

はじめに
2021年にOpenAIからCLIP(Contrastive Language-Image Pre-Training)という、画像と自然言語のペアで学習を行うモデルが発表されました。
これまでの画像認識タスクでは、クラスラベルのついた画像を教師付き学習する方法が主流でしたが、CLIPの登場により、近年では画像とそのキャプションのペアから教師なしで学習する方法が主流となっています。
画像と自然言語で学習することは次のような利点があります。
- 教師データなしでも学習が可能なため、Webで収集した画像を利用してデータセットを大規模化できる
- 「左の黒い猫」や「傘を差した子供」など、自然言語の表現力を活かした複雑な画像特徴(物体の位置関係・色彩・形状、画像の風景や状況など)を学習できる
これまで特定のデータセットで学習されたモデルでは、そのデータセットのクラス(例:ImageNetでは1000クラス)以外の予測はできませんでした。
一方で、CLIPは任意のクラス定義での分類が可能です。
このように、近年のトレンドとして、決められたクラス定義(Closed Vocabulary)での画像認識から、任意のクラス(Open Vocabulary)で画像認識を行うパラダイムへシフトしつつあります。
本記事では、画像認識のタスクの1つである物体検出にCLIPのアイデアを拡張した、Open Vocabulary Object Detection (OVOD)について紹介します。
Open Vocabulary Object Detection
近年のOVODの発展の中で代表的な3つのモデルを紹介します。
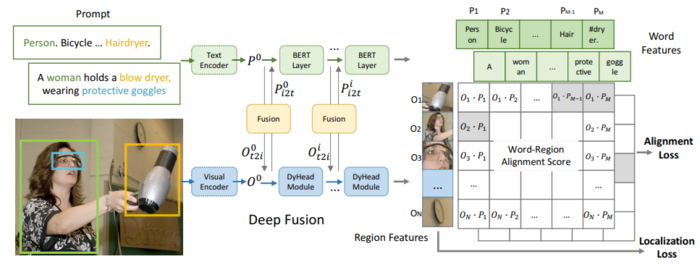
1. GLIP (2021)
論文:Grounded Language-Image Pre-training
Code : https://github.com/microsoft/GLIP
※ 引用
(Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, Jianfeng Gao, Grounded Language-Image Pre-training, https://arxiv.org/pdf/2112.03857)
特徴:
- 従来の物体検出タスクを物体と文章の関連付け(Grounding)タスクに置き換え
- COCOなどの物体検出データセットに加え、WEB収集データでも学習できるようになった
- Text EncoderとVisual Encoderの途中で特徴量をFusion
- 3,000,000件の物体検出データと24,000,000件のWEB収集データで学習
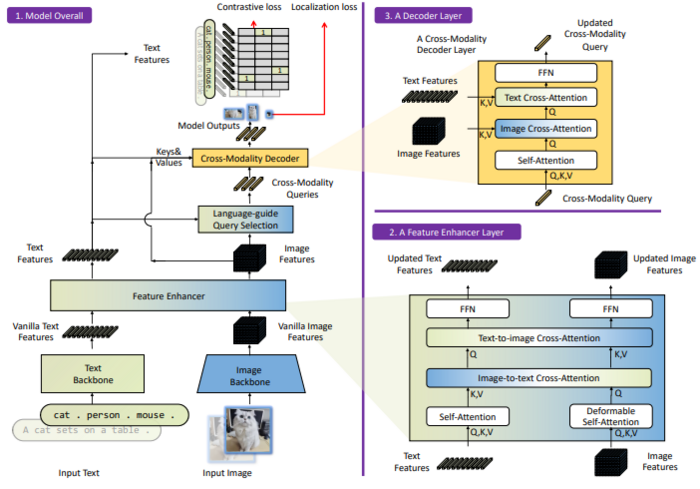
2. Grounding DINO (2023)
論文:Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Code : https://github.com/IDEA-Research/GroundingDINO
※ 引用
(Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang, Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection, https://arxiv.org/pdf/2303.05499)
特徴:
- Transformerベースの物体検出モデルDINOでGrounding(物体と文章の関連付け)モデルを作成
- Feature Enhancer:Backboneから抽出された画像・テキスト特徴量をCross-AttentionによりFusion
- Language-guide Query Selection:画像特徴量の中からテキスト特徴量との内積が高いもの(上位900件)を物体検出DecoderのQueryとする
- Cross-Modality Decoder:DETRで導入されたDecoder headにテキストとのCross-Attentionを追加
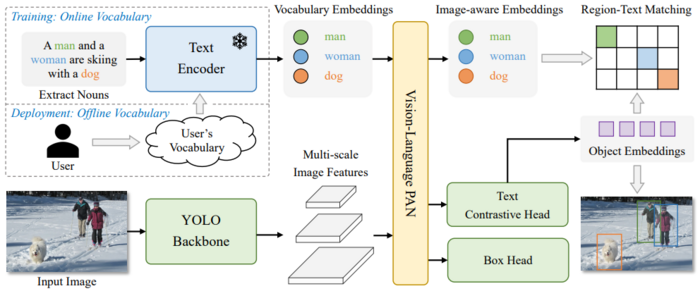
3. YOLO World (2024)
論文:YOLO-World: Real-Time Open-Vocabulary Object Detection
Code : https://github.com/AILab-CVC/YOLO-World
※ 引用
(Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, Ying Shan, YOLO-World: Real-Time Open-Vocabulary Object Detection, https://arxiv.org/pdf/2401.17270)
特徴:
- YOLO v8と同じCNN Backboneを使用。GLIPと同精度かつ20倍早い推論時間を達成
- Vision-Language PANで画像とテキストの特徴量をFusion
- デプロイ時は事前にユーザーが定義したボキャブラリーのText embeddingをモデルパラメータに埋め込み(Re-parameterization)、推論を高速化
使用方法
上記で紹介したOVODモデルは学習済みのモデル重みが公開されているため、推論できる環境(GPU使用がおすすめ)があれば簡単に使用することができます。
ここでは例としてYOLO Worldを動かしてみます。
公式ドキュメントのサンプルコードを参考にカスタムクラスでの推論を行います。
- YOLO関連ライブラリのインストール
pip install ultralytics
- カスタムクラス ("person", "bus") で推論実行
from ultralytics import YOLO
# Initialize a YOLO-World model
model = YOLO("yolov8s-world.pt") # or choose yolov8m/l-world.pt
# Define custom classes
model.set_classes(["person", "bus"])
# Execute prediction for specified categories on an image
results = model.predict("推論したい画像ファイルのパスをここに入力")
# Show results
results[0].show()
以上のようにたった数行のコードで推論の実行が可能です。
GLIPやGroundingDINOの環境構築・推論方法についてはそれぞれのコードリンクからご確認ください。
おわりに
OVODの登場と発展により、これまで自前でモデルを学習させなければならなかったケースでも物体検出を気軽に試すことができるようになりました。
検出したい対象によってはYOLO WorldなどのOVODモデルで十分な精度が出せる場合があるので、まずは試してみることをおすすめします。
一方で、精度面については従来のクラス定義されたデータセットでの教師あり学習に劣るなどの課題もあります。
これからの研究によってその差も縮まってくると期待されるので、最新の動向をキャッチアップしていきます。
