

WindowsとMacでは、ファイルシステムはどちらもUnicodeを採用していますが、Unicode正規化形式の違いから、同じに見えても内部のコードポイント、バイト配列が異なる状態になるケースがあります。どういったケースで起こるのかと、起こった場合の問題点について、簡単に紹介いたします。
※わかりやすくするために、細かい話は省略しております。
Unicode正規化形式とは?
Unicodeには文字の合成、分解という概念があり、合成済み文字と、基底文字+結合文字の組み合わせによる結合文字列を、それぞれ変換して表現が可能です。
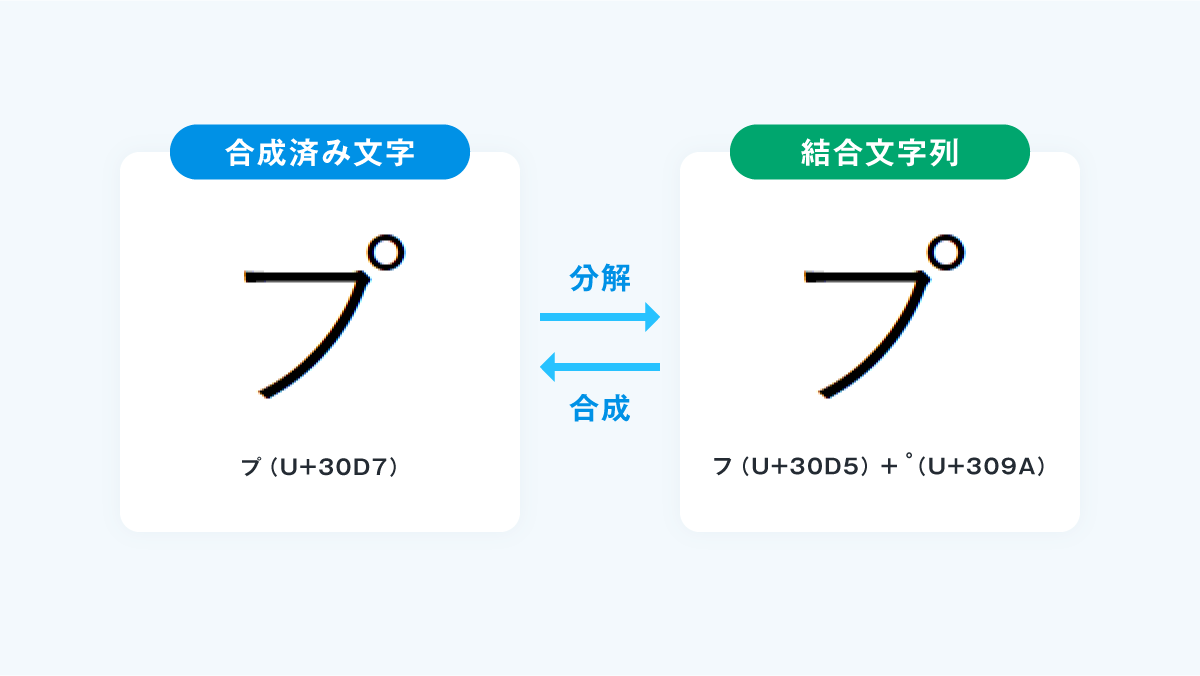
日本語ではひらがな/カタカナの濁音/半濁音などが該当します。Unicode正規化形式とは、一定の方式で合成、分解する形式の事を指します。
Unicode正規化形式は4つあり、そのうち2つを紹介します。
-
NFC(Normalization Form Canonical Composition)
→文字を合成します -
NFD(Normalization Form Canonical Decomposition)
→文字を分解します
WindowsとMacの違いとは?
MacのファイルシステムはUnicode正規化としてNFD(正確にはNFDの亜種)を採用しており、ファイル名やフォルダ名は結合文字列が使用されます。WindowsのファイルシステムはUnicode正規化を行っていないため、IMEなどで入力される文字をそのまま使用します。結果として合成済み文字が使用されます。
このため、同じファイル名でも、コードポイントレベルで違う文字列になっているケースが生まれます。
たとえば、「サンプル.txt」というファイルを作成した場合は以下のようになります。

困ること
プログラム上にて、Windows/Macでそれぞれ作成したファイル名、ファイルパスの文字列比較を行う場合などに、「見た目が同じ文字列、ファイル名だが比較結果が一致しない」という判定結果になることがあります。マルチOSに対応しているようなソフトウェアで、しばしば問題が起こったりいたします。
Macで作成したファイルをWindowsに移動した場合などに、見た目は同じだが別扱いされる場合もあります。
簡単ではありますが、OSによるファイルシステムの違いから、見た目と中身の違うファイル名が作られるケースについての説明となります。
このようなケースで文字列比較をするのであれば、それぞれの文字に同じUnicode正規化をかけて比較する…といった工夫が必要になります。
