

はじめに
SKYDIV Desktop Clientの初期バージョンは、大人数で開発が始まりました。参加メンバーはベテランから初心者まで幅広く、開発テーマの一つとして、均一な品質を担保し、可読性を確保することがありました。
- 誰が書いても同じような実装にする。
- 誰が書いても安全な実装にする。
アプリケーション(UI)開発では、フレームワークを用意し、実装ルールや制約をチームメンバーに浸透させました。これらの工夫や取り組みについて一部ご紹介します。
取り組み内容
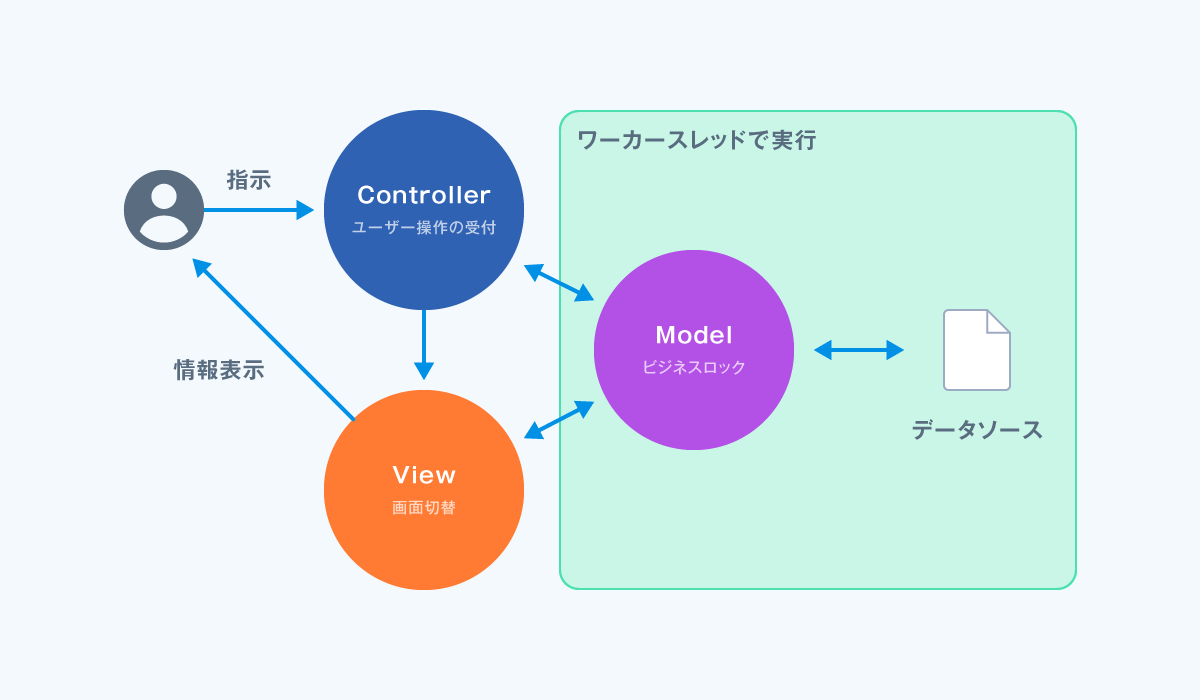
Step.1 ユーザー操作(ユーザーインターフェース)とデータ操作(ビジネスロジック)の完全分離
ユーザーの操作感を阻害しないように、メインスレッドではユーザー操作と画面更新のみに留め、データ操作(取得、更新など)はすべてワーカースレッドで実行するようにしました。いわゆるMVCモデルの概念をベースにしたフレームワークを使用しました。
それまでのアプリケーション開発の課題の一つとして、メインスレッドで時間のかかる処理を行い画面が固まる問題がありました。ベテラン開発者であれば、時間のかかる処理をワーカースレッドで実行させることは当然のことかと思いますが、初心者には判断できないケースもあります。時間がかかるというような状況によって変化する条件は省いて、処理内容で分離するようなルールを設けました。
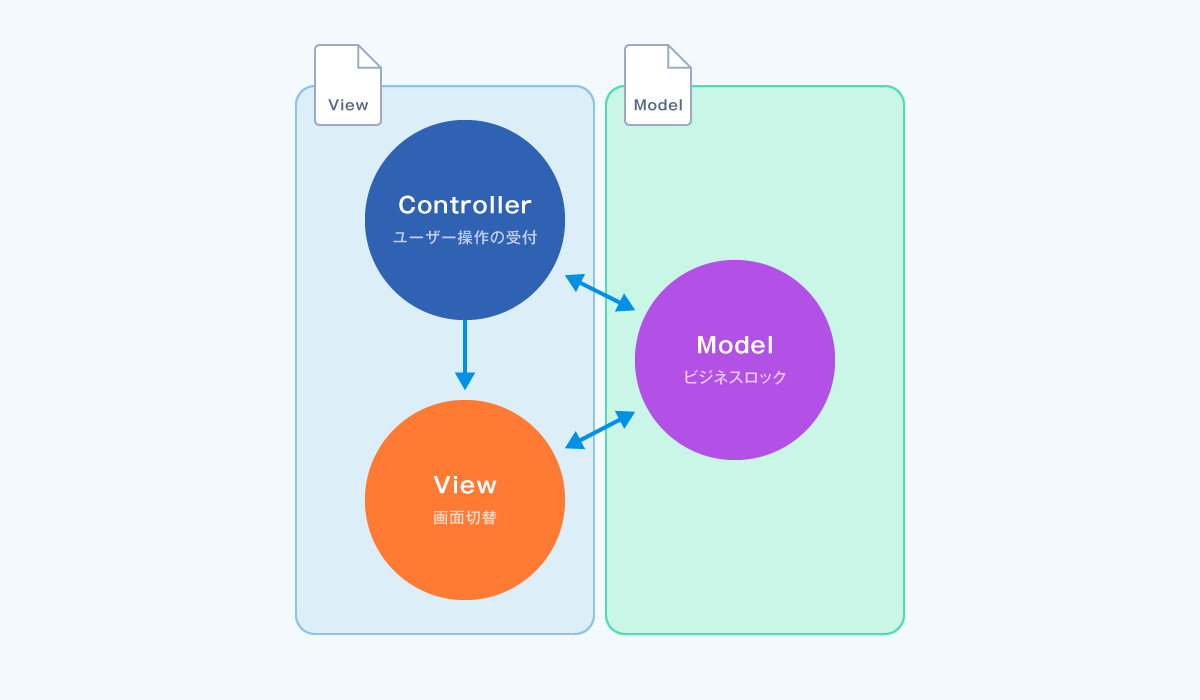
Step.2 ファイルレベルでの分離
ユーザー操作層と、データ操作層のコードファイル単位で完全に分離することを目指しました。処理を見て、ユーザー操作かデータ操作かの区別はできますが、その処理がどのスレッドで動作しているかはすぐに判断できないこともあるかと思います。ファイルを分離することで、その実装がどのスレッドで動くものかが一目瞭然となります。
Step.3 フレームワークでのサポート
方針を決めたので、ユーザー操作層の基底クラスと、データ操作層の基底クラスを用意し、それぞれを派生させたクラスをセットで作成する運用にしました。それぞれ、SampleViewや、SampleModelというように、ファイル名(クラス名)で、どのスレッドで動作する処理かが明確になります。また、ワーカースレッドの処理単位となるタスクの基底クラスと、タスク管理クラスもフレームワークとして用意しました。
データ操作層の関数をコールするとタスクを生成し、タスクをタスク管理クラスに登録することで、ワーカースレッドで処理が実行されます。処理結果をユーザー操作層に通知すると、メインスレッドで受信部が呼び出されるようにしました。
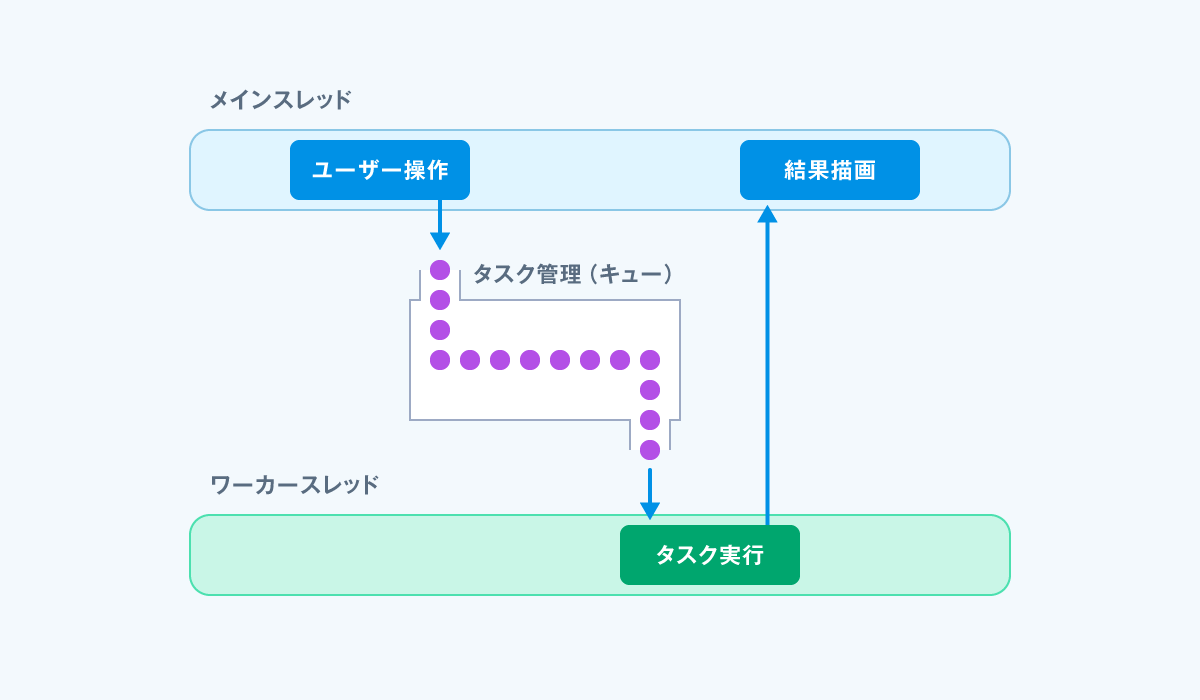
このように、各実装者は、スレッドの切替を実装することなく、(タスク登録の部分はメンバーに書いてもらう必要がありましたが)自動的に適切なスレッドで実行される仕組みにはできました。
Step.4 細かな工夫
ワーカースレッドのスレッド数は基本1本としました。アプリケーションにもよるかと思いますが、今回開発したものはマルチスレッドで処理しなければならないシーンがほとんどありませんでしたので、ワーカースレッドは1本としました。マルチスレッド化による恩恵よりも、マルチスレッド化による予期せぬ不具合を排除しようと考えました。
※複数スレッドを使った処理も一部はあります。
ワーカースレッドで実行するタスクからの通知はObserverパターンを使いましたが、通知先のオブジェクト(ユーザー操作層のクラス)は弱参照で登録するようにしました。弱参照にすることで、ライフサイクルも独立し、分離レベルが向上しました。
Step.5 メンバーへの啓蒙
当たり前ですが、方針やフレームワークを準備してもメンバーへの啓蒙がないと意図通りに使ってもらえない部分があります。開発序盤ではサンプルになるコードも少ないため、シーケンス図なども使って説明したり、主なメソッドの使い方などについて啓蒙活動を積極的に行いました。
まとめ
SKYDIV Desktop Clientの開発で実践した大規模開発における品質および可読性確保についての取り組みを紹介しました。
以上のような取り組みにて、当初の目的を達成することができました。今ではサンプルになる実装も増え、機能追加の際も効率的に実装できるようになっていますし、機能拡張や不具合対応で、知らないコードを読む際も、同じような実装になっているため、すぐに流れを理解することができます。
これらの取り組みを通じて、SKYDIV Desktop Clientの開発を効率よく進めることができ、品質向上にもつながっていると思います。
今後もこのような取り組みを継続し、さらなる品質向上と効率化を目指していきます。
