

連合学習(Federated Learning)の基本概念
連合学習は、各デバイスがローカルデータを使用してモデルをトレーニングし、その更新情報のみを中央サーバーに送信します。中央サーバーはこれらの更新情報を集約し、グローバルモデルを更新します。
このプロセスにより、データの非集中化とプライバシー保護が実現されます。
データプライバシーの保護や通信コストの削減が求められる現代において、連合学習は非常に重要な技術となっています。
従来の機械学習と連合学習
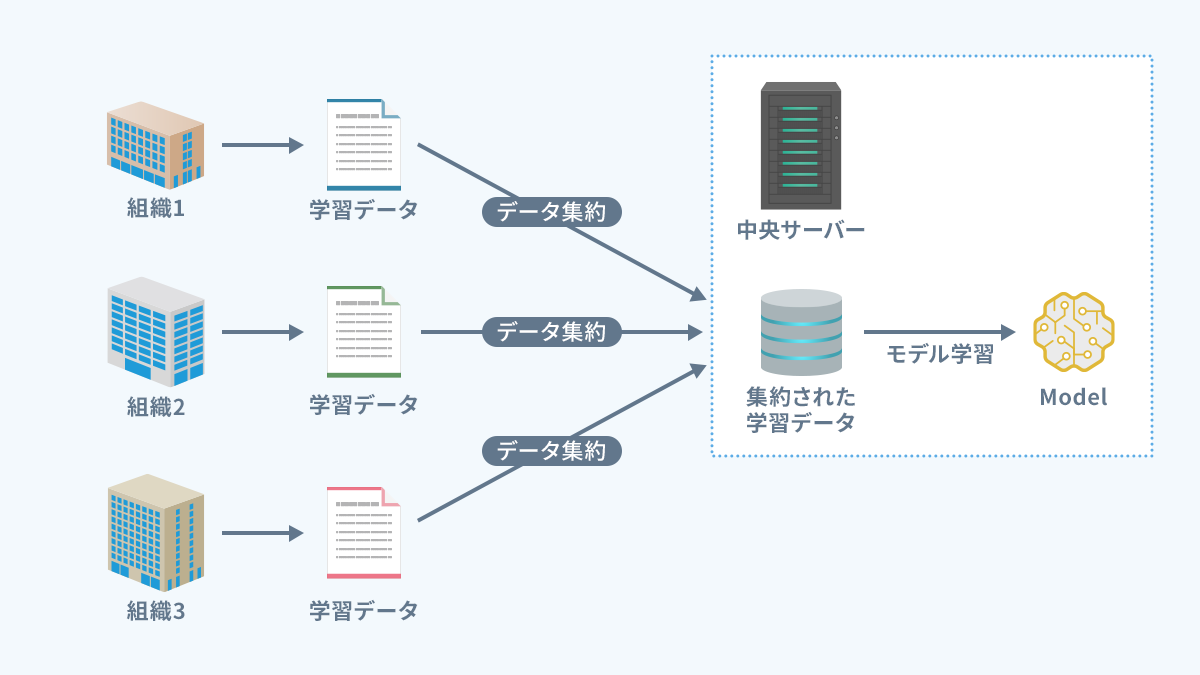
従来の機械学習
- データを中央サーバーに集約し、モデルを学習
- 問題点:プライバシーリスク、転送コスト、サーバーの負荷が集中
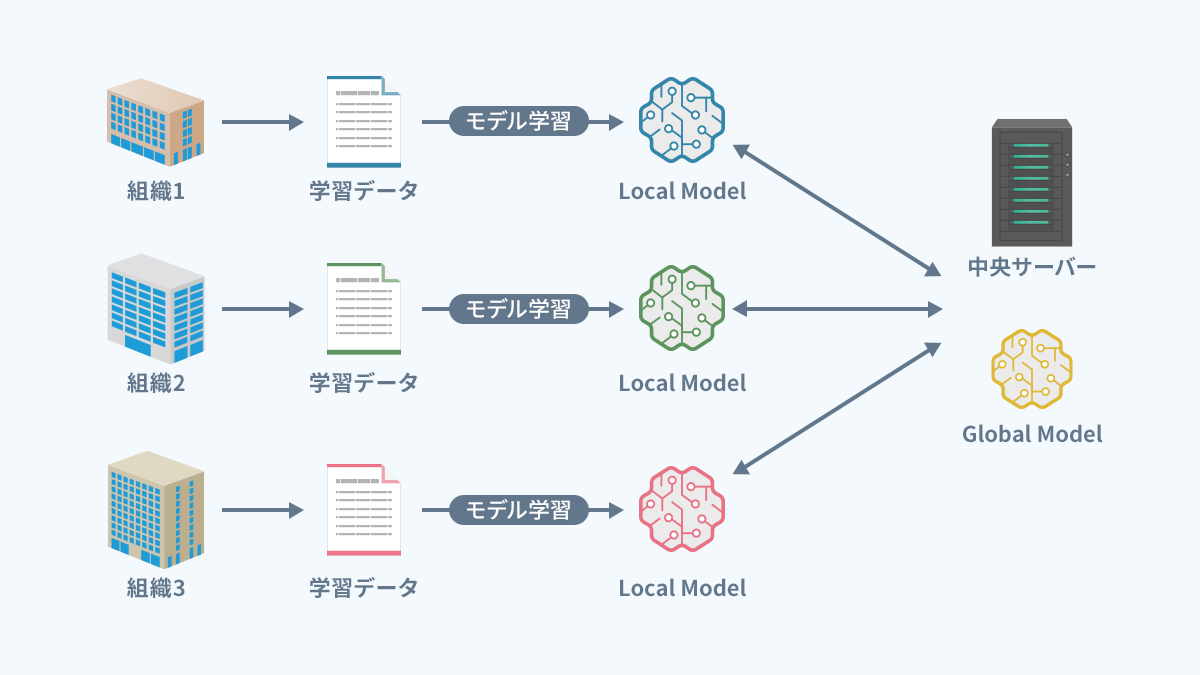
連合学習(分散学習型)
- 初期モデルの配布: 中央サーバーが初期の機械学習モデルを各クライアント(デバイスや組織)に配布
- ローカル学習: 各クライアントは自身のローカルデータを使用して、配布されたモデルをローカルで学習(この際、データは外部に送信されない)
- モデル更新の送信: 各クライアントはローカルで学習したモデルの更新情報を中央サーバーに送信
- モデルの統合: 中央サーバーは受け取った各クライアントからの更新情報を統合し、グローバルモデルを更新
- 更新されたグローバルモデルを再度各クライアントに配布し、上記のプロセスを繰り返す
連合学習フレームワーク「Flower」の紹介
連合学習のためのオープンソースフレームワークで以下のような特徴があります。
- 柔軟なクライアント・サーバーモデルをサポートし、さまざまな機械学習ライブラリと統合可能(PyTorch、TensorFlow など)。
- 大規模な連合学習システムを構築可能。 高いカスタマイズ性と拡張性。
- 連合学習の多様なユースケースに対応可能。
連合学習の課題とRayの活用
連合学習の課題
今回は運用面における課題にフォーカスしてみました。
課題として以下があると思います。
- クライアントの参加・離脱の管理 ←大規模なFLシステムを実装・運用する場合、管理が複雑
- 各クライアントに同じソースコード、環境を用意、学習の実行が必要
⇒Rayを活用してこれらを効率化する方法を考えます。
Ray とは?
分散並列処理を高速かつシンプルに書けるフレームワーク 特に機械学習ワークロードのスケーリングに適している
※その他、一般的には連合学習の課題として下記が挙げられます。
- クライアントごとにデータの分布が大きく異なる場合
- 通信量の削減
- プライバシー保護の保証
Ray クラスター上での連合学習
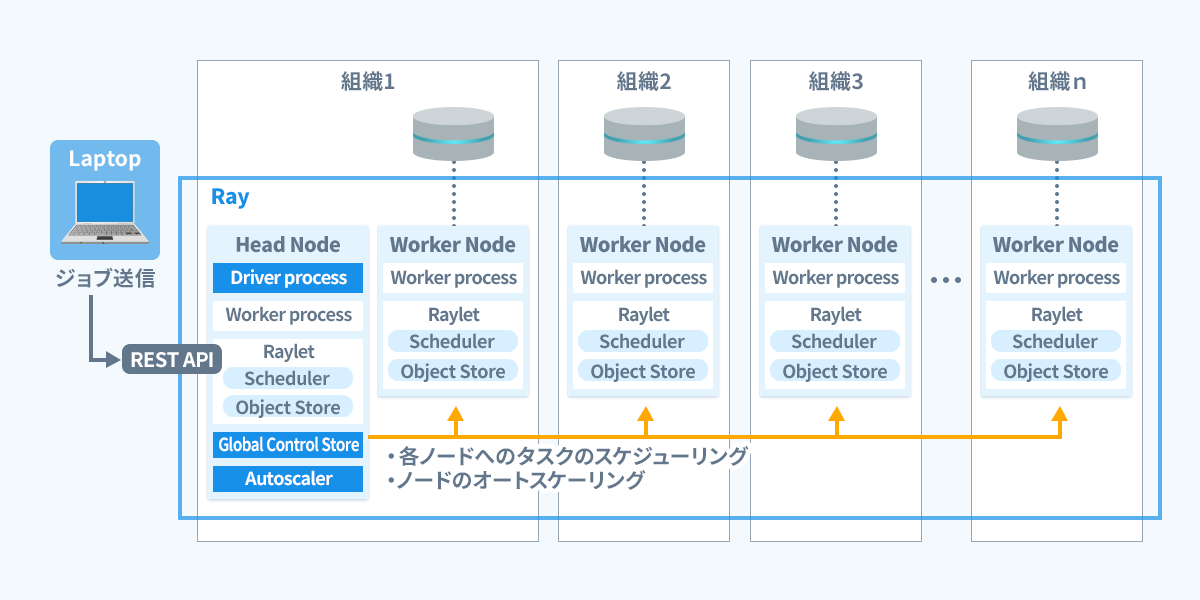
それではRayクラスター上で連合学習を実施する流れを簡単に説明します。
- Rayクラスターを構築。
参考:https://docs.ray.io/en/latest/cluster/kubernetes/getting-started/raycluster-quick-start.html
-
RayのジョブAPIを利用して連合学習ジョブを送信。
-
Ray Headノードが、各計算ノードへタスクをスケジューリングするため、各ノードで処理を実行する手間がなくなります。
必要なライブラリもインストールされます。 -
必要に応じて、計算リソースがオートスケーリングされます。
(利用する計算ノードを指定することも可能です。)
また、計算リソースの参加、離脱も管理し、ダッシュボードからリソースの使用率、各プロセスの実行ログ、ステータスを確認できます。
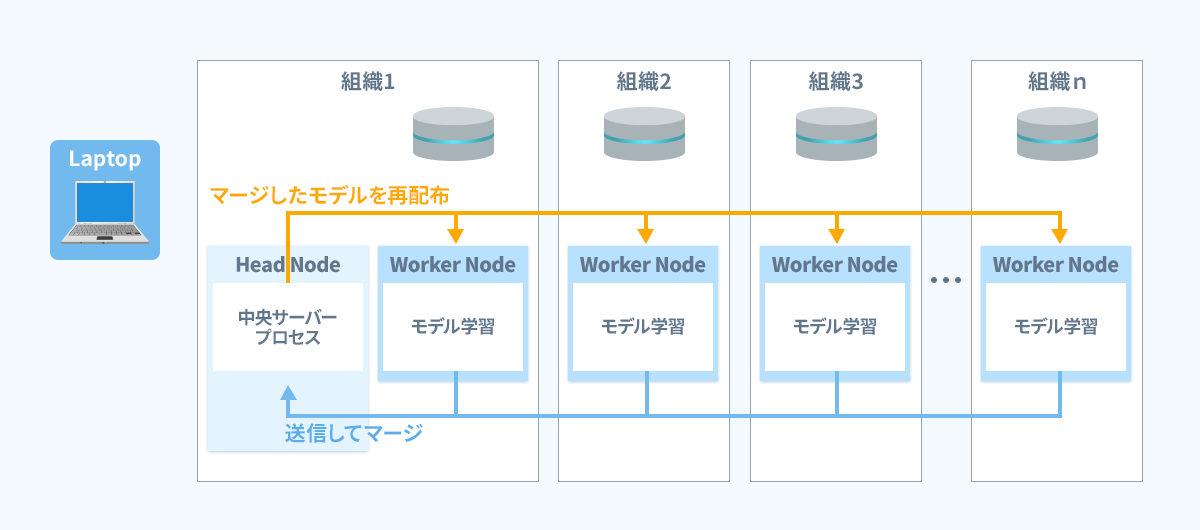
あとは連合学習の流れに沿って処理が実行されます。
まとめ
👌 連合学習とは、データを中央に集約せず、分散したデバイス上で機械学習モデルを学習する手法。
👌 通信コスト削減、データセキュリティを重視した機械学習のアプローチ。
👌 Rayと組み合わせることで、リソースの動的割り当て、クライアントの管理を効率化ができる。
一部画像は引用です。
