

このブログの投稿者である私は、かつてAIエンジニアになったものの、それまでAI開発の経験がありませんでした。
そこで、様々なモデルについて自己学習を行い、理解を深めてきました。
今回は、その中から LSTM という自然言語処理モデルを用いた実験を紹介いたします!
アイスブレイク
突然ですが、ここで ひらめき問題 です。
「?」に入る海の生き物は何でしょう?
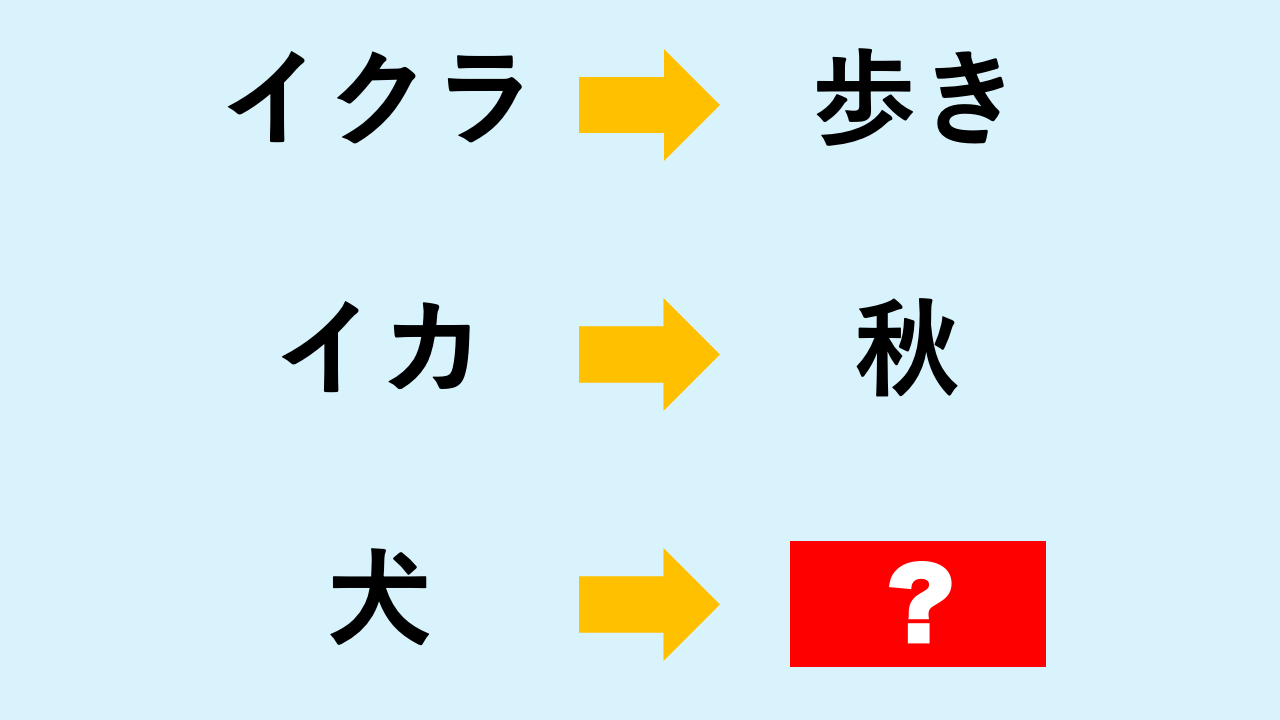
正解まで…
10
9
8
7
6
5
4
3
2
1
正解は 「うに」 でした!
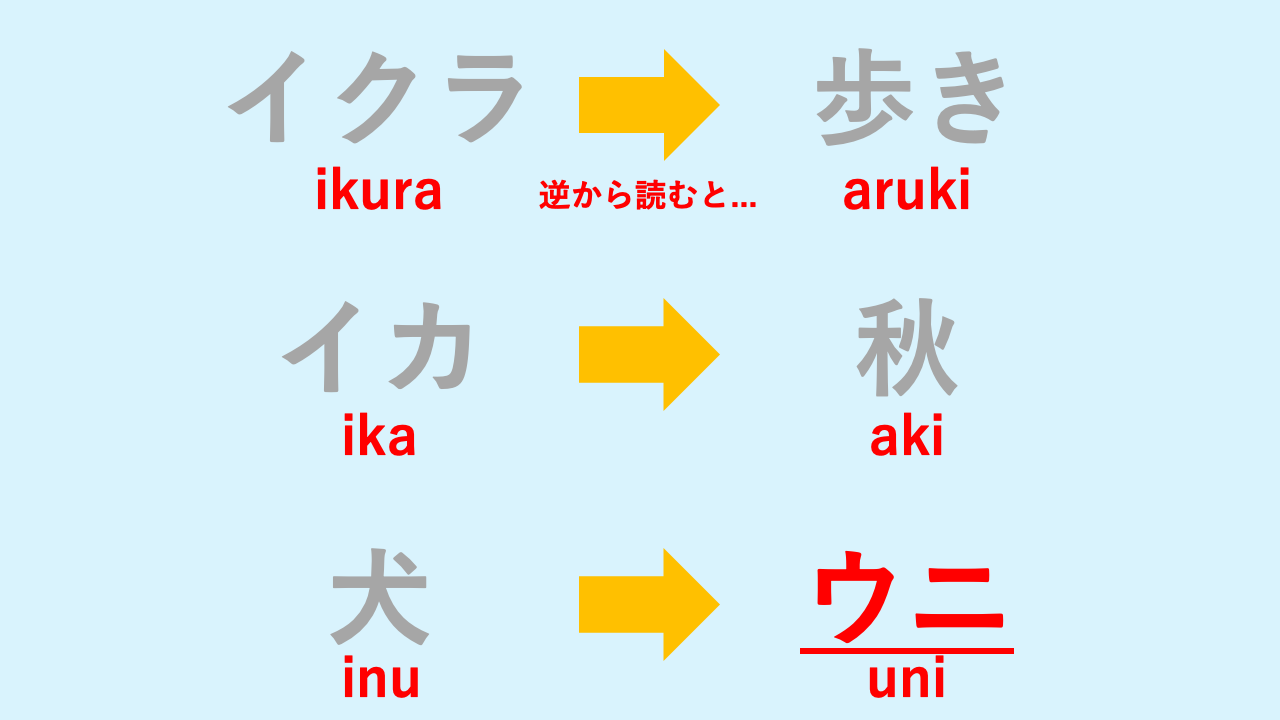
先ほどの問題のルールは、 「入力文字列をローマ字変換 → 逆順にする → 日本語に戻す」 というものでした。
今回は あえてローマ字変換を一切行わず 、直接正しい文字列を出力するAIモデルを作成しました。
そして、使用したモデルは、 LSTMを用いたSeq2Seqモデル です。
LSTMとは
LSTM (Long Short-Term Memory) は、従来のRNNが苦手とする「長期依存関係」の問題を解決するために開発されたニューラルネットワークの一種です。
LSTMは、短期記憶と長期記憶の両方を持ち、離れた位置にある情報同士の関連性を効果的に捉えることができます。
- 隠れ状態:短期記憶として、直近の情報を保持
- セル状態:長期記憶として、より長い文脈を管理
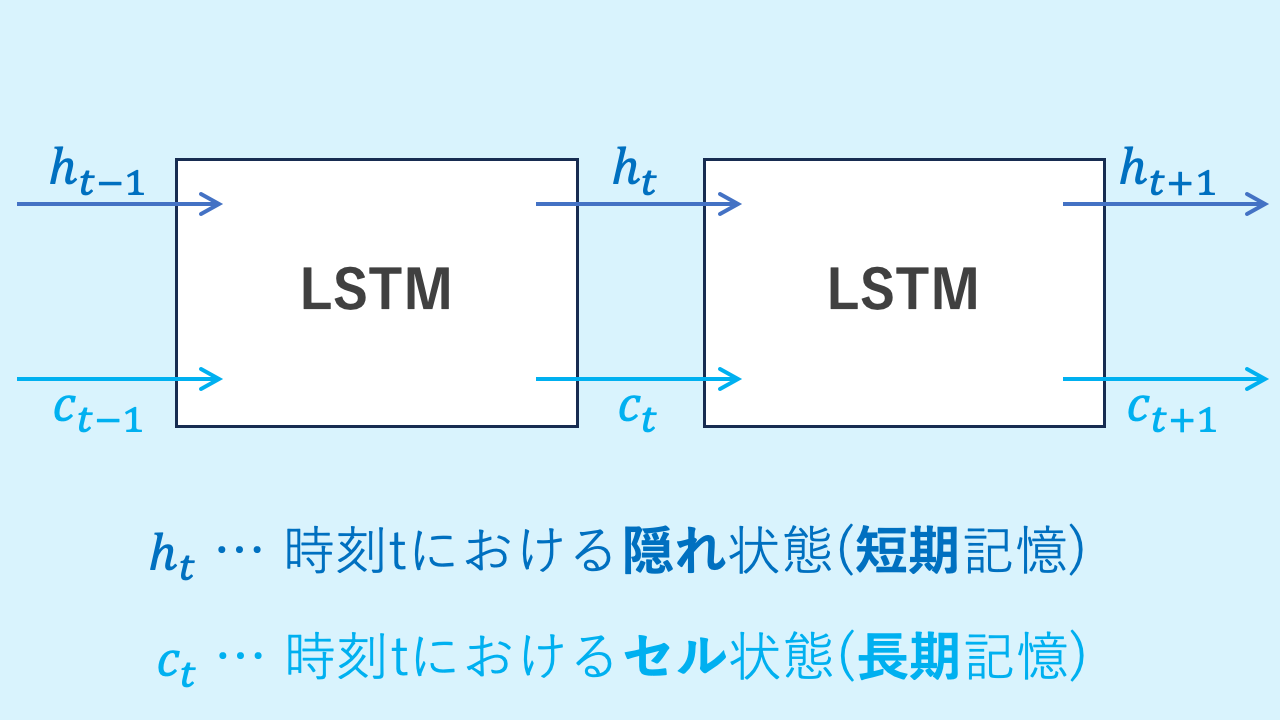
この仕組みにより、離れた位置にある情報同士の関連性を効果的に捉えることが可能です。
なお、非常に長いシーケンスでは記憶が途切れるため、最近はTransformerが主流です。
しかし、今回の実験ではシンプルなLSTMでどこまでできるかを検証しました。
モデル構築と学習データ
データ
- 入力文字列Aと出力文字列Bのペア … 10,000個(被り無し)
- 学習用:8,000ペア
- テスト用:2,000ペア
- 各文字列の長さはランダムに3~8文字
トークン表現
- 合計45種類
- :文の終わり
- :空白
- :文の始まり
- ひらがな42文字(※「し(shi)」「ち(chi)」「つ(tsu)」「ふ(fu)」を除外)
- 上記の順に番号を割り当て、トークンを管理
通常、LSTMにテキストを入力する際には、各文字を埋め込みベクトルに変換して次元削減を行います。
しかし、今回はあえて one-hotベクトル を使用しました。
200エポックの学習で、テスト精度は 約93% を達成しました。
(学習時間約5分)
内部状態の可視化と解析
※以降登場するグラフの縦軸の値には明確な意味はありません。
値の大小のみに注目していただけますと幸いです。
以下に例として、入力「いくら」(出力は「あるき」)のものをお見せします。
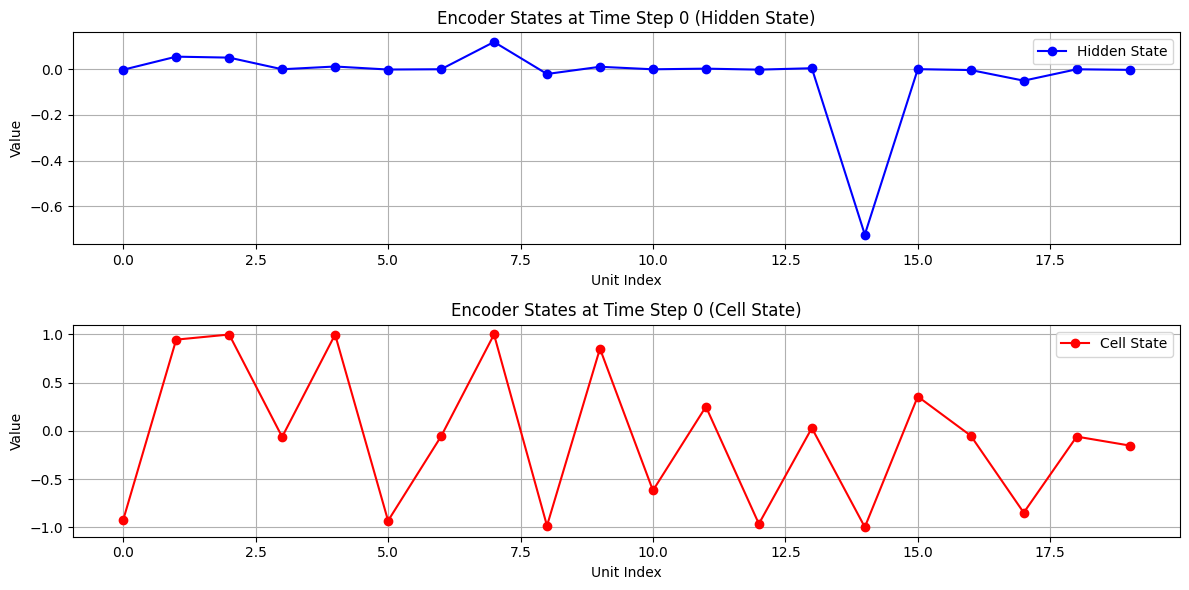
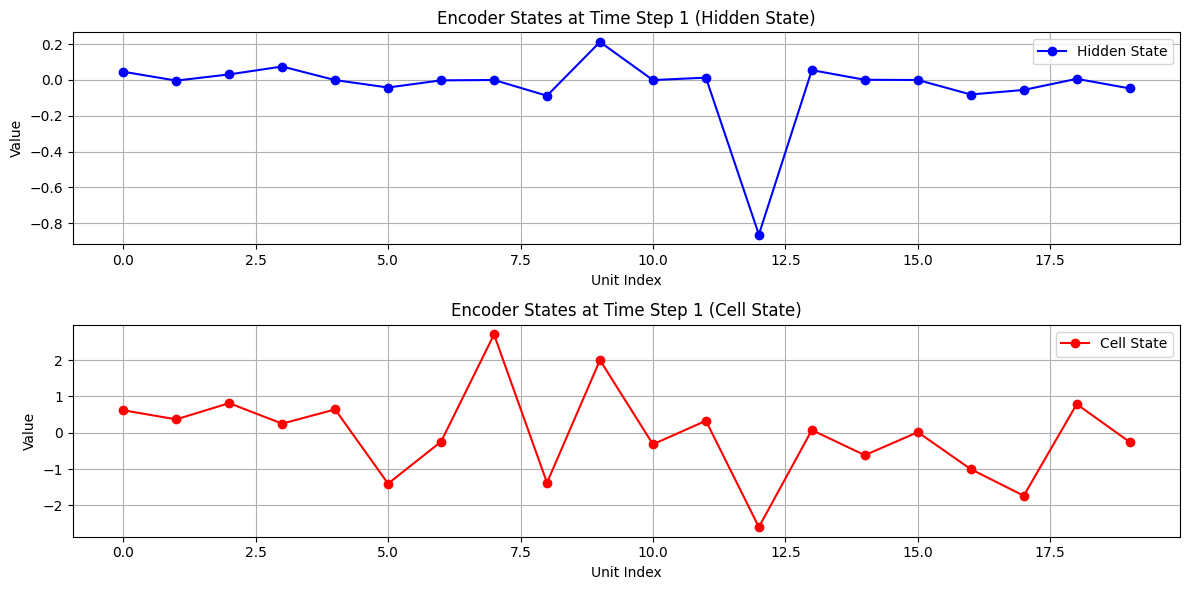
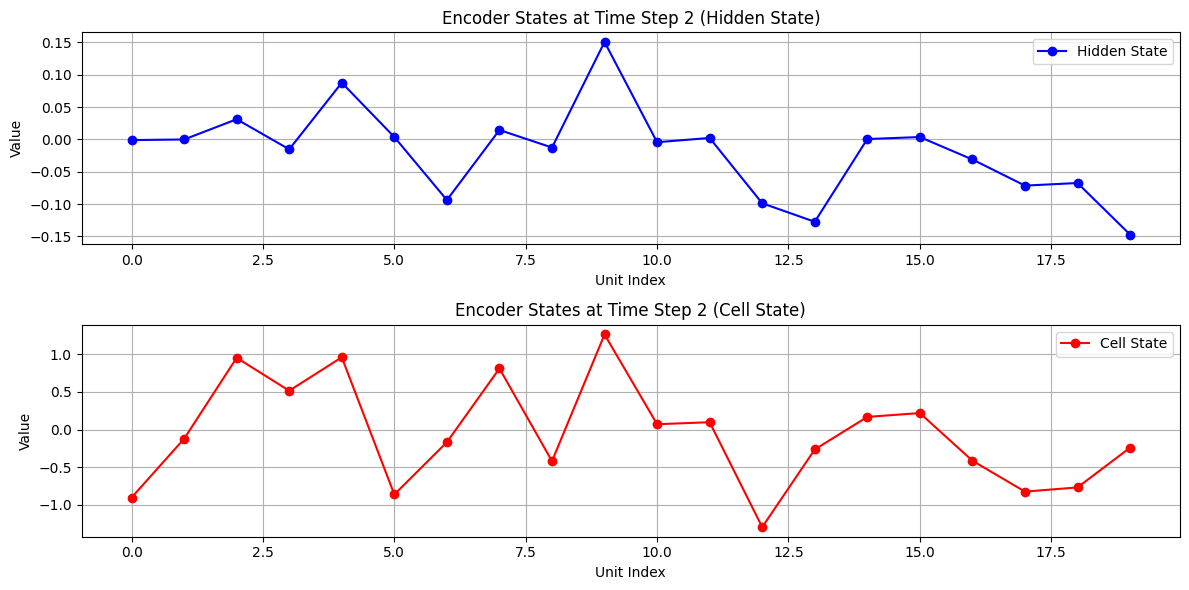
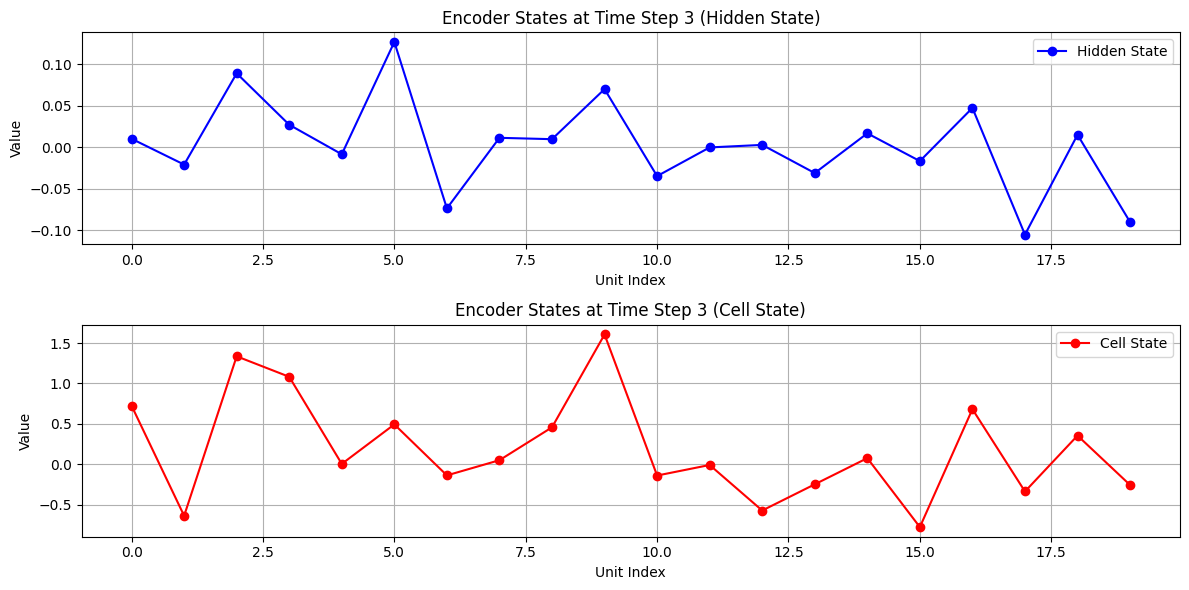
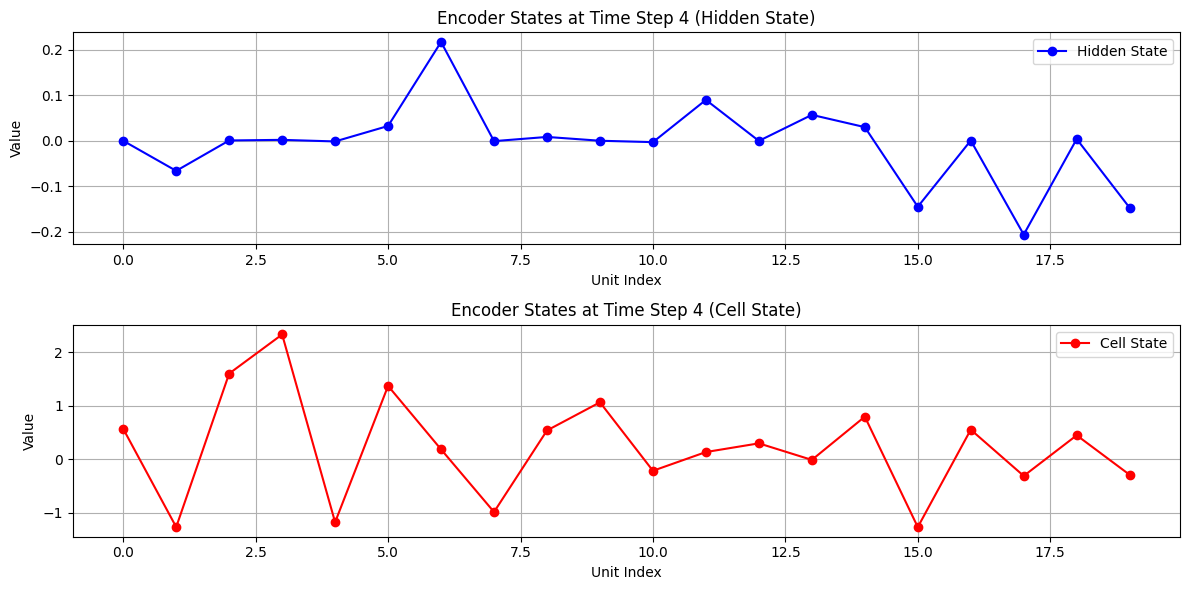
エンコーダ側の可視化
入力:, い, く, ら,
隠れ状態(青)とセル状態(赤)の変化を可視化しています。
各文字がどのように記憶されていくかを視覚的に把握できます。
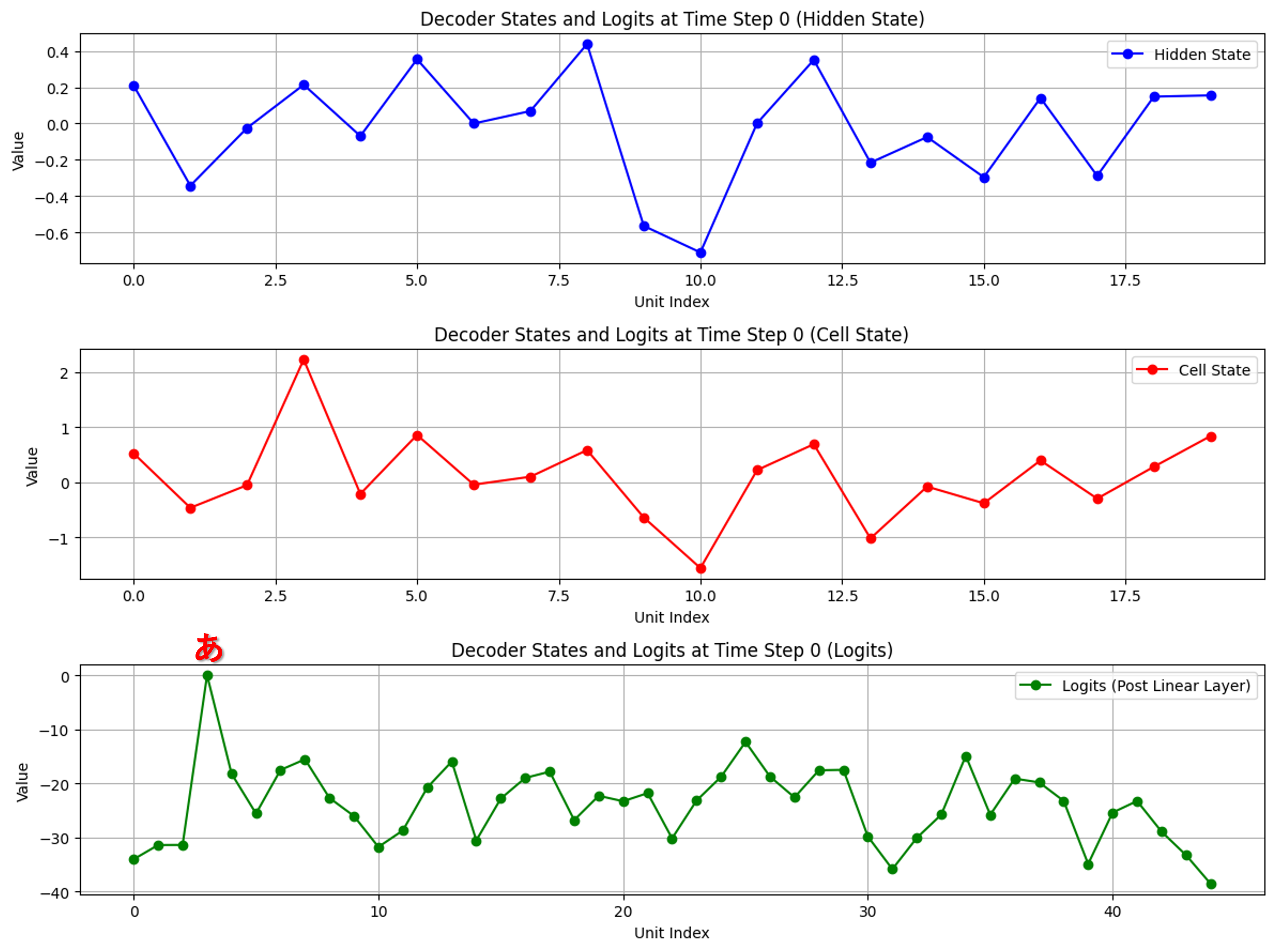
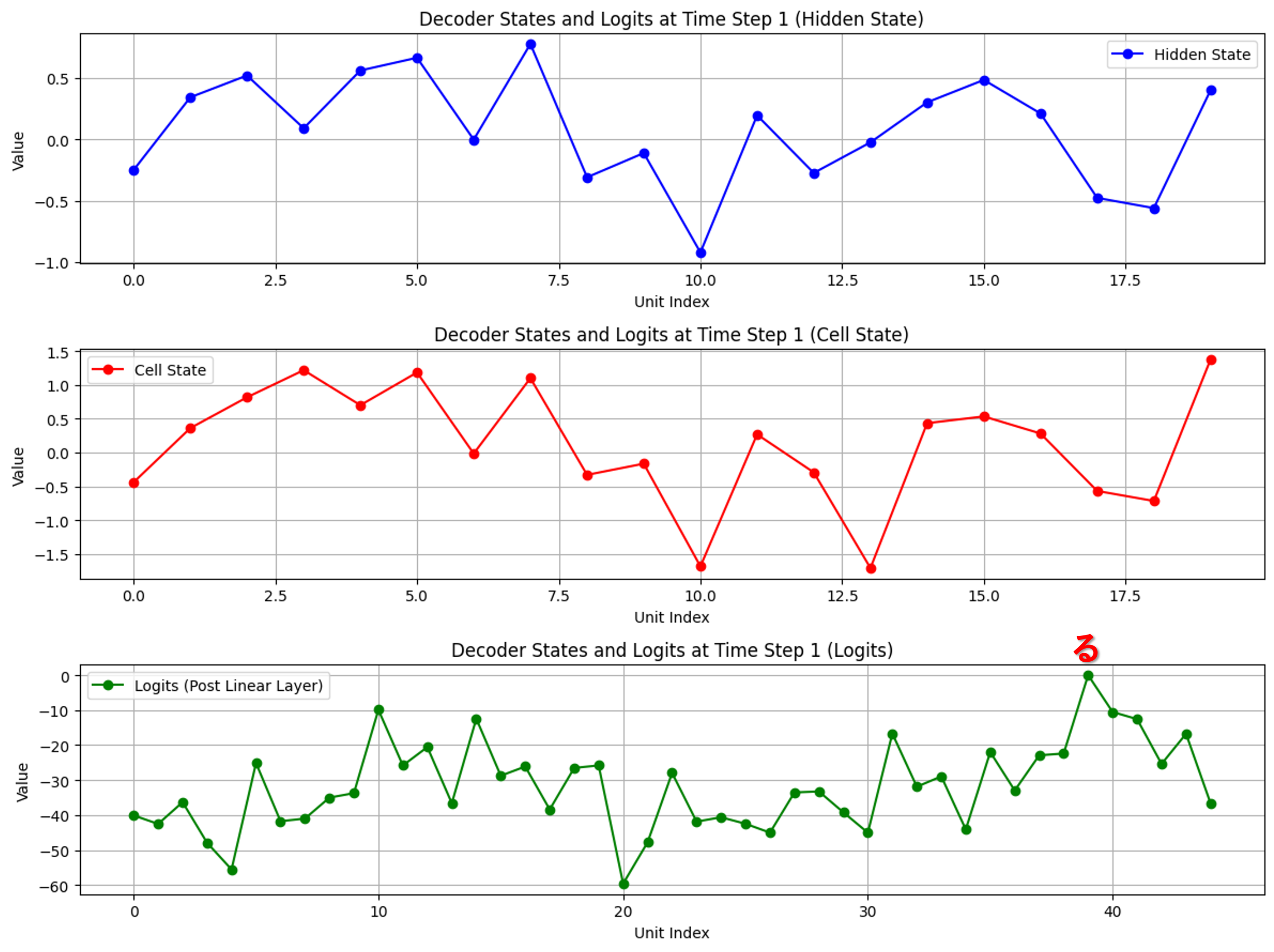
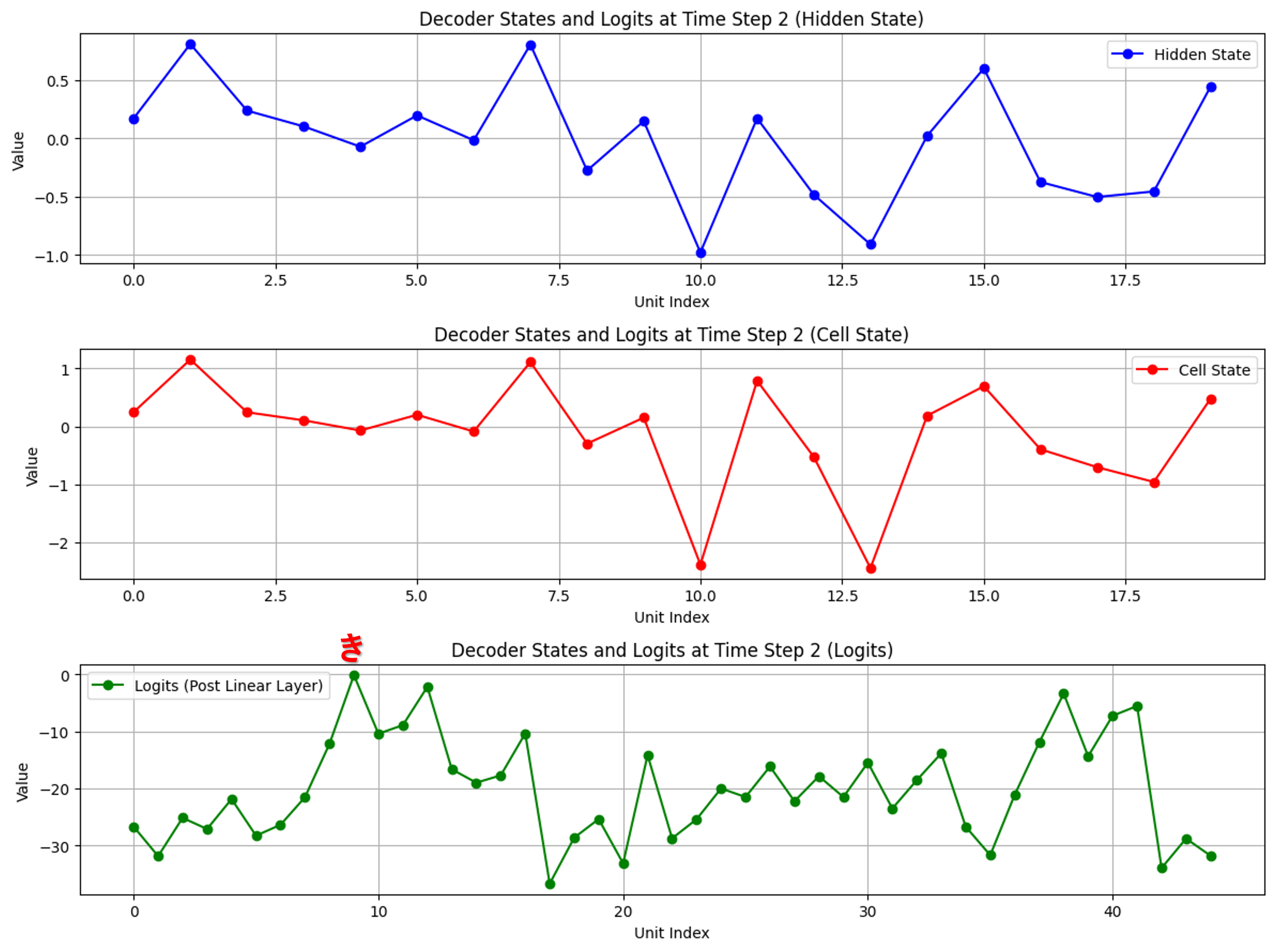
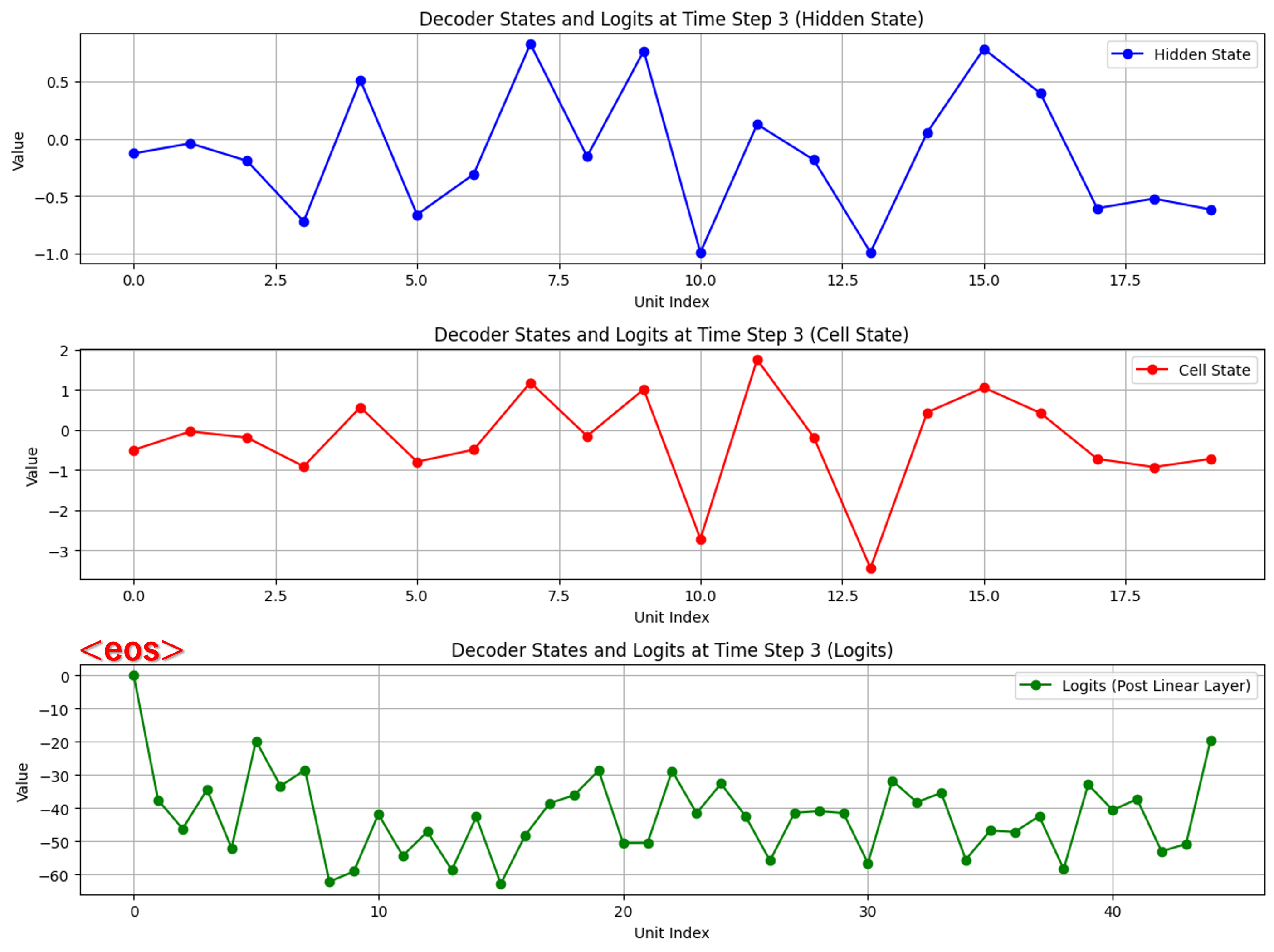
デコーダ側の可視化
出力過程:各出力時に隠れ状態(青)、セル状態(赤)、トークン確率分布(緑)を可視化
各出力時、確率分布で最も高い値のトークンが選ばれていることを確認できます。
そして、文字が出力されるごとに、隠れ状態とセル状態の形が近づく様子が見受けられます。
隠れ状態からトークン特徴を抽出
トークン確率分布は、隠れ状態を線形変換したものを利用して求めています。
つまり、隠れ状態の各要素がどのトークンの情報をどれだけ持っているかを見ることができると考えられます。
手法:
隠れ状態は20次元なので、各要素が1で他が0となるone-hotベクトルを20パターン作成しました。
それぞれのone-hotベクトルを線形変換した後のベクトルを可視化しました。
例1
インデックス12のみが1で他が0のone-hotベクトル
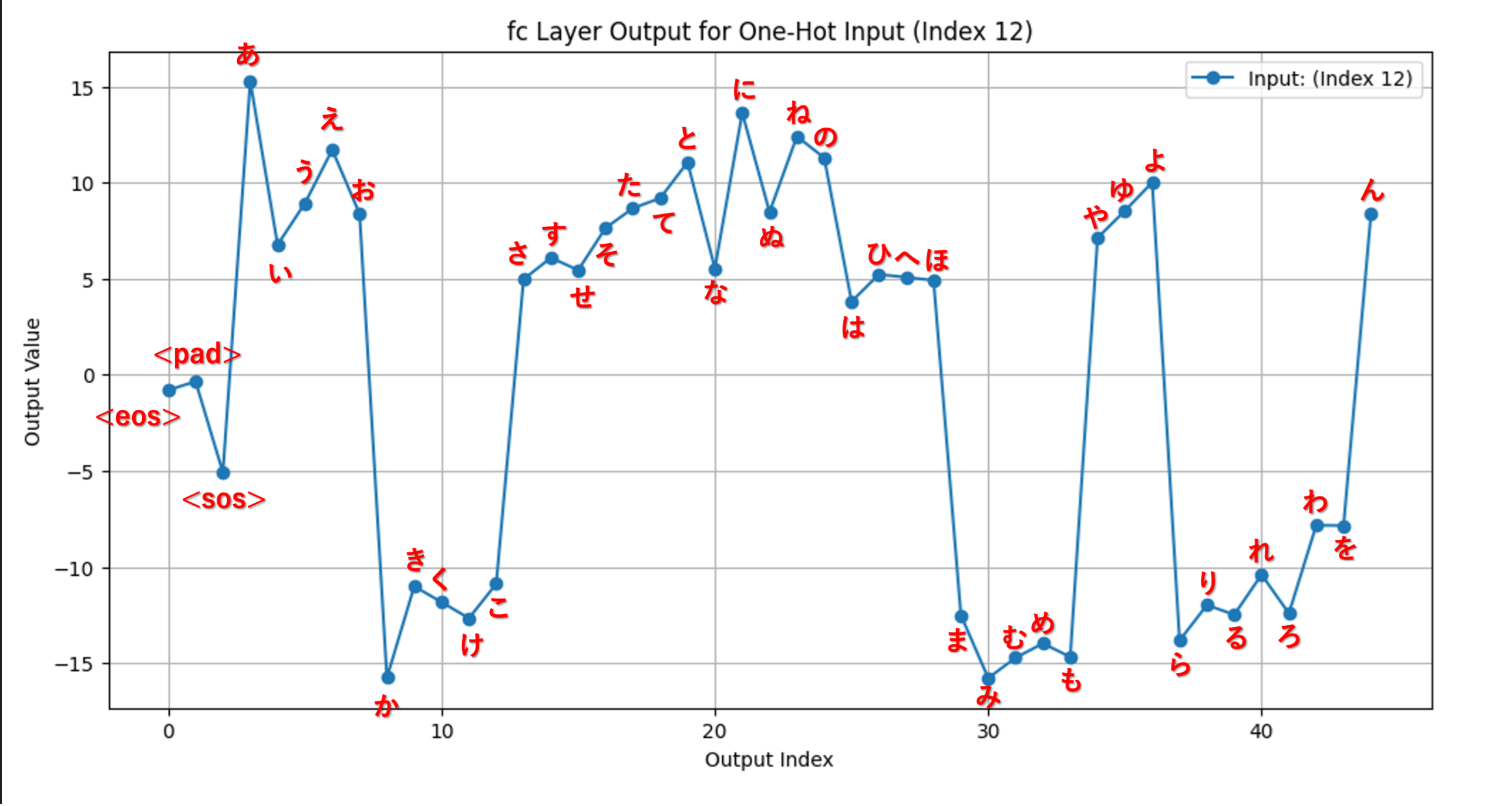
グラフから、あ行、さ行、た行、な行、は行、や行、んに対してはポジティブ、か行、ま行、ら行、わ行にはネガティブな傾向を示す、つまり 子音の情報 が学習されていることが確認されました。
【例2】
インデックス0のみが1で他が0のone-hotベクトル
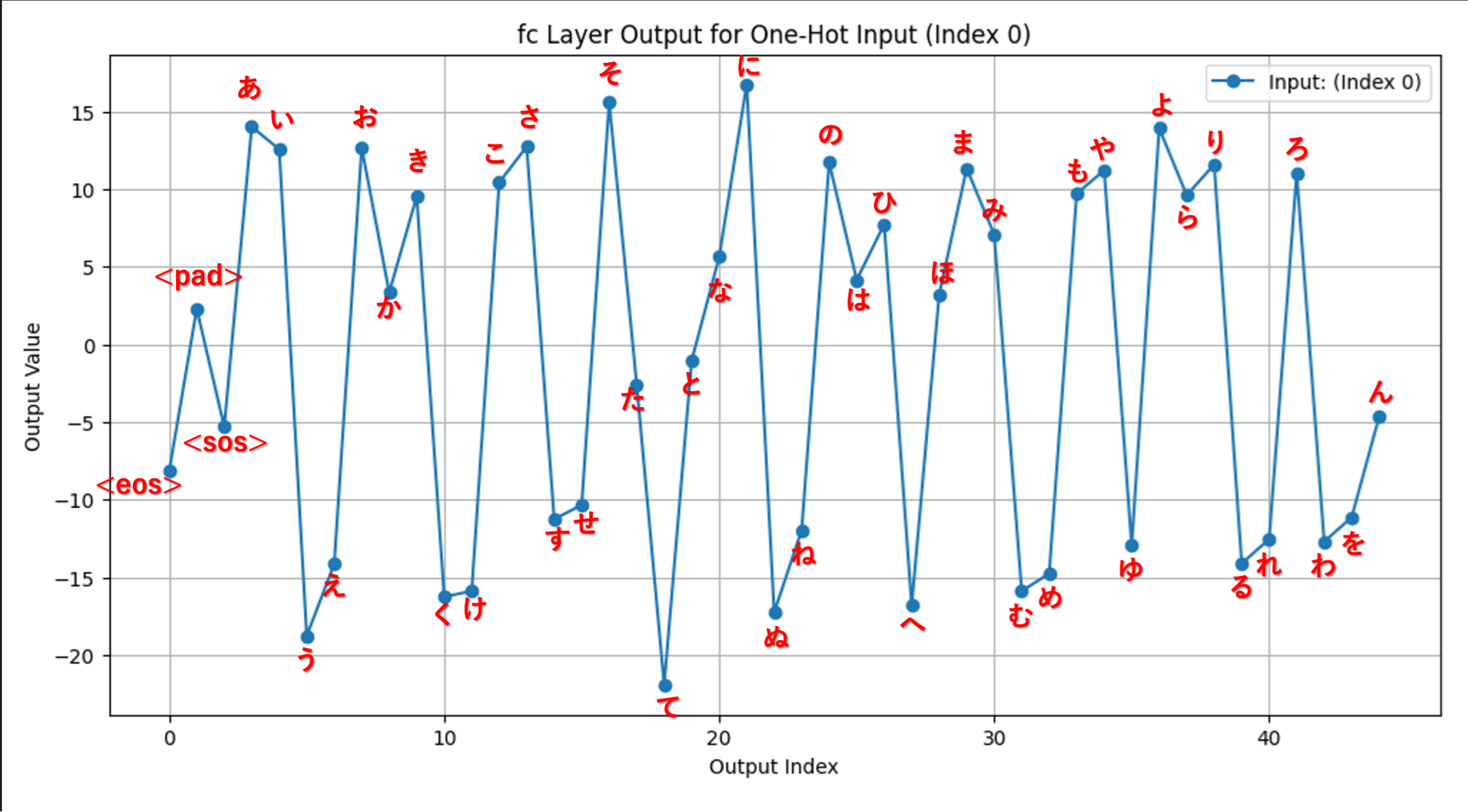
グラフから、ア段、イ段、オ段がポジティブ、ウ段、エ段がネガティブな傾向を示し、 母音の情報 が学習されていることが確認されました。
まとめと今後の課題
今回、ローマ字変換をあえて経由せず直接出力を導くAIモデルを構築し、シンプルながら 約93% の精度を実現でき、 子音・母音の関係性を学習できている ことがわかりました。
課題
長い文字列のデータ数が少なかったのもあり、シーケンスが長くなると、初期の情報が徐々に失われ、出力が乱れる傾向が見られます。
例:入力: いこよをらりい → 出力: いいらろをよき(正解通り)
入力: いこよをらりいけ → 出力: えきありよろをれ(3,4文字目で母音がずれ、その後の出力が乱れる)
入力: いらすさよさらう → 出力: うあらそやすさり(正解通り)
入力: いらすさよさらうみ → 出力: いむあらそやせそる(7文字目以降で母音がずれる)
このように、長いシーケンスへの対応が課題です。
以上が私の自己学習の紹介でした!
ただ勉強するよりも、自身が好きなものと絡めて学ぶことで、インプットとアウトプットが捗るのでとてもおすすめです!
他にも自己学習関連の記事はありますので、もしご興味あれば、他の記事も見てくださると嬉しいです!
最後まで読んでくださり、ありがとうございました。
