

今回はLangfuseという大規模言語モデル(LLM)を利用したアプリケーションの観測・分析プラットフォームを紹介いたします。
Langfuseの使い方
LangfuseをDifyというノーコードで生成AIを用いた機能を開発できるシステムと連携することで、Difyで行われた処理のログをLangfuseに残すことができます。
連携方法はとても簡単で、Langfuseで作成したプロジェクトのAPIキーをボタンワンクリックで作成し、Difyに"秘密キー"、"公開キー"、"ホスト"を記入するだけです。
そうすることで、以下のように連携できます。
以下の写真の左半分がDify、右半分がLangfuseの画面となります。推論結果がトレースとしてLangfuseに残るので見返しやすいです。
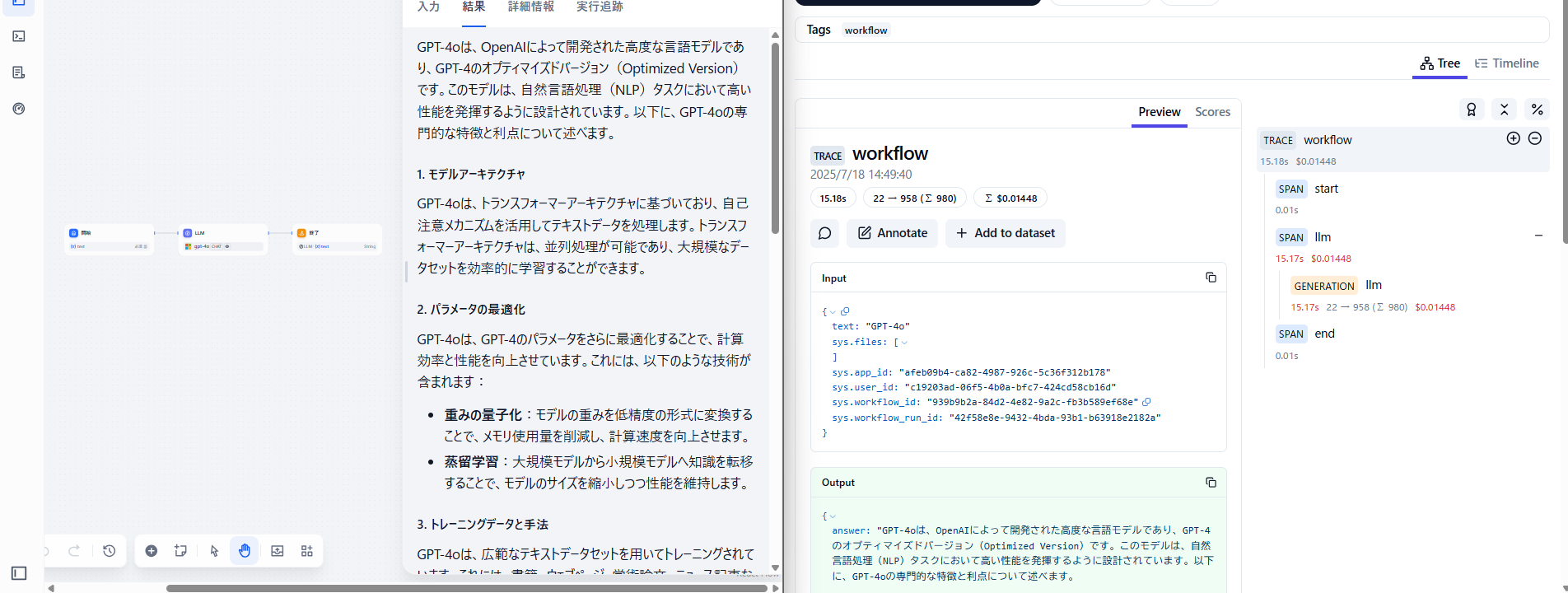
Dify(左)とLangfuse(右)のスクリーンショット画像
さらに、Dashboardでは下記のように様々なものを見ることができるなど、とても便利です。
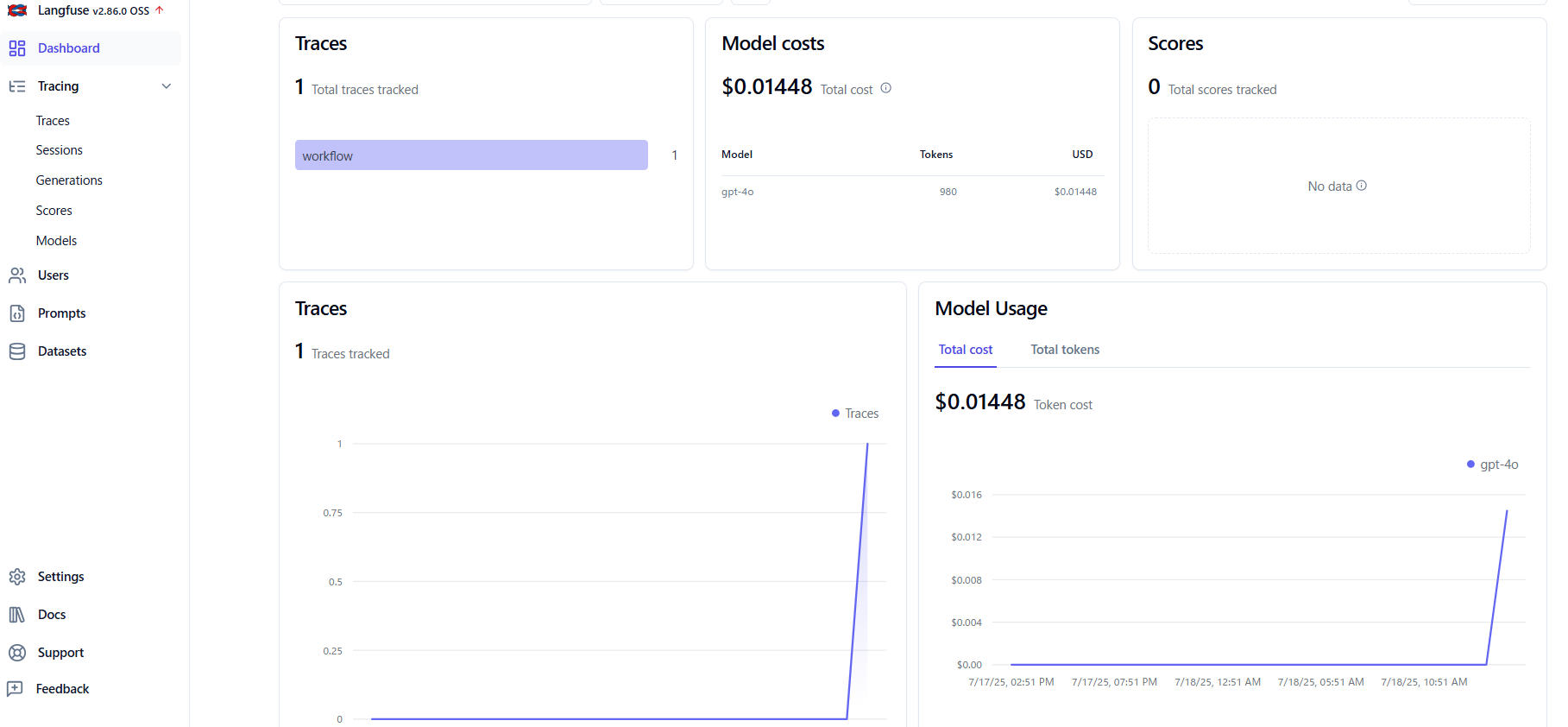
Langfuseのスクリーンショット画像
課題
Langfuseにはクラウド版とOSS版(無料)があります。
OSS版の場合、クラウド版の方にある便利な機能がありません。
例えば、クラウド版はLLM-as-a-Judgeがあるのに対し、OSS版はありません。
他にも、トレース情報からデータセットを作成し、Langfuse内で保管することができましたが、過去のトレースを1つ1つデータセットに手動で追加していくことになり、少し大変です。
目的
今回は、上記のような課題を解決するため、LangfuseとDifyのAPIキーを用いて、データセット作成、生成AIへの推論、自動評価、結果の保存という一連の運用をスクリプトで行う方法をLangfuseに焦点を当てて、ご紹介いたします。
DifyをPythonから呼び出す方法につきましては、別の記事がありますので、Difyの方について知りたい方は以下の記事を読んでいただけますと幸いです。
また、公式からlangfuseフレームワークが用意されておりますが、requestsライブラリの方が自由度が高かったため、今回はこちらを使用いたします。
前提
スクリプトでLangfuseを使用するためには、以下のように認証情報を指定する必要があります。
# 認証情報を設定
auth = (LANGFUSE_PUBLIC_KEY, LANGFUSE_SECRET_KEY)
エンドポイントは行いたい操作によって変化しますので、適したものに設定する必要があります。
そして、適したpayloadを設定し、requestsを用いてリクエストを送ることで適した処理が行われます。
例:
response = requests.post(endpoint, auth=auth, json=payload)
データセット作成
過去に推論で使用したもの、つまりトレースとして残っているものを用いて、データセットを作成したいときの方法を紹介いたします。
1. 下記のようにparamsを指定。
params = {"limit": 100, "page": 1}
- limit … 一度に取得できるトレースの数。指定できる数は最大100まで。
- page … 最新から何ページのものを取得するかを指定。
- 例:
limit:100, page:1 … 1件目~100件までを取得。
limit:100, page:2 … 101件目~200件までを取得。
limit:50, page:2 … 51件目~100件までを取得。
2. エンドポイントをTRACES_ENDPOINT = f"{LANGFUSE_HOST}/api/public/traces"と設定し、以下のように実行。
response = requests.get(TRACES_ENDPOINT, auth=auth, params=params)
上手くいけば、 traces = traces_data.get("data", []) を行うことで、paramsで指定した範囲のtrace情報を扱うことができます。
すべてのトレース情報を取得したい場合
上記の方法だと、limitで指定した数までしか取得できません。
全て取得したい場合は、初めはpageを1にして、以下のようにpageキーの値をインクリメントし、取得したtraceが0になるまで、whileループを回し続ける必要があります。
while True:
response = requests.get(TRACES_ENDPOINT, auth=auth, params=params)
if response.status_code != 200:
print(f"Trace取得失敗: {response.status_code} - {response.text}")
break
traces_data = response.json()
traces = traces_data.get("data", [])
# trace無ければ終了
if len(traces) == 0:
break
(諸々の処理)
params["page"] += 1
こうすることで、全てのトレースを取得できます。
今回はこの取得したトレースから指定した日付の範囲の間に作られたトレースの入力情報をデータセットに保存してみましょう。
そのために以下の事を行います。
1. データセットの格納場所の作成
endpointは "{LANGFUSE_HOST}/api/public/datasets" になります。
nameには好きなデータセット名を書いてください(今回はtest_dataという名前にしました)。
response = requests.post(
endpoint,
auth=auth,
json={"name": name}
)
上手くいけば下記のようになります。
具体的なデータはまだ格納していないので、itemsは0です。
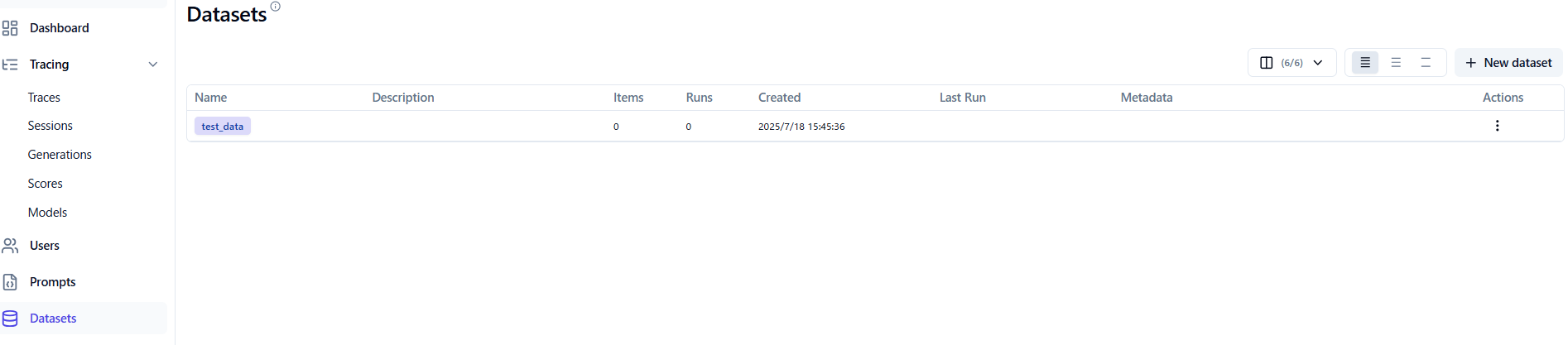 Langfuseのスクリーンショット画像
Langfuseのスクリーンショット画像
2. トレース作成時の日付を確認し、データセットに追加するデータを決める
トレースには"createAt"という作成日情報があるので、それを利用。
for trace in traces:
created_at = trace.get("createdAt")
if created_at is None:
continue
trace_dt = datetime.fromisoformat(created_at.replace("Z", "+00:00"))
if not (start_date <= trace_dt <= end_date):
continue
3. 追加したいデータをデータセットに追加
エンドポイントは "{LANGFUSE_HOST}/api/public/dataset-items" になります。
そして、以下のようにpayloadで、データセット名と入力情報、予想される出力情報、メタデータを記載したものをリクエストで送ることでデータセットを作成できます。
item_payload = {
"datasetName": dataset_name,
"input": trace["input"]["text"],
"expectedOutput": "",
"metadata": {}
}
今回は例として15:00~16:00の範囲で作成されたトレースの入力情報をデータセットに追加いたしました。
6つのトレースのうち、範囲内にある5つをデータセットに追加できていることが確認できます。
 Langfuseのスクリーンショット画像
Langfuseのスクリーンショット画像
生成AIへの推論、自動評価
こちらはDifyの話ですので、詳しくは述べません。
簡潔に言いますと、まずDifyを用いて推論します。
そして、Difyで新規のワークフローでLLM-as-a-Judge機構を作成し、APIキーを取得して推論をすることで、推論とその結果に対する評価をそれぞれ得ることができます。
評価結果込みのデータセット作成
こちらは新規のデータセット作成と同様の方法です。
新規でデータセットを作成し、出力結果や評価結果をmetadataに入れることで、結果込みのデータセットを作成することができます。
データセットを作成せず、既存のトレースにスコアを付与する場合は、出力結果に対する評価(スコア)を載せることができます。
エンドポイントは f"{LANGFUSE_HOST}/api/public/scores" となります。
そして、payloadは以下のようになります。
payload = {
"traceId": trace_id,
"name": name,
"value": value,
"comment": comment
}
- traceId … Traceに記載されているID情報
- name … スコアの名前、自由に決められる。(例:”ranking”, “similarity“)
- value … スコア値
- comment … そのスコアを付けた理由のコメント
リクエストを送ることで、スコアと理由が追加され、"scores"で各トレースのスコア一覧を見ることができます。
OSS版にも実装されているFilter機能を使うことで、スコアが低いものだけ見るなどもできます。
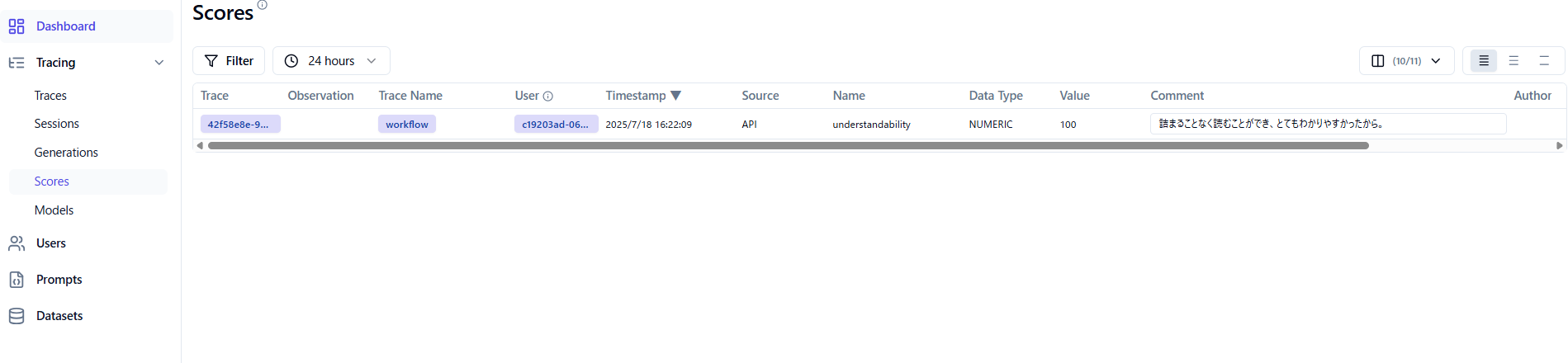 Langfuseのスクリーンショット画像
Langfuseのスクリーンショット画像
まとめ
いかがでしょうか。
このように少しの工夫によって、OSS版のLangfuseでも一連の運用を自動で行うことができます。
この記事を読まれている方の参考に少しでもなっていましたら幸いです。
最後までお読みいただきありがとうございました。
