

はじめに
AIを実世界に適用する場合、精度と速度の両方がよく求められることがあります。
例えば自動運転などは刻々と変わる状況の変化に対応しなければならず、その瞬間で高精度な運転の判断ができても、その推論速度が遅ければ、持続的な運転はできません。
そのようなリアルタイム性が重視されるシステムでは、AIは精度だけでなく速度も重要です。
ということで、今回は目的の精度のAIモデルが得られたうえで、速度を上げるための手法やテクニックをいくつか紹介します。
量子化/低精度化
AIモデルを32ビットの浮動小数点数で学習させると、そのモデルのパラメータや出力値は32ビットの浮動小数点数で保存されますが、高速に計算させるために、そのパラメータや出力値を16ビット浮動小数点数や8ビット整数で近似することで高速化する手法があります。
16ビット浮動小数点数への近似は低精度化、8ビット整数への近似は量子化と呼ばれます。低精度化は精度をほぼ保ったまま、速度をある程度上げられますが、量子化に関しては、低精度化よりも大きく速度をあげられるものの、精度が落ちやすいのが欠点です。
量子化は一般的に精度が落ちやすいため、AIモデルの全てのパラメータや出力値を量子化するのではなく、精度にあまり影響がなさそうなものだけを量子化するというテクニックがあります。
例えば、特定の層だけを量子化して精度を確認し、精度が大きく落ちる場合は、その層を量子化しないという選択ができます。
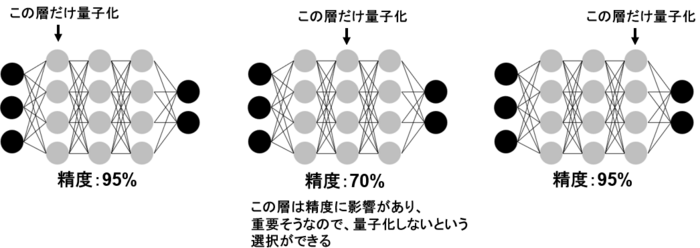
低精度化でとどめるか、量子化まで行うか、さらに細かく量子化するかは、目的の精度と速度に合わせて、選ぶと良いでしょう。
枝刈り
AIの演算には多くの行列演算が含まれています。
その行列演算を高速に行う手法として、枝刈りという手法があります。
枝刈りは多くのパラメータを0にすることによって、行列計算を高速化させる手法です。
そのパラメータを0にする場所によって、さらに非構造枝刈り、構造枝刈りに分けられます。
非構造枝刈りは構造に関係なく、0に近いパラメータを0に近似しますが、構造枝刈りは行列の行単位または列単位でパラメータを0に、つまり行または列を削除します。

この2種類の枝刈りにも精度と速度の特徴があります。
一般的に非構造枝刈りは精度を保ちながら、速度をあげられます。構造枝刈りは非構造枝刈りよりもさらなる速度向上を期待できますが、行または列をまるごと削除にしてしまうことで、0に近くない値も0にしてしまう可能性があるため、精度が落ちやすいです。
また、枝刈りの注意点として、AIをGPUを使って動かす際は不向きであるということです。
構造枝刈りに関しては、行や列を削除するため、GPUを使う際でも速度を上げやすいですが、精度は落ちやすいです。
そのため、非構造枝刈りも選択肢に入れたいところですが、非構造枝刈りをしても、GPUの計算を高速化できません。
CPUでは高速になるため、CPUでAIを適用する際に枝刈りを試すと良いでしょう。
蒸留
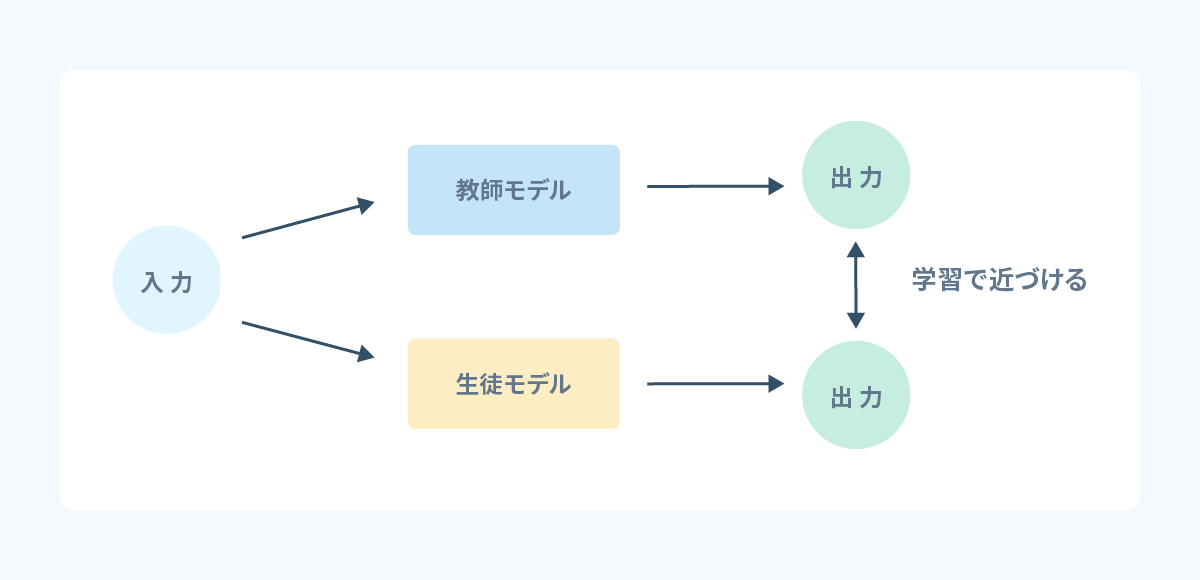
蒸留とは、大きくて計算の重いモデルと同じ性能を持つ軽いモデルを得る手法です。
大きいモデルの方を教師モデル、小さいモデルの方を生徒モデルと呼びます。
教師モデルの出力結果を使って、生徒モデルを学習させることで、同じ性能に近づけます。
既に目的の精度のAIモデルが得られていて、そのモデルが大きくて計算の重いモデルの場合に、特に有効です。
逆に速度を上げたいモデルが既に軽量なモデルの場合は、不向きでしょう。
教師モデルと生徒モデルは全く構造の異なる別のモデルで行われやすいですが、32ビット浮動小数点数のモデルを教師モデルに、それを量子化したモデルを生徒モデルとして、蒸留するという方法もあります。
蒸留は単に速度を上げる以外にもメリットがあります。
軽量な学習済みモデルを得ていて、精度を上げる目的で、大きなモデルを用意し、蒸留することもできます。
低ランク近似
低ランク近似とは特異値分解によって、パラメータ行列を低ランクの行列に置き換え、複雑な計算を簡単な計算にして、高速化する手法です。
イメージとして以下のように、低ランク近似をした後に、後ろ側から計算することで、速く計算できるようになります。

低ランク近似の難点として、高速化するAIモデルへの深い理解がなければ、適用できないという点があります。
どこを低ランク近似できそうかというところを理解しておかなければなりません。
その他
その他の高速化手法としては、予め軽量なモデルを選ぶ、AIを動かすマシンを高スペックなものを選ぶ、並列推論を実装するなどがあります。
並列推論は、AIモデルをメモリに2つ分読み込ませておき、2つのスレッドで交互に推論させることで必要なメモリ量が増えますが、高速化が期待できます。
AIの推論をGPUで、前後処理をCPUで行う場合、一方のスレッドで前後処理を行っている間は、他方のスレッドが推論を行うようにすれば、GPUをできる限り動かし続けることができます。
最後に
今回はAIの高速化手法をいくつか紹介しましたが、結局どれを試せばよいかということで、最後におすすめとして、以下の手順を紹介します。
- 軽量なモデルを選ぶ。
- 実装が簡単な低精度化を試す。
- それでも速度が足りなければ、CPUの場合は非構造枝刈りを、GPUの場合は量子化を試す。
- モデル自体の速度を上げきっても足りなければ、並列推論を実装する。
基本的には速度が足りなければ、順に試していけば良いかと思いますが、「4.」の並列推論に関しては、精度に影響はないため、マシンスペックに余裕があるなら、ぜひ試してみると良いでしょう。
AIの高速化をしたい方に、こちらの記事がお役に立てば幸いです。
