

概要
ローカル環境で大規模言語モデル(LLM)を利用する際、「せっかく使えるようにしたものの生成速度も遅く、あまり使い勝手が良くない…。」といった問題はよくあるかと思います。
もちろんGPUメモリ数などのリソース的な限界もあるかと思いますが、今回はvLLMを用いて限られたマシンリソースの中でLLMの推論速度を向上させる方法を紹介します。
また、VS Code拡張機能のContinueというツールがVS Code上でチャットインターフェースを用いてローカルLLMを 利用する上で非常に便利なのでこちらを使ったAIコーディング環境の構築についても併せてご紹介させていただければと思います。
vLLMとは?
vLLMとは、大規模言語モデル(LLM)の「推論」(実行)を高速かつ高効率で行うためのオープンソースライブラリです。LLMを用いて推論を行う際のGPUメモリの使用が最適化されるように設計されており、ローカル環境でGPUメモリを効率的に使ったLLM推論が可能となっています。
以下が主なvLLMの特徴です。
1. 高速な推論
vLLMではPagedAttentionという仕組みを取り入れることによりGPUメモリ使用を効率化し、 高スループットなLLM推論を実現しています。
2. 利用可能なローカルLLMが豊富
HuggingFaceで公開されている多くのモデルをサポートしており、また複数の量子化手法にも対応しているため少ないGPUメモリで選択できるモデルが多いこともメリットの一つです。
3. OpenAI API互換サーバーの構築
vLLMではOpenAI API互換のサーバーも提供しており、vllm serveコマンドを用いることでローカルLLMのAPIサーバーを簡単に立てることができます。生成AI系のライブラリではOpenAI APIクライアントを公式でサポートしているものも多く、それらをローカルLLMでも同様に使うことができるのもメリットです。
本記事でも上述したvllm serveコマンドを用いてAPIサーバーを立てていきます。
Continueとは?
ContinueはVS Code上でのAIコーディングを支援するための拡張機能です。ローカルLLMをはじめAzure OpenAIやAmazon Bedrockで利用可能な基盤モデルを用いて簡単にAIコーディング環境を VS Code上で構築することができます。
特にローカルLLMを使用したAIコーディング環境はデータが学習される心配もないため、非常に魅力的だと思います。ContinueではOllamaがサポートされており、一般的にローカルLLMを使用する場合、Ollamaで立てたローカルLLMのAPIサーバーを利用する形式が主流ですが、OpenAI API互換のサーバーを立てることが出来るvLLMも実はサポートされており、 vLLMを用いることでより大規模な言語モデルを高スループットで扱えるAIコーディング環境を構築することが出来ます。
ローカルLLM利用環境構築手順
それでは本題のvLLMとContinueを組み合わせたローカルLLM利用環境の構築に入っていきます。 vLLMの利用方法はいくつかありますが、今回はPythonのvenvで仮想環境を構築してその中でvLLMを用いてローカルLLMのAPIサーバーを立てていきます。
検証環境
- OS: Linux Ubuntu22.04
- GPU: NVIDIA RTX6000 Ada
Pythonの仮想環境を作成
venvコマンドを用いてPythonの仮想環境を作成し、有効化します。
# Pythonの仮想環境を作成
python -m venv vllm_env
# 仮想環境を有効化
# Windowsの場合
vllm_env\Scripts\activate
# macOS/Linuxの場合
source vllm_env/bin/activate
pipを用いてvLLMをインストール
pipのバージョンを最新に更新しvLLMライブラリをインストールします。
# pipを最新バージョンに更新
pip install --upgrade pip
# vLLMをインストール
pip install vllm
serveコマンドを用いてAPIサーバーを立てる
vllm serveコマンドでローカルLLMのAPIサーバーを起動します。今回はGPT-OSSの20Bモデルを使用します。
# サーバーを起動
vllm serve openai/gpt-oss-20b
実行するとローカルにモデルがダウンロードされ、完了した後にサーバーが起動されます。また、サーバー起動時に使用できるオプションも多く、これらを用いて自身の環境により最適化したAPIサーバーを構築することが出来ます。
使用できるオプション(一部抜粋)
--max-model-len
モデルに入力するプロンプトと出力の合計トークン数の最大値を指定する。この最大値はデフォルトでは各モデルの設定に依存した値が設定されますが、値が大きくなればなるほどAPIサーバーが事前に 確保するGPUメモリ量も増え、場合によってはGPUメモリエラーが起きます。長いコンテキストを扱わない場合はこの値を小さめに設定しておくことでGPUメモリの使用量を抑えることが出来ます。
--gpu_memory_utilization
APIサーバーが事前に確保するGPUメモリ量をGPU全体で利用可能なメモリ量の割合で指定する。例えば、GPUで利用可能なメモリ量が48GiBでこちらの値を0.5(50%)とした場合、事前に確保されるGPUメモリの最大値は24GiBとなります。ただし、こちらのオプションを指定した場合にモデルの重み自体のサイズが確保したGPUメモリ量を超える場合はGPUメモリエラーが起きるため注意が必要です。
--quantization*
モデルの重みを量子化するためのオプションです。重みを量子化することで必要なGPUメモリ量を減らすことが出来、より大きいサイズのモデルを扱うことや推論速度の向上が期待できます。ただし、重みの量子化を行うことで推論精度は劣化するため注意が必要です。
起動したAPIサーバーはOpenAI API互換のサーバーとなっているため、以下のようにOpenAI APIクライアントを使用した推論リクエストが可能です。base_urlには皆さんの環境で作成したAPIサーバーのエンドポイントを指定してください。
サンプルコード
from openai import OpenAI
# ローカルLLMのAPIエンドポイントでクライアントを作成
client = OpenAI(api_key='', base_url='http://0.0.0.0:8000/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{ 'role': 'user', 'content': "日本で一番高い山は?",
temperature=0.0,
max_completion_tokens=128,
)
# 結果を出力
print(response.choices[0].message.content)
出力結果
日本で一番高い山は「富士山(ふじさん)」です。標高は約3,776 メートルです。
Continueをインストール、設定する
VS Code拡張機能からContinueを検索し、インストールします。
インストールが完了すると左端のメニューバーにContinueのアイコンが追加されます。
 VS Codeのスクリーンショット画像
VS Codeのスクリーンショット画像
Continueのアイコンをクリックするとチャットインターフェースが表示されます。
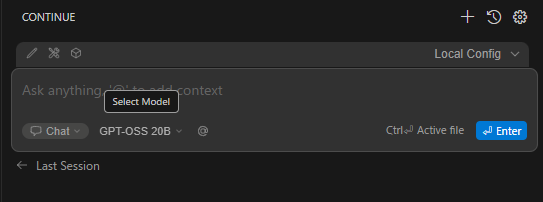
画像右上にある「Local Config」という部分をクリックするとContinueでLLMを使用するための設定一覧を確認することが出来ます。
「Local Config」の横の歯車マークをクリックすると設定を編集できるので、今回はこちらを編集していきます。
 VS Codeのスクリーンショット画像
VS Codeのスクリーンショット画像
「Local Config」の横の歯車マークをクリックすると開かれるYAML形式のファイルのmodels部分を以下のように編集します。
models:
- name: GPT-OSS 20B
provider: vllm
model: openai/gpt-oss-20b
apiBase: http://0.0.0.0:8000/v1
roles:
- chat
- edit
- apply
保存後以下のように設定したモデル名が表示されて入れれば成功です。
 (VS Codeのスクリーンショット画像)
(VS Codeのスクリーンショット画像)
実際に質問を入れてみると以下のように回答が得られます。
 VS Codeのスクリーンショット画像
VS Codeのスクリーンショット画像
まとめ
今回はvLLMとContinueを組み合わせた高スループットなローカルLLM利用環境の構築について共有させていただきました。vLLMを利用することでHugging Face Transformer等を用いるよりも高スループットなローカルLLM推論を実現できます。推論速度に難を感じている方はぜひ使用を検討してみてください。
また、今回Continueに関してはチャット機能のみの紹介となりましたが、チャット機能以外にもTabキーでのコード補完や、 MCPサーバーとの連携など様々な機能が搭載されており、ローカルLLMでのAIコーディングを支援する強力なツールとなっています。こちらも是非活用してみてください。
最後に
最後まで読んでいただき、ありがとうございます。私たちのサービスでは、データ分析基盤の構築やDeep Learningモデル開発、MLOps構築、生成AIモデル開発等データに関わるプロジェクトを伴走支援しております。データ分析基盤開発やデータのAI活用経験のある方や、興味のある方は、ぜひご応募ください。あなたのスキルと情熱をお待ちしています。
