

はじめに
生成AIを活用して「社内動画から効率的に情報を取得したい」という社内課題にアプローチしました。
具体的には以下の画像のように質問を入力すると、
社内動画のデータベースから質問の該当箇所を動画の時間単位で抽出してくるシステムを作成しました。
(UIはStreamlitというライブラリを利用して作成しています)
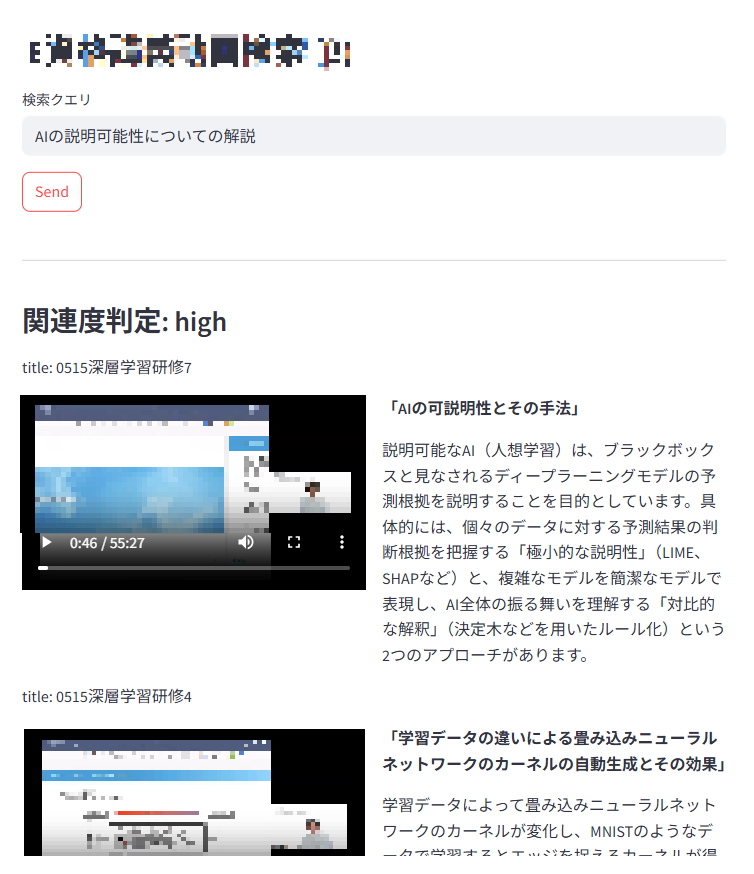 実際にシステムを利用した画面
実際にシステムを利用した画面
質問を入力すると、質問に関連した該当箇所とその内容の要約が関連度順に出力される。
本記事では、作成したシステムの概要をご紹介したのち、
精度を向上させるために施したいくつかの工夫についてご紹介したいと思います!
システムの概要
本システムの仕組みは「DB作成フェーズ」と「検索フェーズ」の二段階に分かれます。
DB作成フェーズ
ここでは以下のように社内動画群から社内動画DBを作成します。
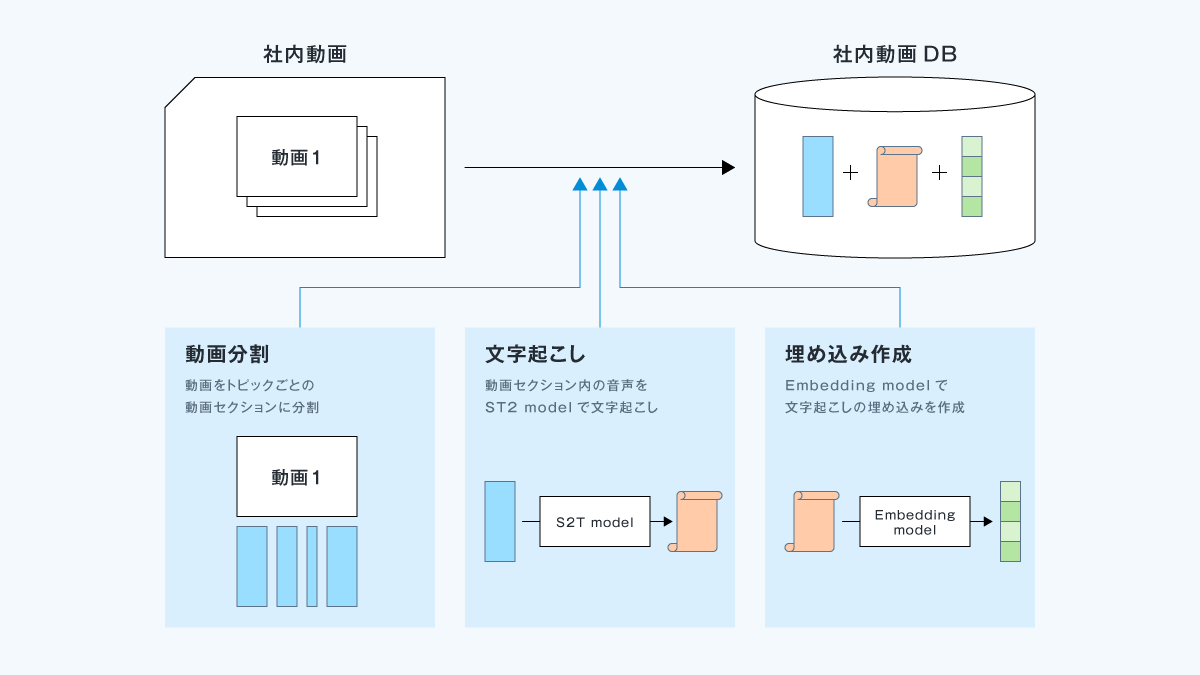
この作成手順は大きく分けて3つに分かれます。
1ステップ目は「動画分割」で、動画をトピックごとの動画セグメントに分割します。
例えば、動画1の1:00~1:30はAについて解説している動画セグメント1、動画1の1:30~2:59はBについて解説している動画セグメント2というようなイメージです。
今回対象とした社内動画はスライドベースの講義動画が主だったので、1スライドで1トピックを説明しているという仮定のもと、フレーム間のピクセル値差分が大きくなるところで分割を行いました。
ちなみに本システムでは全部で6~7時間の動画群を500弱程に分割した動画セグメントを対象にしています。
2ステップ目では動画セグメント内の音声をSpeech-to-Text model (S2T model) で文字起こしを行います。
3ステップ目ではその文字起こしからEmbedding modelを利用してその埋め込みを作成します。
以上の操作ののち、作成した動画セグメント・文字起こし・埋め込みのペアを社内動画DBに保存していきます。
(ある動画セグメントに対してペアとなる文字起こし・埋め込みは、そのセグメント内の音声から作成された文字起こし・埋め込みを指します)
検索フェーズ
ここでは実際にユーザの入力した質問に対して、社内動画DB内の関連する動画セグメント・文字起こしを抽出・表示します。
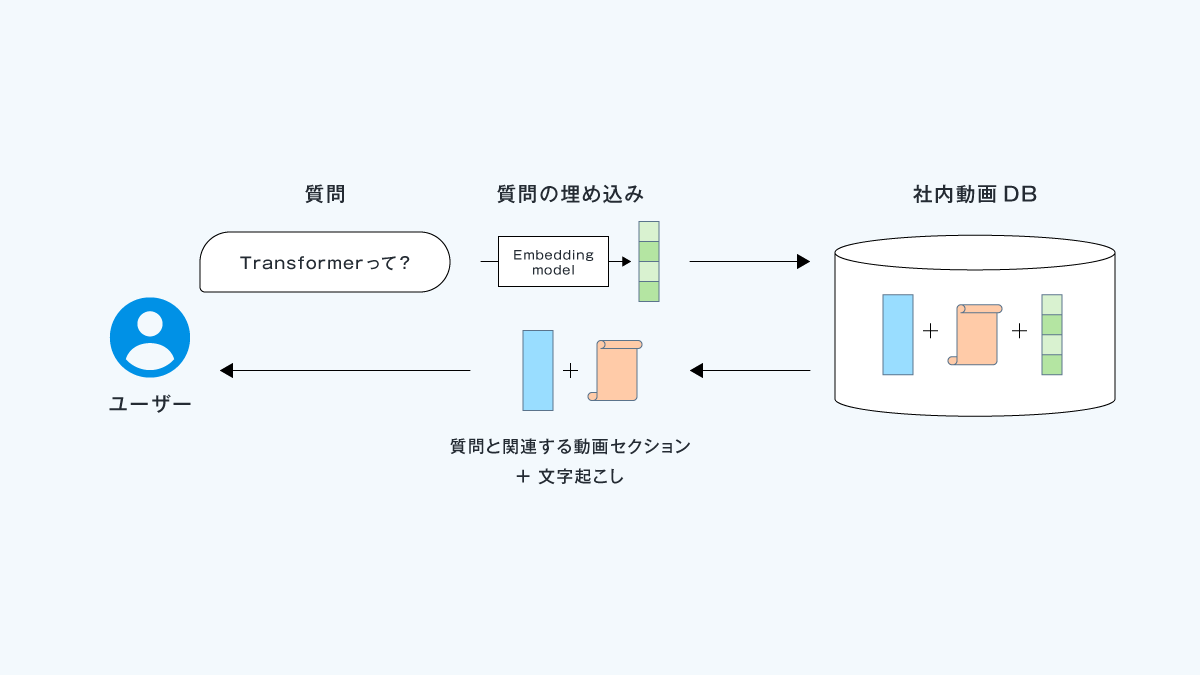
最初にユーザが質問を投げかけると、システムはEmbedding modelを利用して質問の埋め込みを作成します。
次に、質問の埋め込みと社内動画DB内の埋め込み群の間の関連度を内積から算出します (cf. ベクトル検索)。
社内動画DBからは内積計算により同定された、関連度の高い埋め込みとペアである動画セクション・文字起こしをユーザに返して表示します。
以上の操作を通して、本システムは社内動画群から質問と関連した該当箇所をユーザに提示することが可能となります。
なお、実際には複数の動画セクション・文字起こしを抽出してユーザに提示しています。
精度向上のための工夫点
本システムは実装当初、質問と関連のない動画ばかりを提示してくるような精度が低いものでした。
そこで以下のような複数の工夫を施すことで精度を向上させることができました。
Embedding modelの再検討
様々なEmbedding modelで検証して、本システムにおいて最も精度が高そうなモデルを探しました。
これが最も精度向上に寄与したと感じます。
再検討前のモデルでは質問に対して、提示してほしい箇所は低い関連度である一方、しばしば「今からXXの講義を始めます、よろしくお願いします。」といった関係のない箇所は高い関連度となってしまっていました。
そこで日本語でファインチューンされたモデルを利用してみると、提示してほしい動画セグメントの関連度が10番以内には入るような精度になりました。
言語モデルによるrerank
Embedding modelを再検討することにより提示してほしい動画セグメントの関連順位が上がりました。
そこで次に、言語モデルに質問と各動画セグメントとペアの文字起こしの関連度を再評価させました。
これにより提示してほしい動画セグメントの関連度をより高く評価することができ、より提示される動画セグメントの精度が向上しました。
質問の拡張
社内の講義動画には専門用語も多々出てきており、Embedding modelは専門用語のみで構成される質問 (CNNとは何ですか、のようなイメージ) に対して適切な埋め込みを作成できていない可能性があります。
そこで本システムではユーザの質問を埋め込む前に、質問中のキーワードについて、言語モデルに一般的な語彙を用いて解説させて、質問とその解説を繋げた文章を埋め込んで検索に用いました。
これにより専門用語の質問もある程度の精度が見込めるようになりました。
(ただし、解説を作成する言語モデルが専門用語について説明できるほどの知識がないといけない制約があるのでさらなる改善が必要かもしれません)
さいごに
私たちのTech Blogを最後までお読みいただき、ありがとうございます。
私たちのチームでは、AI技術を駆使してお客様のニーズに応えるため、常に新しい挑戦を続けています。
最近では、受託開発プロジェクトにおいて、LLM(大規模言語モデル)を活用したソリューションの開発ニーズが高まっております。
AI開発経験のある方やLLM開発に興味のある方は、ぜひご応募ください。あなたのスキルと情熱をお待ちしています。
新卒、キャリア募集しています!
自動運転/先進運転支援システム(AD / ADAS)、医療機器、FA、通信、金融、物流、小売り、デジタルカメラなど、組込み機器やIoT、Webシステムなど様々なソフトウェア開発を受託しており、言語やOS、業務知識の幅を広げることが可能です。
また、一次請けの案件が多く上流工程から携わることができます。
客先常駐でも持ち帰りでも、Sky株式会社のチームの一員として参画いただきますので未経験の領域も上司や仲間がサポートします。
