

AI・生成AIの利用が急速に拡大するなか、限られたGPUを複数ユーザーで効率よく共有するニーズが高まっています。
しかし「大きなGPUを複数ユーザーが共有する」環境では、想定外のメモリ衝突や性能のばらつきが頻発し、運用が難しくなりがちです。
本記事では、こうした課題を解決する NVIDIA の *MIG(Multi‑Instance GPU)*について説明します。
MIGとは何か?
MIG(Multi‑Instance GPU)は、1枚のGPUを複数の独立した“小さなGPU”として扱えるようにする技術です。
各インスタンスは専用の計算ユニット・メモリ・キャッシュを持ち、互いに干渉しません。
A100/H100/H200 などのデータセンター向けGPUで利用でき、用途に合わせて柔軟に分割できます。
一般的な「1枚のGPU上で複数プロセスを同時実行する」共有方式では、プロセス間でメモリや計算資源の取り合いが起きやすく、性能や安定性が揺らぎがちです。
その点MIGではハードウェアレベルでリソースを分離することで、安定性と予測可能性を確保します。
MIGが解決する課題
1つの大きなGPUを共有すると、次のようなトラブルが発生しがちです。
- あるプロセスがメモリを使い切り、他のジョブが落ちる
- 推論APIのレイテンシが、別ジョブの負荷で変動する
- ユーザー間で公平なGPU利用が実現できない
MIGはGPU内部を分割することで、安定性・公平性を同時に保証します。
GPU内部リソースをハードウェアで分割する仕組み
MIGでは、GPU内部の SM(演算ユニット)・メモリ容量・キャッシュ・帯域といった資源をハードウェアレベルで分割します。
分割の単位はプロファイルとして定義されており、たとえば 1g.5gb / 2g.10gb / 3g.20gb のように表されます。
ここで g は割り当てる計算資源(演算ユニット)の数、gb は割り当てるメモリ量を意味します。
これらのプロファイルを用途やワークロードに応じて、柔軟に組み合わせられる点が特徴です。
その結果、各インスタンスは完全に独立して動作し、他のジョブの影響を受けません。
MIG設定の実例
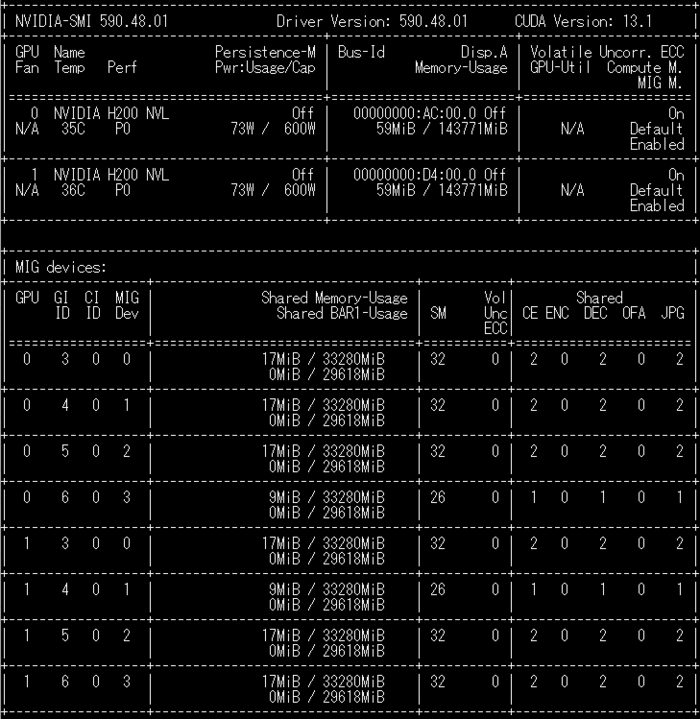
実際に、どのようにGPUが分割されるのか例を示します。
以下は 1枚あたり 143,771 MiB の H200 を2枚用い、2g.35gb ×3、1g.35gb ×1 の構成で分割したケースです。
(注:管理オーバーヘッドにより、プロファイル名の「35gb」より実効メモリは小さく、約 33.28 GiB(= 33,280 MiB)程度になります。)
設定時のコマンド例:
# インスタンス作成(GPU 0)
sudo nvidia-smi mig -i 0 -cgi 2g.35gb -C
sudo nvidia-smi mig -i 0 -cgi 2g.35gb -C
sudo nvidia-smi mig -i 0 -cgi 2g.35gb -C
sudo nvidia-smi mig -i 0 -cgi 1g.35gb -C
# インスタンス作成(GPU 1)
sudo nvidia-smi mig -i 1 -cgi 2g.35gb -C
sudo nvidia-smi mig -i 1 -cgi 2g.35gb -C
sudo nvidia-smi mig -i 1 -cgi 2g.35gb -C
sudo nvidia-smi mig -i 1 -cgi 1g.35gb -C
実運用のイメージ
MIGは特に次のようなシーンで効果を発揮します。
- 推論APIサーバー:小さなインスタンスを並べ、高密度かつ安定した推論基盤を構築
- 研究者の個別環境:ユーザーごとに1インスタンスを割り当て、干渉のない安全なGPU利用を実現
- Kubernetes連携:NVIDIA GPU Operator で Pod単位にMIGリソースを指定でき、スケジューリングが容易
メリットと注意点
- メリット
- 推論など小規模ワークロードの高密度配置
- ユーザーやジョブ間の干渉がゼロに
- GPU利用率が向上し、コスト削減に寄与
- 注意点
- 大規模学習には向かず、フルGPUが必要なケースもある
- プロファイル変更時は再構成が必要
- MIG対応GPUに限定される
まとめ:MIGがもたらす新しいGPUインフラ
MIGはGPUを「複数のユーザーが安全に共有できる資源」へと進化させる技術です。
特に軽量モデルの推論や小規模ジョブの大量実行では、無駄を抑えつつ安定性を確保した効率的な運用を実現します。
AI活用が加速するなか、MIGはGPUシェアリングの新しい標準技術として、今後ますます重要性が高まっていくでしょう。
