

はじめに
近年の技術の発展に伴い、様々な新しいデータ形式が登場しています。今日はその一つであるマイクロスケーリングフォーマットについて紹介します。
参考文献
- Bita Darvish Rouhani ほか, 「Microscaling Data Formats for Deep Learning」, arXiv, 2023年
- ocp-microscaling-formats-mx-v1-0-spec-final-pdf
マイクロスケーリングフォーマットとは
マイクロスケーリングフォーマットは、数値の表現方法の一つです。
FP32やFP16のようなデータ形式のオプションの一種と考えていただければと思います。
NVIDIAのBlackwellアーキテクチャから対応しており、低ビット幅でも高い精度を保てるといわれています。
マイクロスケーリングフォーマットの仕組み
マイクロスケーリングフォーマットは、ブロック(データのまとまり)ごとに共通のスケール係数を持ちます(下図参照)。
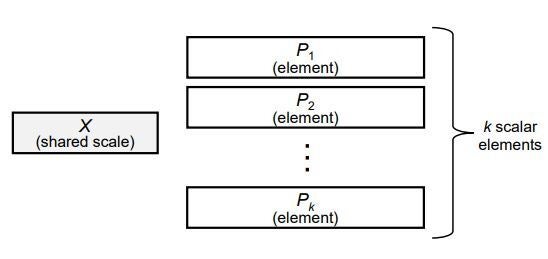
引用
"shared scale"が共通のスケール係数を示し、"element"がブロックの各データの要素、"k"はブロックの構成するデータの数を示しています。 ざっくりしたイメージにはなりますが、ある数値Aをマイクロスケーリングフォーマットで表すと、
A= Aに割り当てられたスケール係数(shared scale) × Aのデータ要素(element)
という関係が成立します。(※あくまでイメージです)
このとき各データの要素のデータ形式は基本的に何でもOKで、FP8に適応する場合にはMXFP8とMXを付けて記載します。
この仕組みによって、以下のメリットがあります。
- ブロック内のデータを適切な範囲に収めることができる
- データ全体を見たときに、様々な傾向やパターンを保持することができる
例えば、FP8(E4M3)は±448までしか表すことができませんが、マイクロスケーリングフォーマットを適応すると、より大きな範囲のデータを表すことができます。
また、Transformerでよく行われる内積計算では、スケール係数同士、データ同士を計算するだけで済むため、データ形式が変わっているにも関わらず、計算の効率は大きく低下しません。
どのくらい凄いの?
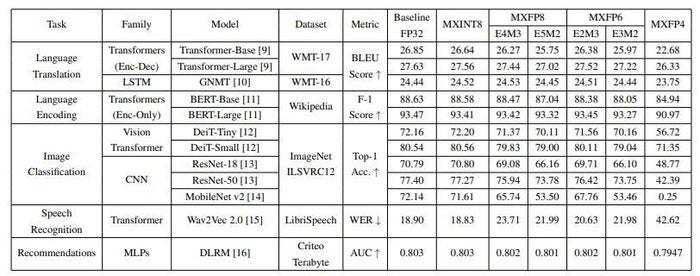
論文では、PTQ(学習後の量子化、通常精度が落ちる)であっても、MXINT8(データ部がINT8)でFP32と同等程度の精度が出ると述べています(下図参照)。
たしかにFP32(Baseline FP32)とMXINT8で、どのタスクでも精度がほとんど変わっていません。
引用
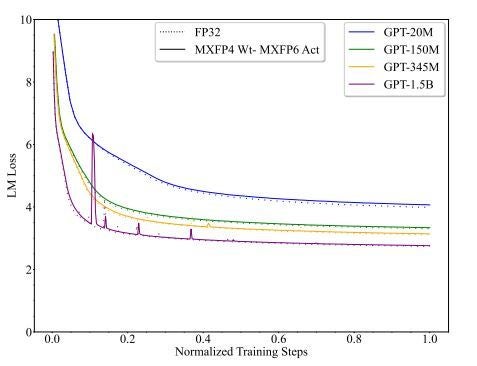
また、同じ論文では、LLM(大規模言語モデル)の重みをMXFP4、アクティベーション(中間の入出力)をMXFP6とした場合、FP32と同じような学習ができると述べています(下図参照)。図はLoss(損失)のグラフを表していますが、点線(FP32)と実線(MXFP4-MXFP6)がほぼ重なっていることが分かります。
引用
凄いですね。
最後に
マイクロスケーリングフォーマットは、ディープラーニングの速度と精度を両立させるための革新的な技術の1つです。今後の研究の進展によって、さらに多くの応用が期待されます。これからも注目していきたい技術の一つですね。
Tech Blogを最後までお読みいただき、ありがとうございました。
