

はじめに
多くのWebアプリケーションは、サーバ上のデータベースに情報を保存するかと思います。 運用当初は問題なく稼働していても、長く運用すればするほどデータベースには情報が蓄積され、 パフォーマンスが低下することが少なからずあります。
今回の記事では、実際の開発の中で問題となったパフォーマンス低下の事例とその改善方法についてまとめました
事例
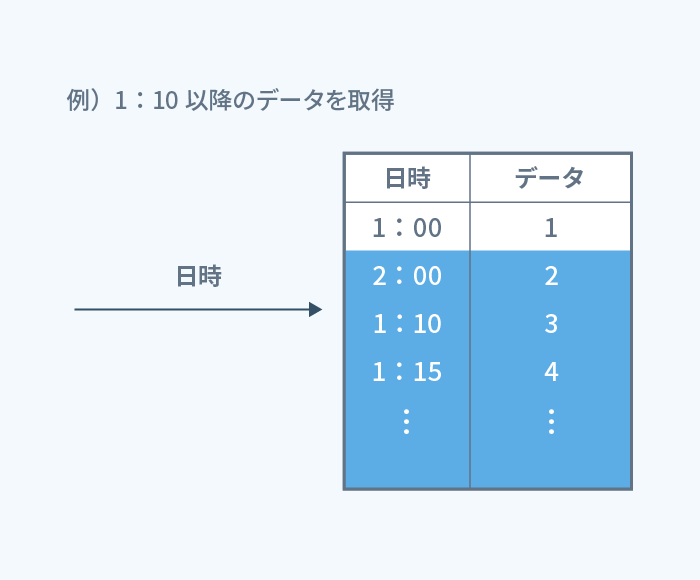
問題となったパフォーマンス低下は、以下のようなテーブルから「ある日時以降のデータ」を取得するクエリで発生しました。
検索対象となる日時やその他の条件の列にはインデックスが付与されており、 さらに取得する件数に上限を設けている(LIMIT)ため、 登録されているレコード数が増加しても検索時間に大きな影響はないと想定していました。
しかしながら、大量データ下で試験を行ったところ、登録されているレコード数に応じて性能が顕著に劣化し、 サーバの応答時間の制限を超えてしまうことがわかりました。
原因
大量データ下での実行計画を確認した結果、以下のことが分かりました。
- 件数を絞っても性能改善効果は得られない
取得するデータの件数を絞っても、検索の対象となる母集団は変わらないため、 レコード数の増加に伴って検索の所要時間が増加していました。
この問題に対し、以下のように改善しました。
対処
処理を分割する
なぜ母集団が大きくなってしまうかというと、「指定された日時以降」を検索条件としていたためです。
想定する活用度で運用が進んでいたとしても経時でレコード数は増え、また、大昔の日時を指定すれば
母集団は非常に大きくなってしまいます。
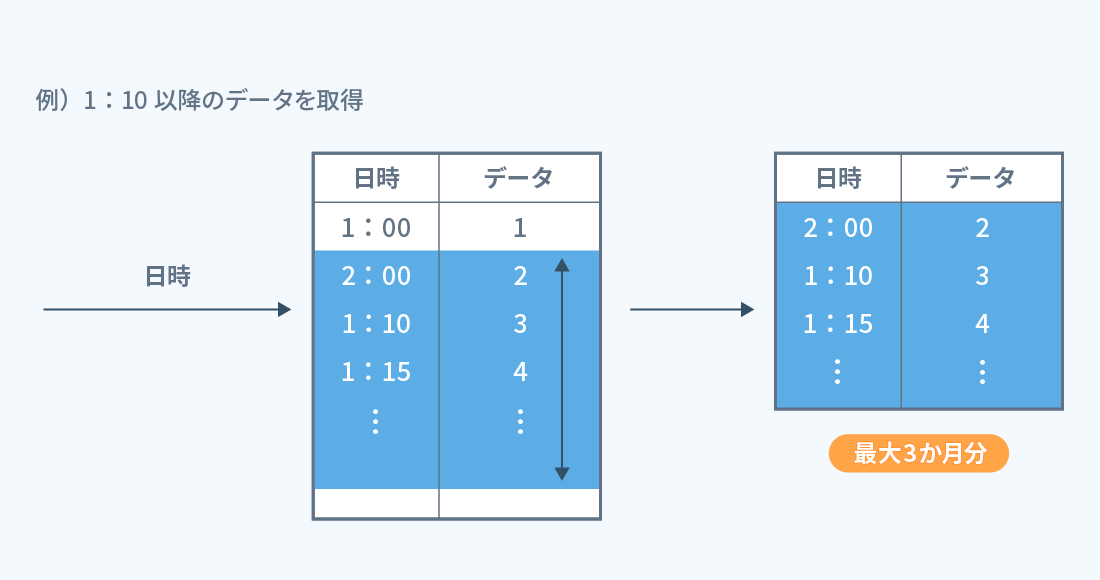
そこで、母集団を小さくするために処理を分割する必要があると考えました。 今回のケースでは、1回の処理で 「指定された日時から3か月間」のデータを取得するよう変更することで、 最大でも3か月分の母集団となるようにし、サーバの応答時間の制限を超えないようにしました。
仕様・設計の見直し
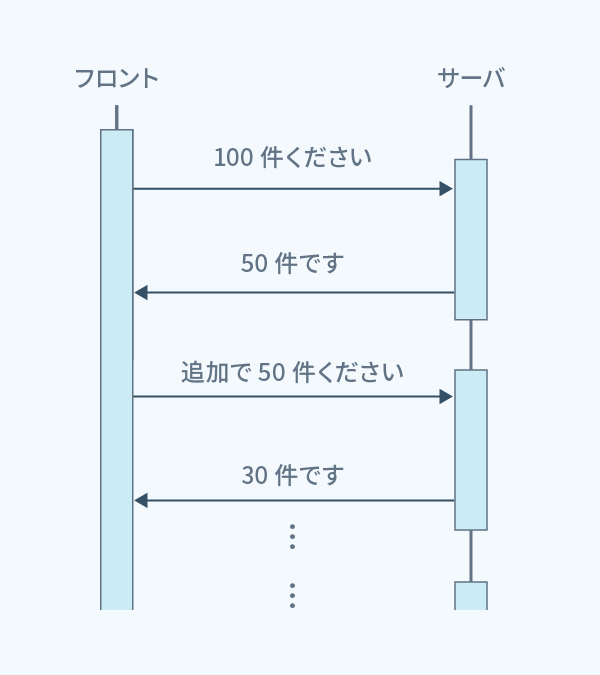
もちろん 「指定された日時から3か月間」の中に、取得したい件数のデータがない場合もあります。 そこで、取得したい件数が取れるまで、もしくは、母集団のデータを検索し終えるまで 次の3か月、また次の3か月……と、繰り返し処理を行うようにしました。
また、サーバの応答時間の制限があるため、 この繰り返し処理はフロントエンドから行うように仕様・設計を見直しました。
まとめ
以上、今回の対応で得られた教訓は以下のようになります。
- 取得する件数に上限を設けていても性能改善効果はない。
- 大きな母集団を扱う場合には、処理を分割するのが有効。
- 分割した処理の繰り返しは環境や要件によってどこでやるか、都度検討が必要。
一連の対応の中で重要だと感じたのは、まず 「想定していた対策が有効に機能しているか」必ず確認が必要ということです。
有効に機能していない場合、巨大なデータを適切に処理できていないということになります。
そのような場合は、結合するレコードを小さくする、今回のように処理を分割するなど、
なるべく小さい単位で処理をする工夫が必要となります。
また、その単位や分割処理を繰り返す主体についても仕様や要件によって都度検討が必要であると改めて感じました。
