Challenge 2024によると、先進国では心電図のデジタル化が進む一方、新興国・途上国では紙の心電図が依然として主流であり、その数は世界全体で数十億枚にのぼると推定されています。
紙の心電図のデジタル化が実現すれば、その恩恵は大きく2つあります。
1つ目は、新興国・途上国における医療の改善です。
デジタル化されたデータにAI解析を適用することで、これまで十分な診断環境がなかった地域でも心疾患の早期発見が可能になり、グローバルな医療格差の解消につながります。
2つ目は、医学研究への貢献です。
数十億枚の紙の心電図には、地域・人口・時代にわたる心疾患の傾向が蓄積されています。
これらをデジタル化すれば、大規模な集団を長期間にわたって追跡・比較する研究(コホート研究)が可能となり、心疾患の発症リスクや経年変化に関する新たな知見が得られると期待されます。
本コンペは、まさにこの技術の発展を目指すものであり、医療と研究の両面から社会に貢献できる取り組みです。
心電図画像をデジタル化する方法
本コンペで扱う心電図画像には、スマホで撮影したものやスキャナーで取り込んだものなど様々な種類があります。
スキャン画像では画像全体に心電図が写っていますが、スマホ撮影画像では背景が写り込むなど、画像の見え方が大きく異なります(図2)。
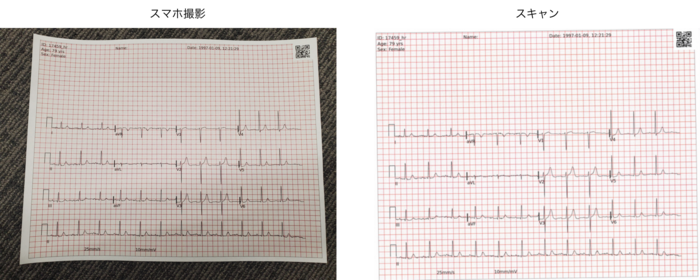 図2. スマホ撮影画像とスキャン画像の違い
図2. スマホ撮影画像とスキャン画像の違い
※(出典:Kaggle<https://www.kaggle.com/competitions/physionet-ecg-image-digitization/data>)
心電図画像には赤いグリッド線が引かれており、横方向の1マスは0.2秒、縦方向の1マスは0.5mVを表しています。
これらのグリッド線の交点が、すべての画像で同じ位置(例えば、左上の交点が画像座標のx=0, y=0)に揃うよう画像を変換することで、撮影方法による画像の見え方のばらつきを補正します。
本記事では、この作業を「画像の正規化」と呼びます。
次に、正規化した画像から実際の心電図信号の「時間」と「電圧」の数値データを抜き出します。
この工程では、AIの画像処理技術である「セグメンテーション」を活用し、画像内の心電図(黒い波形線)がどこに位置しているかをピクセルレベルで高精度に見つけ出します。
見つけ出した位置情報は画像の座標から電圧値に変換できるため、本記事ではこの一連の流れを「信号の抽出」と呼びます。
以降のセクションでは、「画像の正規化」と「信号の抽出」それぞれの技術的な詳細を説明します。
画像の正規化
画像の正規化は、以下の3つのステップで行います(図3)。
- 画像の台形補正
- グリッド交点の検出
- グリッド格子の変形
 図3. 画像の正規化プロセス
図3. 画像の正規化プロセス
※(出典:Kaggle<https://www.kaggle.com/competitions/physionet-ecg-image-digitization/data>)
まずステップ1で台形補正を行い、画像全体の大まかな歪みを取り除きます。
続くステップ2では、グリッド線の交点を検出します。
ただし、紙のシワや波打ち、撮影時の角度などの影響で、検出された交点が構成するグリッド格子にはまだ細かな歪みが残っています。
そこでステップ3では、図4に示すように歪んだグリッド格子を等間隔の正しいグリッド(Undistorted Image Template)へ変形させることで、歪みのない画像を生成します(図3右)。
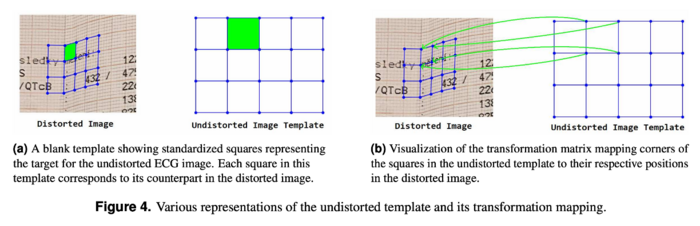 図4. グリッド格子の歪み補正
図4. グリッド格子の歪み補正
※(出典:High Precision ECG Digitization Using Artificial Intelligence<https://www.medrxiv.org/content/10.1101/2024.08.31.24312876v1.full.pdf>)
この正規化をすべての画像に適用することで、グリッド交点の位置が統一され、後続の信号抽出をスムーズに進めることができます。
信号の抽出
正規化が完了した画像から、実際に心電図の信号を読み取る工程です。
ここでは「セグメンテーションマスク」と呼ばれる中間表現を経由して信号を復元します。
セグメンテーションマスクの設計
信号抽出の精度を大きく左右するのが、セグメンテーションマスクの作り方です。
セグメンテーションマスクとは、画像のどのピクセルが心電図の信号線に該当するかをラベル付けしたデータです。
AIモデルはこのマスクを予測することで、画像から心電図信号の位置を特定します。
本手法では、心電図の線をすべて塗りつぶす「密なマスク」ではなく、線上のごく一部のピクセルだけをラベル付けする「疎なマスク」を採用しています。
図5のように、信号全体を塗るのではなく、実際のサンプリング点(デジタル化のため、所定の周波数で信号を抽出する必要があります)の位置のみを的確に予測することで、信号座標の特定精度を大幅に高めることができました。
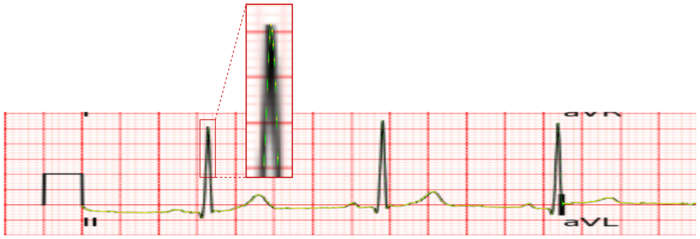 図5. セグメンテーションマスクの例(黄色が正解のマスク、緑色がAIモデルの予測結果)
図5. セグメンテーションマスクの例(黄色が正解のマスク、緑色がAIモデルの予測結果)
※(出典:Kaggle<https://www.kaggle.com/competitions/physionet-ecg-image-digitization/data>)
さらに、小数点以下の精度で信号位置を表現するため、電圧値をy座標に変換した際の小数部分に応じて、隣接する2ピクセルにラベル値を分配する工夫を行いました。
復元時にはこのラベル値を重みとしてy座標の加重平均をとることで、サブピクセル精度での信号復元を実現しています。
図6に具体例を示します。
信号値11.71をマスクに変換する場合、y座標の整数部分11と整数部分+1の12にそれぞれ小数部分に基づいたラベル値を割り当てます。
11.71の小数部分は0.71なので、y=12に0.71、y=11に1-0.71=0.29を分配します。
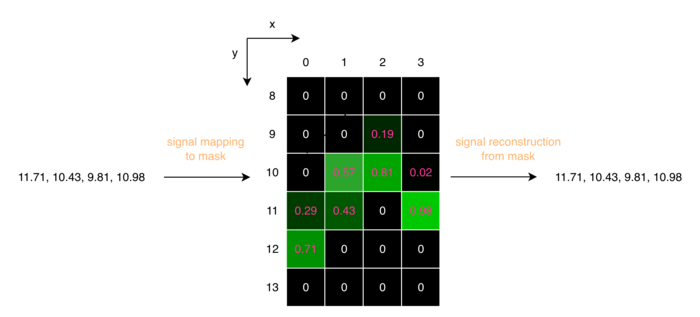 図6. セグメンテーションマスクから信号を復元する仕組み
図6. セグメンテーションマスクから信号を復元する仕組み
復元時には、各列のラベル値を重みとしてy座標の加重平均を計算します。
例えば、x=0の列では以下のように元の信号値11.71を復元できます。
y座標の加重平均 = (11 × 0.29 + 12 × 0.71) / (0.29 + 0.71) = 11.71
同様に、x=1の列(y=10に0.57、y=11に0.43)からは (10 × 0.57 + 11 × 0.43) / 1.0 = 10.43 が、x=2の列(y=9に0.19、y=10に0.81)からは (9 × 0.19 + 10 × 0.81) / 1.0 = 9.81 が復元されます。
このように、整数のピクセル座標しか持たないマスクから、小数点以下の精度で元の信号値を忠実に復元できることがこの手法のポイントです。
クロス誘導モデル
心電図の各誘導(I, II, III, aVRなどの記号で区分される信号)間には、医学的に知られた相関関係があります。
例えばIIの誘導はIとIIIの誘導とII ~ I + IIIのような関係があります(Eindhovenの法則)。
この性質を活用するため、複数の誘導を相互参照する「クロス誘導モデル」を構築しました(図7)。
各誘導の画像はゼロmVを中心に±3mV範囲で切り出し、共通のUNetエンコーダで特徴を抽出します。
その後、Fusionモジュールによって誘導間の特徴を統合し、UNetデコーダの各層で各誘導の特徴と結合して予測を出力します。
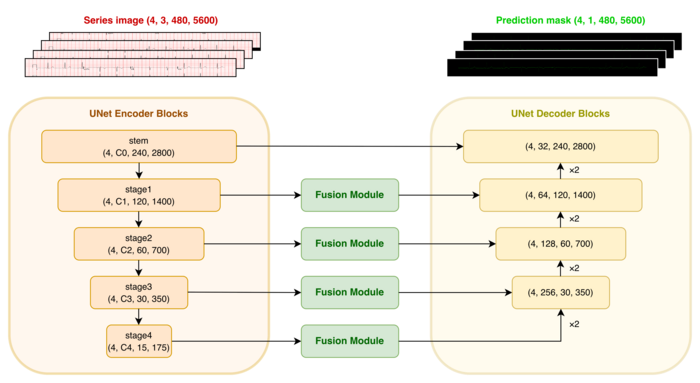 図7. クロス誘導モデルのアーキテクチャ
図7. クロス誘導モデルのアーキテクチャ
※(出典:Kaggle<https://www.kaggle.com/competitions/physionet-ecg-image-digitization/data>)
Fusionモジュール
Fusionモジュールは、誘導間の特徴を統合して各誘導の予測に活かす仕組みです(図8)。
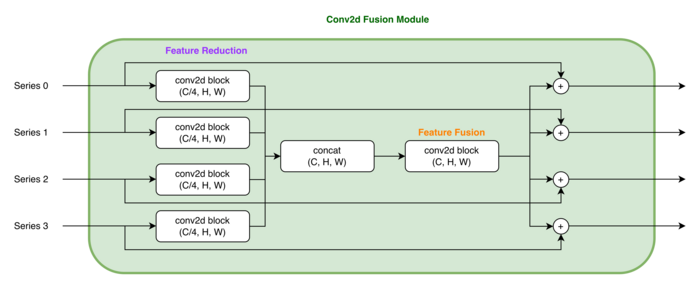 図8. Fusionモジュールの構造
図8. Fusionモジュールの構造
まず、各誘導の特徴マップ(チャネル数C)をconv2dブロックでC/4に圧縮します(Feature Reduction)。
次に、圧縮した4つの特徴マップをチャネル方向に結合(concat)して元のチャネル数Cに戻し、conv2dブロックで誘導間の関係性を学習します(Feature Fusion)。
最後に、この統合された特徴を各誘導の元の特徴に加算(+)することで、自身の情報を保ちつつ他の誘導からの情報を取り込みます。
Fusionモジュールの効果
Fusionモジュールの効果を検証するため、意図的に画像の一部をマスク(隠蔽)し、その状態での各モデルの予測結果を比較しました。
図9では、上段がオリジナルの画像と正解データ、中段がFusionモジュールを使わないモデルの予測、下段がFusionモジュールを適用したモデルの予測結果を示しています。
Fusionモジュールなしのモデルはマスクされた領域で正確な予測ができないのに対し、Fusionモジュールを用いることで他の誘導の情報を活用し、隠れた領域でもピークの位相や振幅をある程度推定できていることがわかります。
特に、II誘導がマスクされた場合でも、隣接するIやIII誘導の情報をもとに、II誘導の波形をより高精度に復元していることが確認できました。
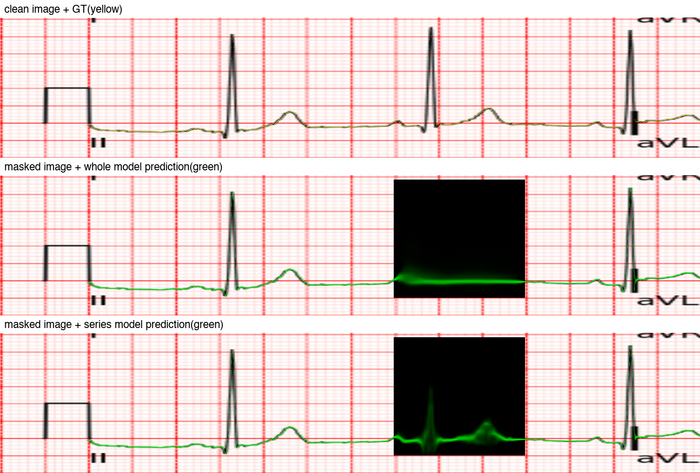 図9. Fusionモジュール有無による予測結果の比較
図9. Fusionモジュール有無による予測結果の比較
※(出典:Kaggle<https://www.kaggle.com/competitions/physionet-ecg-image-digitization/data>)
さいごに
今回のコンペティションには全世界から1424ものチームが参加し、心電図画像のデジタル化という共通課題に挑みました。
コンペ期間中はディスカッションフォーラムを通じて多様な参加者と活発な議論が交わされ、ベースラインとなるコードや新たな手法の共有など、コミュニティ全体で知見を深め合う貴重な機会となりました。
また、他の参加者の工夫や独自の発想に触れ、自分だけでは気づけなかったアプローチを学ぶことができた点は非常に刺激的でした。
コンペを通して得た幅広い知識や視点は、AIエンジニアとしてさらなる成長の原動力となりました。
これからもKaggleのような実践的な舞台でスキルを磨きながら、その経験を日々の業務や社会課題の解決に役立てていきたいと考えています。
