

とあるシステム(クラウドサービス)[1]開発の負荷試験で発生したDBパフォーマンス問題について 原因と対応策の一部をご紹介いたします。
基本的な内容となりますが、機能追加・仕様変更などでも 都度問題がないか確認しておきたい内容となりますので DB周りの設計に不安がある方はご確認いただけると幸いです。
事象
負荷試験のため、RDS(PostgreSQL)の特定のテーブルに大量データを投入したところ、システム全体のスループットが低下する現象が発生しました。
原因
直接的な原因は、定期実行されるバッチ処理内で対象テーブルをシーケンシャルスキャンでアクセスしたことによるキャッシュメモリの圧迫です。
バッチ処理内で定期的にDBのキャッシュメモリを圧迫することで他のキャッシュデータが追い出されてしまい、他処理がキャッシュメモリを利用できなくなることでシステム全体のスループットが低下していました。
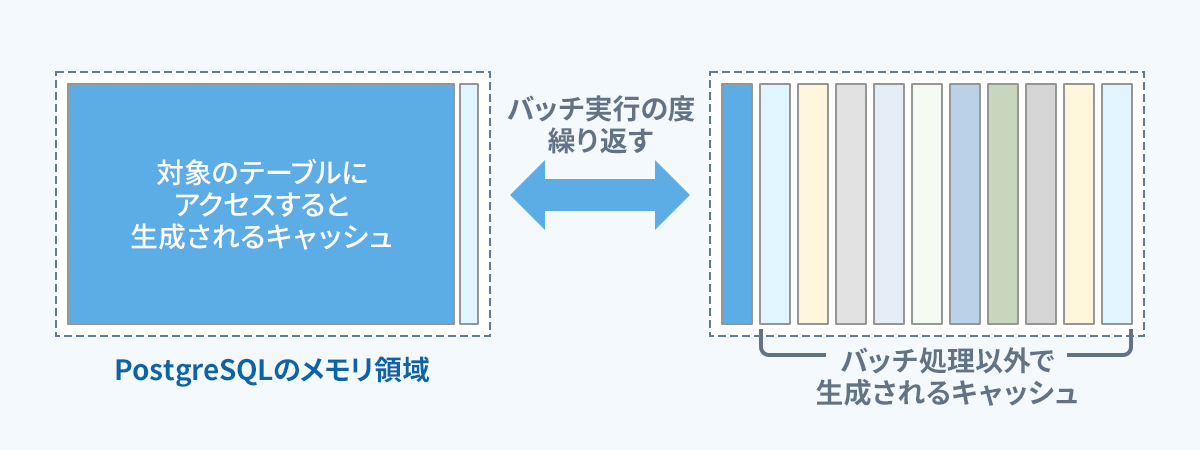
要因の中で特に重要なものをいくつか挙げます。
<要因 ①>
キャッシュ生成メカニズムの理解不足
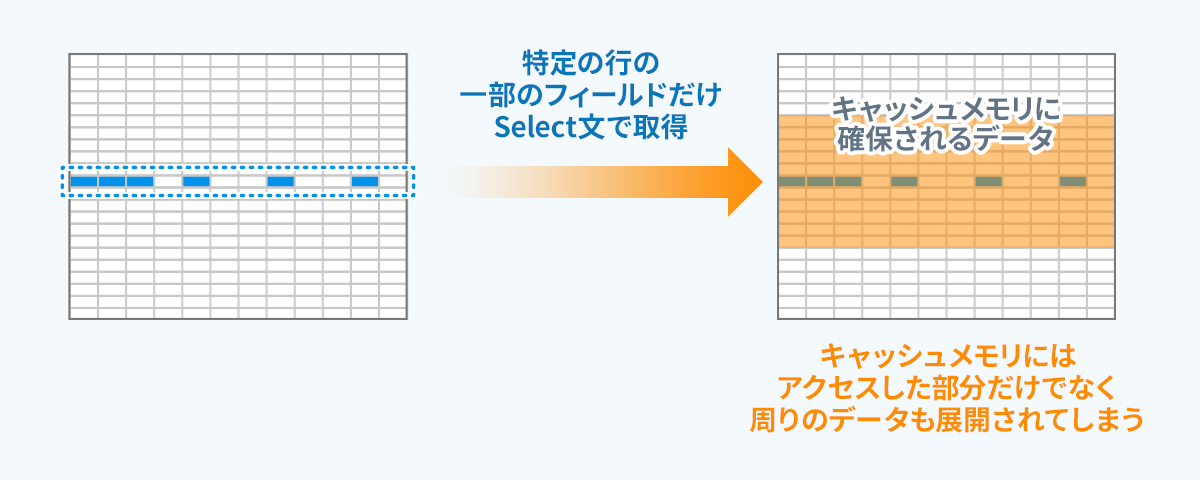
SQLクエリで検索するデータ以外にもキャッシュには以下のようなデータが含まれますが理解不足により意図しないデータもキャッシュを占有してしまっていた。
以下はキャッシュに含まれてしまうデータ
- SELECT句に指定していないカラムデータ
- SELECTしたレコードと同じページ(データ格納単位)内にあるレコードデータ
<要因 ②>
1レコードあたりのデータ容量が大きい。
特定のカラムで最大数十MBのデータが格納される可能性がありました。
1レコードあたりのデータサイズが大きくなると、占有されるキャッシュメモリサイズも大きくなってしまいます。
<要因 ③>
データサイクルの考慮漏れ(データ量の増加)
データサイクルにおけるアーカイブ・削除の考慮が不足していたことにより経年によりデータが増加し続けるテーブルとなっていた。
対応方法
上記で要因として挙げた内容の対応方法となります。
<要因 ①の対応>
要因②③を解消することで消費するキャッシュを抑えることが可能です。
<要因 ②の対応>
RDS(PostgreSQL)に大きなデータサイズを格納するカラムを持つのは性能的にもコスト的にもリスクが発生します。
対応方法としては、Amazon S3などのストレージサービス上で管理し、DBレコードとの関連付け出来るようにしておくことが一案として挙げられます。
対象データをキーに検索を行う必要がある場合には、上記の手法では対応が困難であるため、OpenSearchなど別サービスを併用することも検討することが必要となってきます。
<要因 ③の対応>
大容量データをAmazon S3で管理することでアーカイブは容易となりました。
Amazon S3では、各ユースケースに合わせてアーカイブに適したストレージサービスが展開されていますのでシステム・用途に合わせてサービスを吟味してください。
データ削除のサイクルについては、データとしての価値が無くなる または 著しく低下していることが条件になるかと思います。
削除条件については、責任者の判断を仰ぐなどのプロセスを経て決定するようにしましょう。
システム(クラウドサービス)は、AWSを利用してサービス運用をしています。 ↩︎
