

はじめに
近頃、整理もせずにスマホやPCに写真を溜め込み続けていて、「あの写真、どこに行ったっけ?」とフォルダを探し回る面倒さを痛感しますが、自然言語で直接画像を検索できたら便利ですよね。
今回は、CLIPというモデルを用いて、日本語のクエリを使った画像検索を実装してみました。
CLIPとは? ~ 画像とテキストを同じ意味ベクトル空間へ ~
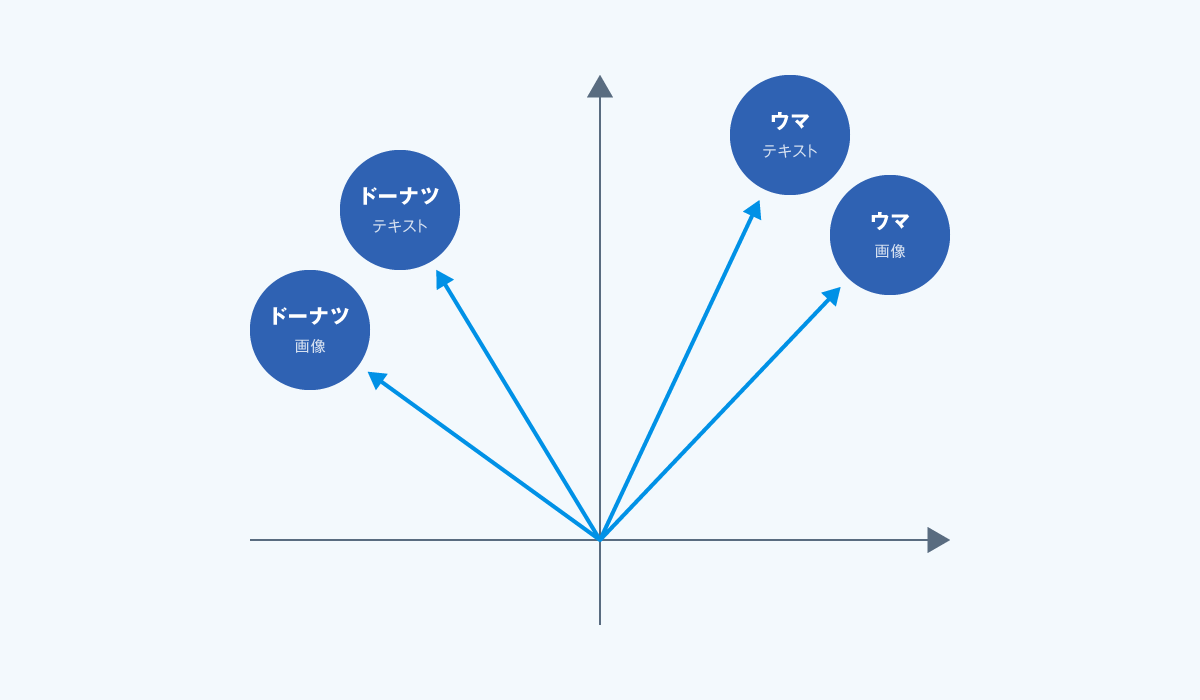
CLIP(Contrastive Language-Image Pre-training)は、 画像とテキストを同じ「意味ベクトル空間」(テキストと画像が共通の理解を持つ領域) にマッピングするモデルです。
たとえば「ウマ」というテキストをベクトル化し、ウマの写真も同じ空間に埋め込むと、両者が意味的に近ければ近いほど、ベクトルは共に同じような位置に配置されます。
一方、「ドーナツ」というテキスト、またはドーナツの画像をベクトル化したものは、「ウマ」のベクトルとは離れた位置に配置されることになります。
これにより、テキストと画像の柔軟な対応付けが可能となります。
実装・処理の流れ
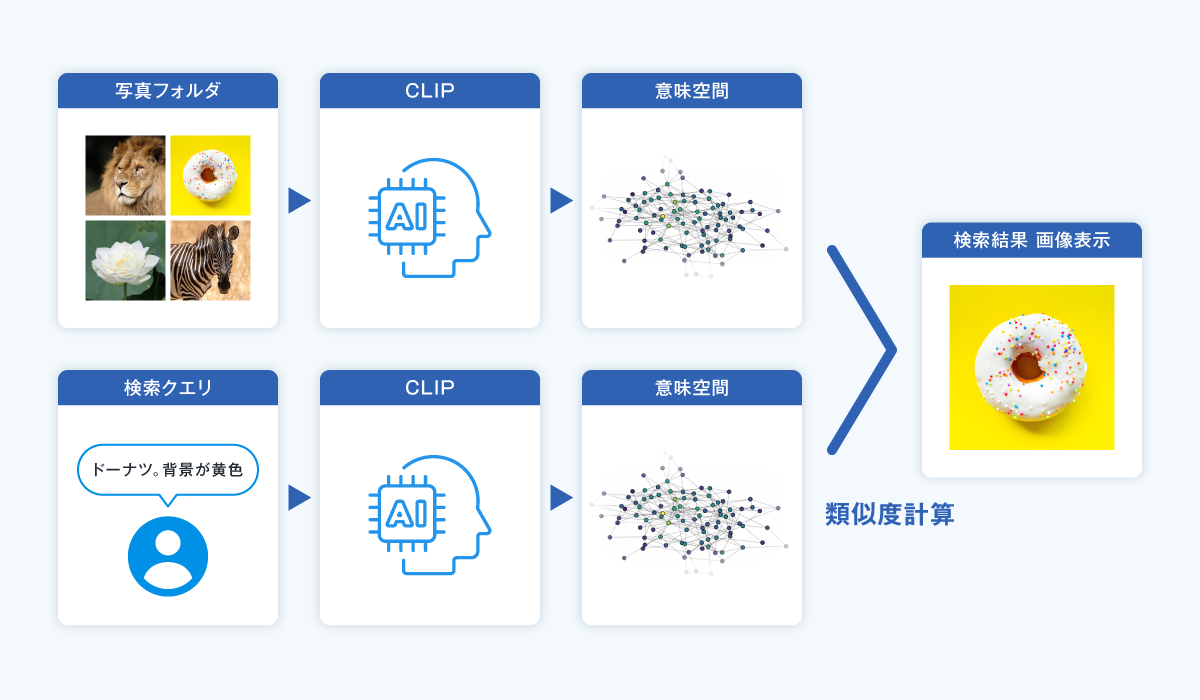
1. 画像の用意
私の個人フォルダから、無作為に写真を合計284枚取り出してローカルに保存しました。
2. 画像の前処理
CLIPは224x224ピクセルの正方形画像を入力サイズとして想定しているため、元画像を縦横比を保ったまま縮小し、足りない部分は黒枠で埋めます。
3. 画像のベクトル化
前処理した画像をモデルに入力し、512次元のベクトル表現(埋め込み)を取得します。

4. テキストクエリのベクトル化
「ガラスに囲われている神輿」のような日本語クエリもテキストエンコーダに通し、対応するベクトルを得ます。
これで、画像とテキストを同じ「意味ベクトル空間」で比較可能になります。
5. 検索処理
テキストベクトルと画像ベクトル群の類似度(内積)を計算し、スコアが高い画像を上位に表示すれば、自然言語による画像検索が成立します。
実験結果
いくつかのクエリで試してみました。
「ガラスに囲われている神輿」
ガラス越しの神輿がきちんと上位に出現しました。
浅草駅で撮影した画像です。

「つけ麺。皿が2つある」
残念ながら、この検索はうまくいきませんでした。 期待していたつけ麺写真は出ず、代わりにスパゲッティの写真が1位にランクイン。

つけ麺の写真のスコアは4位でした。

「つけ麺」という概念をモデルが十分理解していないか、あるいは麺の種類という細かい条件の把握が難しかったのかもしれません。
「スキー場で、ピースしてる男」
こちらは好調。
スキー場でピースしている写真がトップを獲得 し、モデルが複合的な条件をうまく捉えていることがうかがえました。

まとめ
タグ付けやフォルダ分けをしなくても、テキストと画像の意味的対応により柔軟な検索ができることを実装を通じて体験できました。
画像キャプション生成モデルや、より大型・高度なモデルを組み合わせれば、より精度の高い検索や直感的な説明表示も可能になるかもしれないとも感じました。
AI分野で画像とテキストの相互作用はホットなトピックなので、これからも注目していこうと思います。
