

AIシステムを継続して運用していくには、期待通り動いているのかをモニタリングすることができる仕組みが必要不可欠です。 本記事では、モニタリングが必要になる観点と、 Prometheus を使ってモニタリングシステムを構築した事例を紹介します。
MLOpsの構築に求められるモニタリング
AIシステムの中核を担う MLOps の構築においては、 様々な場面で期待動作を確認するため、モニタリングの仕組みが求められます。
- 学習/推論パイプラインを実行するのに必要な、各種サービスの稼働状況のモニタリング
- GPUクラスタを構成するシステムの健全性のモニタリング
- 学習/推論に使用するデータ品質に対するモニタリング
- データサイエンティスト、AIエンジニアが実行したジョブの稼働状況のモニタリング
- 学習済みモデルやデプロイ済みの推論モデルのパフォーマンスモニタリング
- 異常が生じた際のAlertと通知
インフラ部分のモニタリングから、 Machine Learning / Deep Learning 特有のメトリクスに対するモニタリングまで、 数多くの項目を一括でモニタリングし、異常が生じた際にはいち早く発見して対応できる状態にすることが必要です。
Prometheusを使うメリット
モニタリングシステムを構築する上で、どのようにデータを収集するのかが課題になります。 特にオンプレ環境で MLOps を構築するケースでは、以下のような特性を考慮します。
- ニーズに応じてGPUマシンのスケーリングにも対応しやすいこと
- マイクロサービスである Dockerコンテナ や、 Kubernetes のPodの監視にも適していること
- 各マシンの動作への影響は最小限に抑えられること
そこで選択肢として考えられるのが、 「 Prometheus 」という OSS の監視ツールです。
よく採用される OSS の監視ツールとしては、他に「 Zabbix 」もありますが、
MLOps システムでは Dockerコンテナ や Kubernetes のPod運用が必須であるため、
コンテナ環境のオートスケールに対応しやすい Prometheus がおすすめです。
Zabbix と異なり、 Prometheus 単独だと収集したデータの可視化等の機能は最小限なので、 OSS のデータ可視化プラットフォームである Grafana を併用して、 Prometheus をデータソースとして使用する構成がよく取られています。
PrometheusとGrafanaとの連携による活用例
Prometheus は、分散型アーキテクチャを採用したPull型の監視ツールです。
メトリクスを収集するための Exporter というツールを収集対象のマシンに導入し、
Prometheus サーバ側で収集対象となる Exporter と収集周期等を指定することで、
メトリクス収集が可能になります。
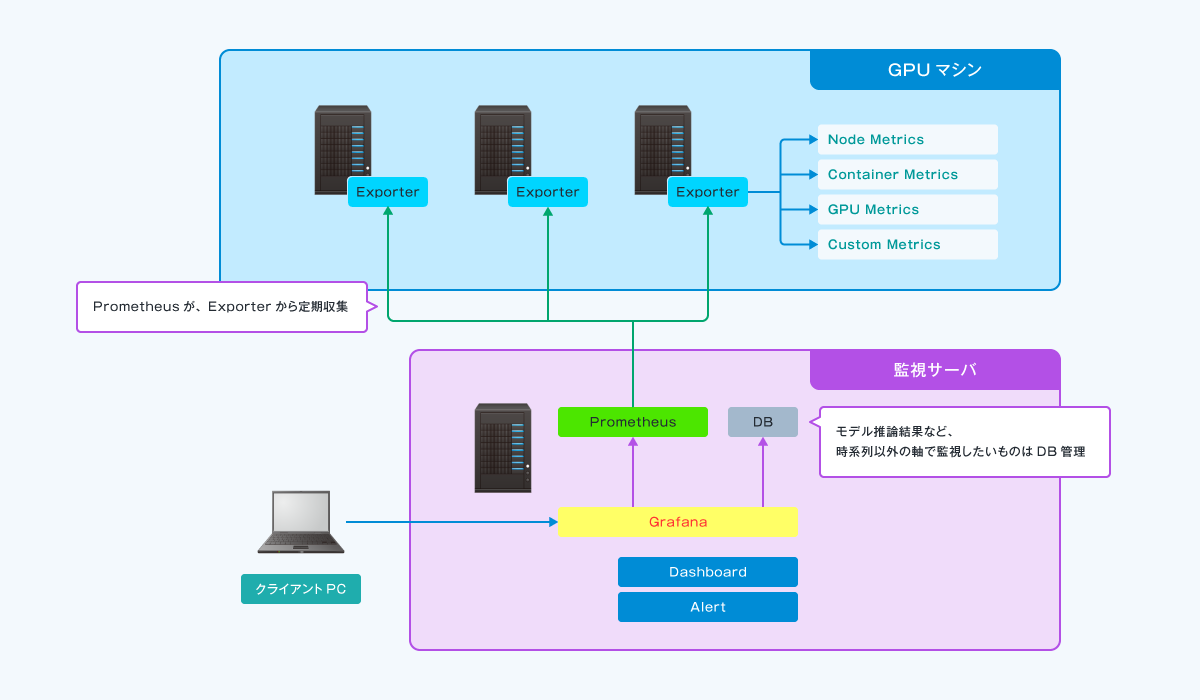
弊社環境では、収集対象によって複数の Exporter を使い分けています。
また、 Exporter が標準でサポートしているメトリクス以外に、
カスタムメトリクスを活用して任意のメトリクスを収集することも可能です。
収集した各種メトリクスは、 Grafana を使うことにより以下のような活用が可能です。
-
チームメンバーで共有するためのリソースモニタリングダッシュボード
時系列データとして、リソースの変動推移を可視化するリソースモニタダッシュボードを作成します。
⇒ 学習環境の調子が悪いときや、アプリケーションの不具合発生時などに、過去数日間のリソースモニタを元に原因を調査して対策につなげる。
⇒ 中長期のリソース変動をダッシュボードから分析し、今後のハードウェア増設の検討材料にする。 -
Alert機能による異常の早期検出
閾値を設定して、範囲外の値やデータなしを検出したタイミングでAlert検出。
⇒ メール通知やWebhookを用いて、チームメンバーへ迅速な通知を実現。
最後に
モニタリングシステムは、高可用性が求められるAIシステムの構築には欠かせないものになっています。 私たちのサービスでは、データ分析基盤の構築や Deep Learning モデル開発、 MLOps 構築、生成AIモデル開発等データに関わるプロジェクトを伴走支援しております。 データ分析基盤開発やデータのAI活用経験のある方や、興味のある方は、ぜひご応募ください。 あなたのスキルと情熱をお待ちしています。
