

はじめに
学習済みのAIモデルに対して、自分たちの目的に合わせて追加の調整を行う手法のことをファインチューニングといいます。
精度が高く目的に合ったAIモデルを効率的に作成する手法としてよく使用されます。
ファインチューニング手法の一つに、PO(Preference Optimization)という、「人間の選好」を学習する方法が存在します。
今回はその中の1つである、*MPO(Mixed Preference Optimization)*についてご紹介いたします。
MPO(Mixed Preference Optimization)手法について
MPOは、マルチモーダルLLM(画像、テキストを推論対象とするLLM)において、推論性能を維持・向上させることを目的として提案された手法です。
特にCoT(Chain of Thought)を用いた学習において、従来手法では推論能力が十分に発揮できない、もしくは低下するという課題に着目して設計されています。
類似手法であるDPO(Direct Preference Optimization)との違い
MPOと同様に、選好データを用いた最適化手法としてDPO (Direct Preference Optimization) があります。
DPOは、主に最終的に生成された回答に対する選好情報を用いてモデルを最適化する手法です。
MPOと比較すると、推論の妥当性や出力を出すまでのプロセスを反映しづらい設計のため、CoTなどの複雑なタスクにおいての精度に課題がありました。
一方、DPOを含めた複数関数を組み合わせたMPOの設計では、最終出力の選好に加えて、推論の妥当性や出力を出すまでのプロセスをより積極的に反映することができ、CoT などの複雑なタスクにおいても堅牢になることが報告されています。
学習データ
MPOで用いられる学習データは、以下の3要素から構成されています。
- question : 画像およびテキストからなる入力プロンプト
- chosen : より好ましい回答(正しい結論を含む)
- rejected : 好ましくない回答(誤った結論や不十分な根拠を含む)
 出典:(Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, Jifeng Dai. "Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization."arXiv preprint arXiv:2411.10442 (2024).)
出典:(Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, Jifeng Dai. "Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization."arXiv preprint arXiv:2411.10442 (2024).)
精度について
MPOを適用したInternVL2-8B-MPOは、ベースモデルであるInternVL2-8Bと比較して推論能力が向上しています。
特に推論ベンチマークであるM3CoTで79.2ポイントのスコアを達成し、ベースモデルより22.2ポイント、SFT(教師ありファインチューニング)モデルより11.4ポイント上回りました。
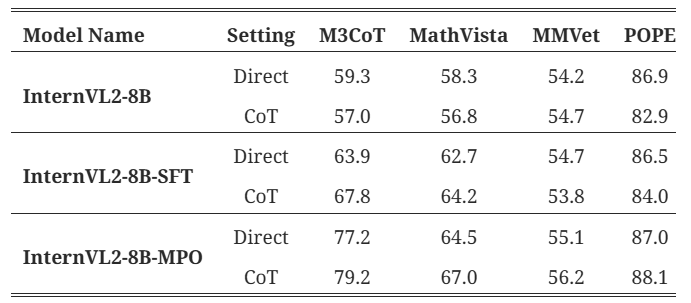 出典:(Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, Jifeng Dai. "Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization."arXiv preprint arXiv:2411.10442 (2024).)
出典:(Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, Jifeng Dai. "Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization."arXiv preprint arXiv:2411.10442 (2024).)
参考論文
- Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
最後に
最後まで読んでいただき、ありがとうございます。
私たちのサービスでは、データ分析基盤の構築やDeep Learningモデル開発、MLOps構築、生成AIモデル開発等データに関わるプロジェクトを伴走支援しております。
データ分析基盤開発やデータのAI活用経験のある方や、興味のある方は、ぜひご応募ください。
あなたのスキルと情熱をお待ちしています。
新卒、キャリア募集しています!
