

日常で見ないことがない「文字」。
そんな「文字」はコンピュータ上ではどのように扱われているのでしょうか?
① 文字の扱い~文字コード
例えば「A」という文字を題材にしてみましょう。コンピュータの世界では「A」という文字は多くの場合、16進数で「0x41」という1バイトのデータとして扱われます。
この「A=0x41」のような文字とデータ(値)の組み合わせを「文字コード」と呼びます。
「0x41」というデータが登場した際に、「0x41はA」ということが明らかなため、「A」を表示するために必要な画像(フォント)と引き当てを行い、モニターに「A」という文字を表示します。
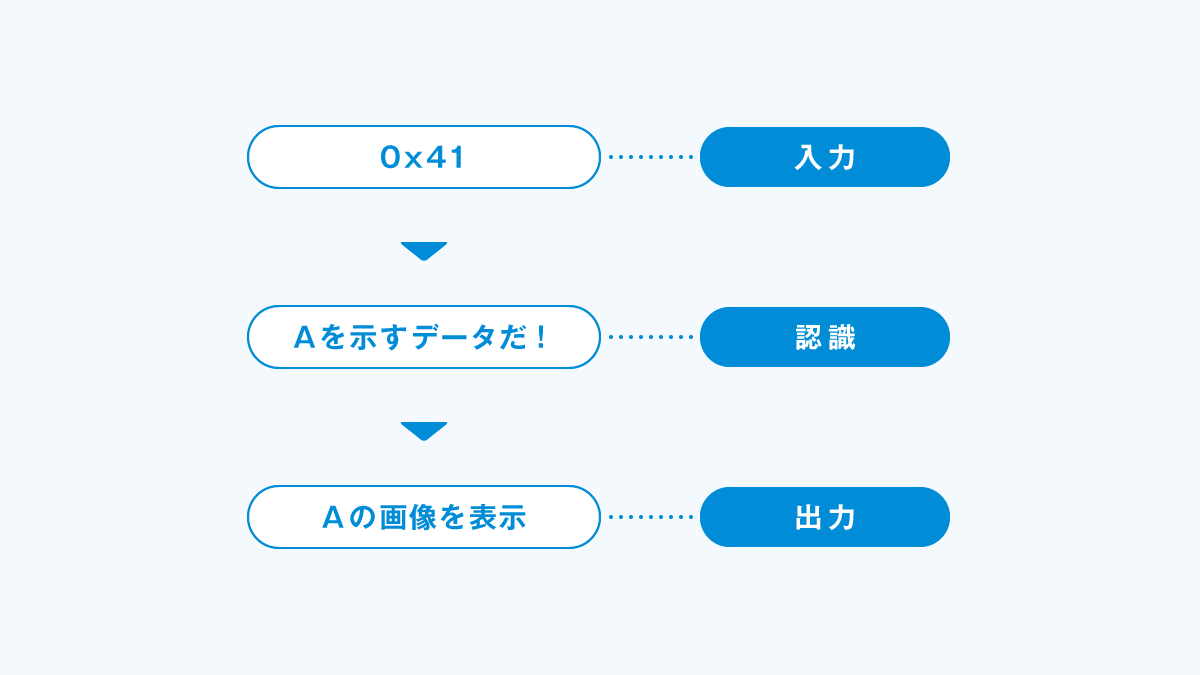
このような文字コードの組み合わせの群を「文字コード表」と呼び、様々な文字コード表が存在します。
古典的で代表的な文字コード表として「ASCIIコード」という7bitのコード表が存在します。
② 多様な文字コード表
ASCII以外にも多様な文字コード表が存在します。
日本でよく扱われるものとしては、
- JISコード表(ISO-2022-JP)
- Shift-JISコード表
- Unicodeコード表
など、より効率的に、より多様な言語文字に対応できるように進化を遂げてきました。
③ 困ったこと
文字コード表も進化を遂げてきましたが、困ったことが発生しました。
進化の過程で世の中に「複数の文字コード表」が共存することになり、
- 「このデータはJISコード表で記述されている」
- 「このデータはShift-JISコード表で記述されている」
- 「このデータはUnicodeコード表で記述されている」
ということを「識別」することが難しい(またはできない)という問題です。
文字コード表を識別できない場合、どのような問題が発生するか、実例を見てみましょう。
- パターンA:Shift-JISで記述されたファイルをUnicodeだと思って開いてみる。

- パターンB:Unicodeで記述されたファイルをShift-JISだと思って開いてみる。

どうでしょうか。何が何だかわかりませんよね。これは同じ文字を示すコードが「コード表間で異なること」が原因です。
例えば「文字」という文字を表す文字コードを確認してみましょう


このように、同じ「文字」でもそれを表す文字コード(データ)が異なることがわかります。
④ 解決方法
このような事態を避けるために対策としては「このデータは何の文字コードで記述されているか」を事前に通知する必要があります。
【Webサイト(HTML)】
HTMLでは「meta charset」tagにて文字コードを指定することができます。

【テキストファイル】
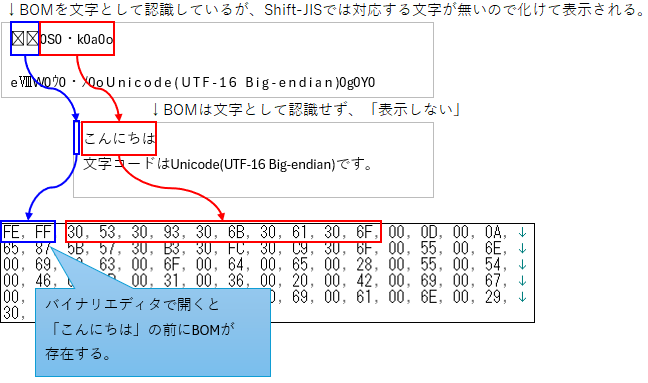
テキストファイルの場合、UnicodeなどではBOM(ビット・オーダー・マーク)という、特別なデータがファイルの先頭に記述されていることがあり(※)、事例に挙げている「Unicode(UTF-16 Big-endian)」の場合は「0xFE,0xFF」という2バイトのデータが先頭に付与されています。
※必須ではない為、ない場合も……。
BOMが存在する場合は「Unicodeの何かしらのパターンで記述されている」ことがわかる為、BOMに対応するUnicodeの解釈の仕方をすることが可能です。
実はこれ、これまでの説明で登場しており、UnicodeのファイルをShift-JISで開いた際の先頭にある文字化けはこのBOMが文字化けしたものだったんです。
⑤ 締め
いかがでしたでしょうか。文字がどのようにコンピュータ上で扱われているかについて理解ができたでしょうか。
文字コードについては各言語、各国の産業規格、ベンダーの独自規格など、一筋縄ではいかない経緯がある為、中々解決しない問題ですが、昨今はUnicodeが主流になりつつあり、一定の標準化が進められています。
皆さんが日頃見る「文字」がどのように扱われているのかの理解に繋がれば幸いです。
