

皆さんは、LLMでPDF内の表を読み込ませたとき、人間が読み取れる事をちゃんと読み取ってくれない、という経験はありませんか? 特に表中のセル結合箇所でうまく読み取れない。そんな経験が私にはありました。 本記事では、私が実業務で直面した上記の課題への対処法を紹介します。
結論から言いますと、表だけをLLMに投げるよりも、表と表から抽出したテキスト情報をセットで投げた方がLLMの精度向上が見られます。
以下に実際の再現結果や手順等を記載します。 ※記載した検証データ・生成結果は、実業務の検証データ・生成結果をイメージしたものです。
検証データ
PDF内に、セル結合が複数箇所ある表が記載されていることを想定します。
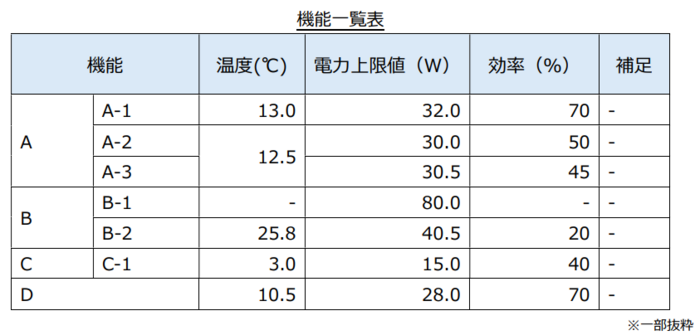
課題
実業務ではClaude 4を用いて生成を行いました。 まずは何も工夫せずに、検証データをそのままClaude 4に投げた結果を以下に記載します。
 プロンプト
プロンプト
 生成結果イメージ
生成結果イメージ
セル結合箇所がうまく読み取れませんでした。 検証データと生成結果に、以下のような差異が見られました。
- A-2の電力上限値の値を、温度の値と認識している
- B-1,B-2を1つの機能として認識し、B-2の機能説明のみが記載されている
課題対処法
次に、表と表から抽出したテキスト情報をセットで、Claude 4へ投げる手順と結果を記載します。
手順1:表からテキストを抽出する
PDF内の表からテキストを抽出する方法は複数あります。
本記事では、表形式データの抽出に優れたライブラリである、Pythonの"pdfplumber"を使用して、PDF内の表からテキスト抽出を行いました。
以下は処理コードと、処理結果です。 表中のテキストを正確に抽出できていることが確認できます。

手順2:表と表中のテキスト情報をLLMに投げる
 プロンプト
プロンプト
 生成結果イメージ
生成結果イメージ
プロンプトに表中のテキスト情報を入力するだけで、意図した生成結果を出力することができました。
最後に
本記事では、LLMにPDF内の表を読み込ませる際のワンポイントテクニックを紹介いたしました。 同じような課題に直面している方、これから直面しそうな方に向けて、少しでもこの記事が参考になれば幸いです。
