

こんにちは!エンジニアさんなら一度は使ったことがある正規表現。これを深く知ることで、仕事の生産性はグッと上がります。今回はその正規表現で比較的よく使われるものを取り上げてみたいと思います。
正規表現とは
正規表現(Regular Expression)は、ソースコードやデータの中にある特定の文字列を検索、置換する際に使用され、特殊な文字を使用することで対象の文字列を特定します。
正規表現は、エディタや統合開発環境(IDE)、プログラミング言語などで使用することができます。
ユースケース
正規表現を使うユースケースとしては以下のようなものが挙げられます。
- ソースコードの特定の情報を検索、置換するとき
- 大量のテストデータに対して、一定のルールにしたがって編集するとき
- プログラムの一部として組み込むとき
(例:ファイルからデータを読み込み、特定のパターンに一致するデータが含まれるかどうか判断するとき)
正規表現(初級編)
特定の文字列の中で同じ文字列が複数ある場所を特定する方法には以下のようなものがあります。
abcxyzcbaazzccyyaaababaxxzyc という文字列に対して、正規表現を使って検索する方法を例に説明します。
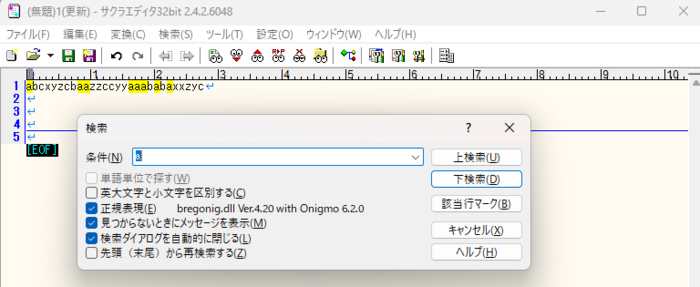
1)正規表現を使わないで「a」だけで検索すると、以下のように複数の「a」がヒットする。
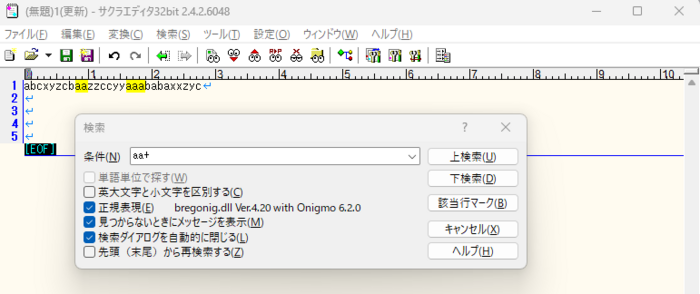
2)「aa」や「aaa」をヒットさせたい場合は、'+'(プラス)を使って抽出する。
| パターン | 説明 | 備考 |
|---|---|---|
| +(プラス) | 直前の文字が1回以上続く | |
| *(アスタリスク) | 直前の文字が0回以上続く | 類似パターン |
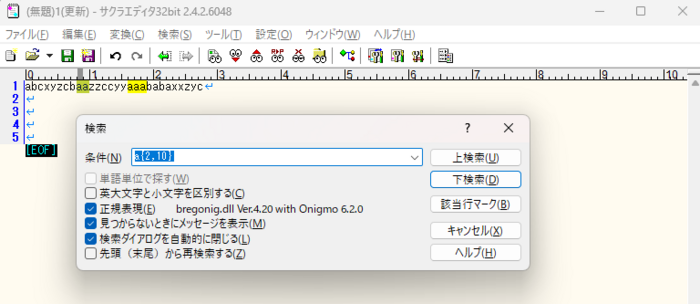
3)「aa」や「aaa」をヒットさせたい場合は、'{回数下限, 回数上限}'(中括弧)を使って抽出する。
| パターン | 説明 | 備考 |
|---|---|---|
| {2,10} | 直前の文字を2回以上繰り返し、10回以下まで繰り返す | |
| {2,} | 直前の文字を2回以上繰り返す | 類似パターン |
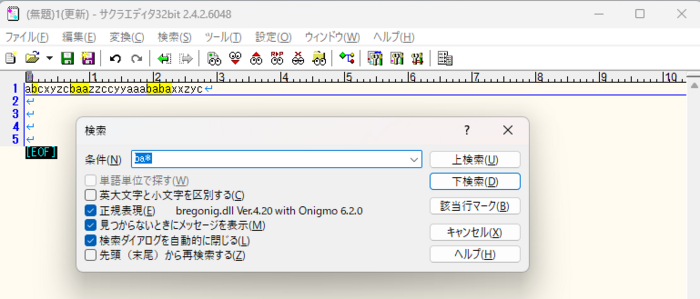
4)「b」や「ba」や「baa」をヒットさせたい場合は、'*'(アスタリスク)を使って抽出する。
| パターン | 説明 | 備考 |
|---|---|---|
| *(アスタリスク) | 直前の文字が0回以上続く |
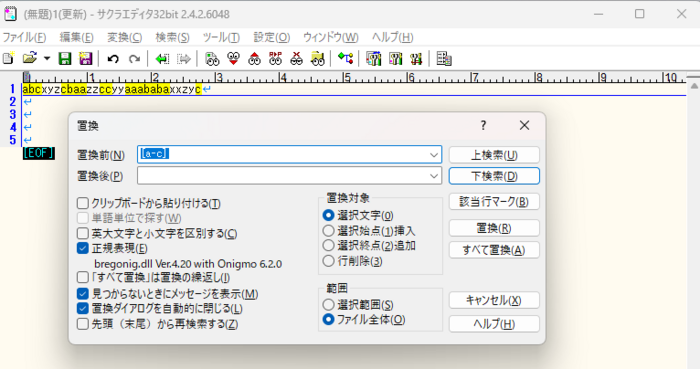
5)「a」から「c」までの文字をヒットさせたい場合、'[]'(角カッコ)と-'(ハイフン)を使って抽出する。
| パターン | 説明 | 備考 |
|---|---|---|
| [](角カッコ) | 角カッコ内の任意の位置文字に一致する | |
| -(ハイフン) | ある文字からある文字の範囲指定を表します | a-cの場合、abcが対象となります |
正規表現(中級編)
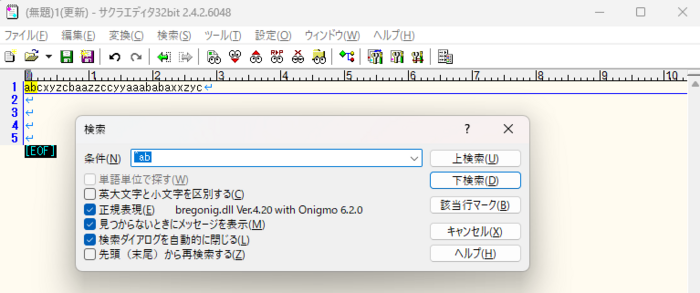
1)行頭の「ab」だけをヒットさせたい場合、'^'(キャレット)を使って抽出します。
| パターン | 説明 | 備考 |
|---|---|---|
| ^(キャレット又はハット) | 行の先頭を表します |
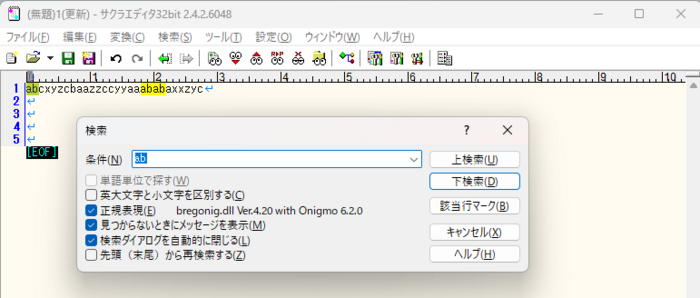
2)上記の検索で'^'(キャレット)を指定しないと、文字列の複数個所で検索にヒットします。
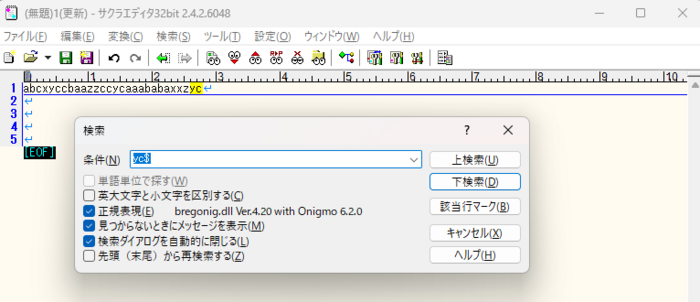
3)行末の「yc」だけをヒットさせたい場合、'$'(ドル記号)を使って抽出します。
| パターン | 説明 | 備考 |
|---|---|---|
| $(ドル記号) | 行の末尾を表します |
4)上記の検索で'$'(ドル記号)を指定しないと、文字列の複数個所で検索にヒットします。
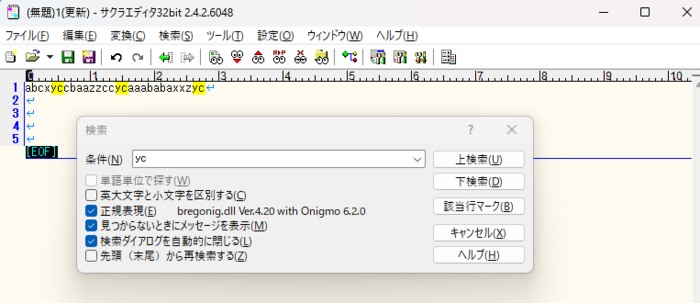
正規表現(上級編)
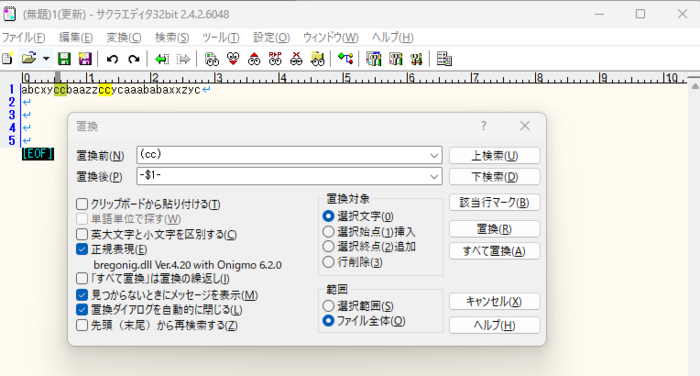
1)「cc」をヒットさせ「-cc-」と置換したい場合、'()'(丸カッコ)を使って抽出します。
| パターン | 説明 | 備考 |
|---|---|---|
| ()(丸カッコ) | カッコ内に書かれている文字をグループとして扱えます。 また、置換では()を$1、$2などで後で参照することもできます。 | カッコ内にはパターン('.'、'+'、'*'など)を含めることができます。 |
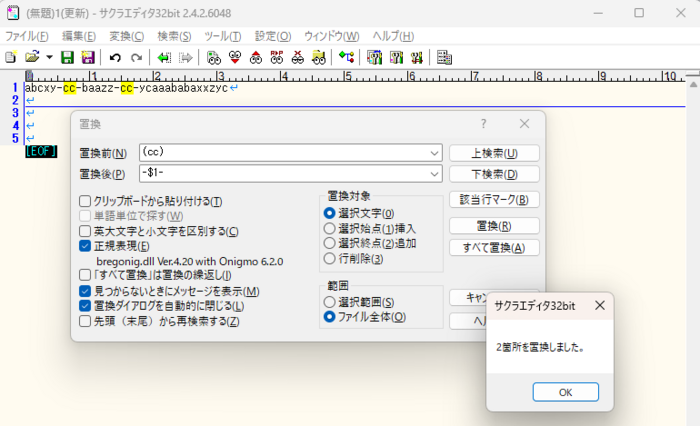
置換後は、次のとおりです。
終わりに
上記は、正規表現のほんの一部の特殊文字を使って正規表現で様々な文字列の抽出方法を紹介しました。
正規表現はとても奥が深いです。
正規表現だけの技術本もあるくらいで、知的好奇心がくすぐられます。
もし、興味が湧きましたらご自身でも調べたり、ご自身でも取り組んでみたりしてください。
