

近年、生成AIを使ったエージェントが注目を集めています。
複数ステップの処理をAIが自律的に行うことで、業務自動化や生産性向上が期待されています。
しかし実際には、
- どこから手をつければよいか分からない
- エージェントの挙動がブラックボックスになりやすい といったハードルがあり、最初の一歩が踏み出しにくいこともあります。
そこで今回は、LangGraphというフレームワークを使って、「シンプルなタスク管理AI」を実装してみます。
LangGraphとは?
LangGraphは、LangChainエコシステムで提供されている「グラフ指向」のエージェント開発フレームワークです。
処理をノード(関数)とエッジ(遷移)で表し、AIの動作フローを明確に設計できる点が特徴です。
主なポイントは次の3つです。
- ノードとエッジでワークフローを直感的に構築できる
- 任意のPython関数をノードとして利用でき、LLMを含むさまざまな処理を自由に組み合わせられます。
- 状態(State)を一元管理できるため、挙動が予測しやすい
- すべてのノードが共通のStateを読み書きする仕組みで、更新内容が追いやすい設計です。
- 条件分岐やループなど複雑な流れにも対応
- 次に進むノードを状態に応じて切り替えるロジックを明示的に書くことができます。
「何を先に実行し、どんな条件で次に進むか」をプログラマが明確に定義できる点が魅力です。
今回作るもの:シンプルなタスク管理AI
以下のような、とてもシンプルなエージェントを構築します。
- 入力:やりたいこと(自然文)
- 出力:整形されたタスクリスト+一言まとめ
- 処理:
- タスクを抽出
- タスクに優先度(高・中・低)を付与
- (期限語があれば) 期日を推定し優先度を調整
- 一言まとめ文を生成
4つのノードと1つの条件付きエッジを用いて、この処理の流れを実現していきます。
実装概要 (最小構成)
ここでは、各ノードの役割とその接続について説明します。
ソースの全体はこの記事の最後にあります。
各関数
- parse_tasks : 入力された自然文からタスクを抽出する(ノード)
- add_priority : タスクに優先度 (高・中・低) を付与する(ノード)
- route_after_priority : 期限語の有無で、次のノードを分岐する (条件付きエッジのルーター)
- deadline_estimate : タスクの期日を推定し、「今日/明日」なら優先度を「高」へ(ノード)
- summarize : すべてのタスクを踏まえて取り組み順序に対するまとめを行う(ノード)
グラフ構築
# グラフにノードを追加
graph = StateGraph(TaskState)
graph.add_node("parse", parse_tasks)
graph.add_node("priority", add_priority)
graph.add_node("deadline", deadline_estimate)
graph.add_node("summary", summarize)
# グラフの始点を定義
graph.set_entry_point("parse")
# 単純な接続
graph.add_edge("parse", "priority")
# 条件付き接続
graph.add_conditional_edges(
"priority",
route_after_priority,
{"deadline": "deadline", "summary": "summary"},
)
graph.add_edge("deadline", "summary")
# グラフをコンパイル
app = graph.compile()
処理フロー図
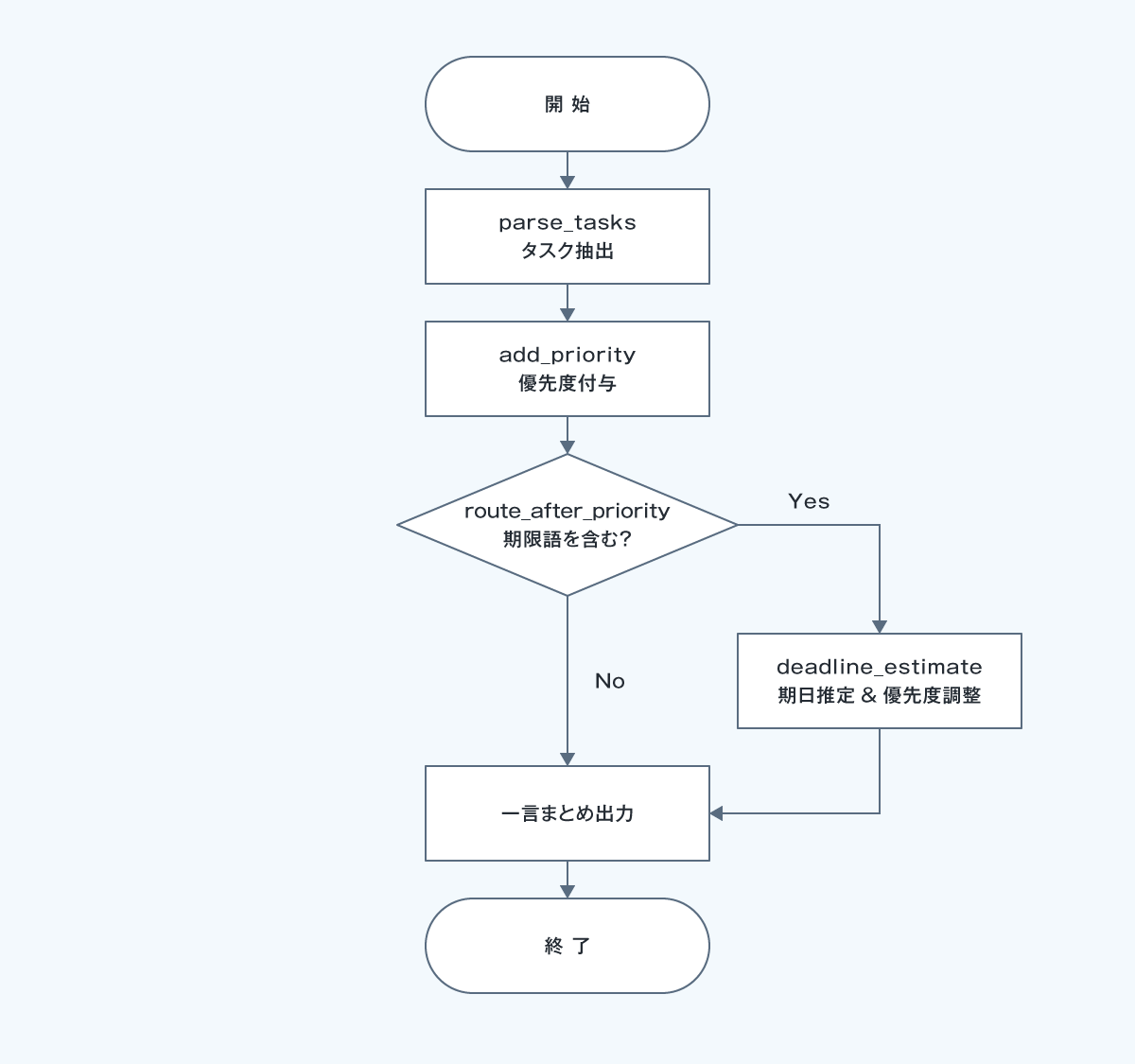
実行結果 (例)
- 入力
- 今日の夜締め切りのレポートは絶対終わらせないと。できれば掃除と洗濯もしたい。全部できたらご褒美にアイスを買いに行こう。
- 出力
- tasks:
- レポートを今日の夜までに終わらせる
- 掃除をする
- 洗濯をする
- すべてが終わったらアイスを買いに行く
- prioritized:
- {'task': 'レポートを今日の夜までに終わらせる', 'priority': '高', 'due': '今日'}
- {'task': '掃除をする', 'priority': '中', 'due': 'なし'}
- {'task': '洗濯をする', 'priority': '中', 'due': 'なし'}
- {'task': 'すべてが終わったらアイスを買いに行く', 'priority': '中', 'due': 'なし'}
- summary:
- 今日の夜までに終わらせるレポートを最優先で進め、その後掃除と洗濯を中程度の優先度で進め、すべて完了したらアイスを買いに行く。
- tasks:
まとめ
今回はLangGraphを使って「シンプルなタスク管理AI」を構築してみました。
LangGraphは、エージェント処理を“グラフ”で可視化できるため、「小さく作って理解する」というアプローチが非常にやりやすいフレームワークです。
本記事で紹介しているのはかなりシンプルなものですが、アイデア次第で機能拡張していくことができます。
ぜひ皆さんも、自身の使い方に合わせて拡張してみてください。
ソースコード全体
依存関係
- Python 3.10+
- 任意のLLM API (今回はQwen3-VLを使用)
- ライブラリ (langgraph, pydantic, python-dotenv, openai)
サンプルコード
from langgraph.graph import StateGraph
from pydantic import BaseModel, Field
from typing import List, Dict, Any
from dotenv import load_dotenv
from openai import OpenAI
import os
import json
import re
# .env を読み込む
load_dotenv()
# OpenAI APIクライアントを生成
client = OpenAI(
base_url=os.getenv("LOCAL_LLM_BASE_URL"),
api_key=os.getenv("LOCAL_LLM_API_KEY")
)
MODEL = "qwen3vl"
TIMEOUT = 60
# Chat Completions API を呼び出し、レスポンスを返す
def chat_once(system: str | None, user: str) -> str:
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": user})
resp = client.chat.completions.create(
model=MODEL,
messages=messages,
temperature=0.2,
timeout=TIMEOUT,
)
return resp.choices[0].message.content.strip()
# LangGraphのState
class TaskState(BaseModel):
raw_input: str = "" # 入力された文章
tasks: List[str] = Field(default_factory=list) # 抽出されたタスクのリスト
prioritized: List[Dict[str, Any]] = Field(default_factory=list) # 優先度と期限情報を含むタスクのリスト
summary: str = "" # 一言まとめ
# タスク抽出
def parse_tasks(state: TaskState):
prompt = (
"次の文からタスクを抽出して、箇条書きで1行1タスクで返してください。\\n"
f"{state.raw_input}"
)
text = chat_once(
system="あなたは日本語でタスク抽出を行う賢いアシスタントです。説明文は一切含めないこと。",
user=prompt,
)
# 箇条書きや改行区切りを想定
tasks = [line.lstrip("-•・ ").strip() for line in text.splitlines() if line.strip()]
return {"tasks": tasks}
# 配列部分だけ抜き出す
def _extract_json_array(text: str) -> str:
if not isinstance(text, str):
return "[]"
# コードブロック除去
text = re.sub(r"```.*?\`\`\`", "", text, flags=re.DOTALL)
# 配列らしき部分を抽出
start = text.find("[")
end = text.rfind("]")
return text[start:end + 1] if (start != -1 and end != -1 and end > start) else "[]"
# リストの要素がすべて辞書であるか確認
def _as_list_of_dicts(obj: Any) -> List[Dict[str, Any]]:
if isinstance(obj, list) and all(isinstance(x, dict) for x in obj):
return obj
return []
# 優先度(高/中/低)付け
def add_priority(state: TaskState):
prompt = (
"以下のタスクに優先度(高/中/低)を付け、JSON配列で返してください。"
"各要素は {\\"task\\": str, \\"priority\\": \\"高|中|低\\"} のみとします。\\n"
f"{state.tasks}"
)
text = chat_once(
system="必ずJSONのみを返してください。説明文は一切含めないこと。",
user=prompt,
)
raw = _extract_json_array(text)
try:
parsed = json.loads(raw)
data = _as_list_of_dicts(parsed)
except Exception:
data = []
if not data:
data = [{"task": str(t) if t else "", "priority": "中"} for t in state.tasks]
clean: List[Dict[str, Any]] = []
for item in data:
t = str(item.get("task", "")).strip()
p = str(item.get("priority", "中")).strip()
if p not in ("高", "中", "低"):
p = "中"
clean.append({"task": t, "priority": p})
return {"prioritized": clean} # List[dict]
# ルーター : 期限語の有無で、次のノードを分岐
def route_after_priority(state: TaskState):
# raw_input と抽出済み tasks を対象に簡易チェック
haystack = " ".join([state.raw_input] + state.tasks)
# 例: 今日/明日/まで/締切/期限/ 2026-01-23 / 1/23 / 01.23 など
pattern = r"(今日|明日|今週|来週|来月|今月|来年|まで|締切|期限|[0-9]{1,4}[./-][0-9]{1,2}([./-][0-9]{1,2})?)"
has_deadline = bool(re.search(pattern, haystack))
return "deadline" if has_deadline else "summary"
# タスクの期日を推定
def deadline_estimate(state: TaskState):
prompt = (
"以下のタスクについて、分かる範囲で期日を推定し、"
"JSON配列で返してください。キーは task と due のみ。"
"due は 'YYYY-MM-DD' または '今日' '明日' 'なし' のいずれかで返してください。\\n"
"特に、'今日' または '夜' などのワードがあれば、'今日' と推定してください。\\n"
f"{state.tasks}"
)
text = chat_once(
system="必ずJSONのみを返してください。説明文は一切含めないこと。",
user=prompt,
)
raw = _extract_json_array(text)
# raw が str でない場合、str に変換
if not isinstance(raw, str):
raw = str(raw)
try:
parsed = json.loads(raw)
due_list = _as_list_of_dicts(parsed)
except Exception:
# JSONパース失敗、rawを直接解析してdue_listを生成
due_list = []
# raw から task と due を直接抽出
lines = re.findall(r'\\s*["\']?(\\w+)["\']?\\s*:\\s*["\']?([^"']+)["\']?\\s*', raw)
for key, value in lines:
if key == "task":
due_list.append({"task": value, "due": "なし"})
elif key == "due":
if due_list and "task" in due_list[-1]:
due_list[-1]["due"] = value
else:
due_list.append({"task": "", "due": value})
# タスク名でマージし、due を prioritized に付与
due_map = {str(d.get("task", "")).strip(): str(d.get("due", "なし")).strip() for d in due_list}
boosted: List[Dict[str, Any]] = []
for item in state.prioritized:
t = str(item.get("task", "")).strip()
p = str(item.get("priority", "中")).strip()
due = due_map.get(t, "なし")
# 期日が「今日」または「明日」なら優先度を「高」にブースト
if due in ("今日", "明日"):
p = "高"
boosted.append({"task": t, "priority": p, "due": due})
return {"prioritized": boosted}
# 一言まとめ
def summarize(state: TaskState):
prompt = (
"以下の優先度付きタスク(期日情報を含む場合あり)を踏まえ、"
"取り組み順序の指針を一言で返してください。\\n"
f"{state.prioritized}"
)
text = chat_once(
system="簡潔な日本語で1文のみ返してください。",
user=prompt,
)
return {"summary": text.strip()} # str
# グラフ構築
graph = StateGraph(TaskState)
graph.add_node("parse", parse_tasks)
graph.add_node("priority", add_priority)
graph.add_node("deadline", deadline_estimate)
graph.add_node("summary", summarize)
graph.set_entry_point("parse")
graph.add_edge("parse", "priority")
graph.add_conditional_edges(
"priority",
route_after_priority,
{"deadline": "deadline", "summary": "summary"},
)
graph.add_edge("deadline", "summary")
app = graph.compile()
# 実行
if __name__ == "__main__":
input_text = "今日の夜締め切りのレポートは絶対終わらせないと。できれば掃除と洗濯もしたい。全部できたらご褒美にアイスを買いに行こう。"
result = app.invoke({"raw_input": input_text})
print(result)
