

今回はViTの性能について勉強したいと思い、
ViTの性能を取り入れたMobileViTと取り入れていないMobileNetの2つのAIモデルによる精度比較を行いました。
ViTの性能について理解を深めた際の自己学習を紹介いたします。
前述の2つのモデルについては、後ほど説明いたします。
突然ですが、ここにあみだくじ画像があります。
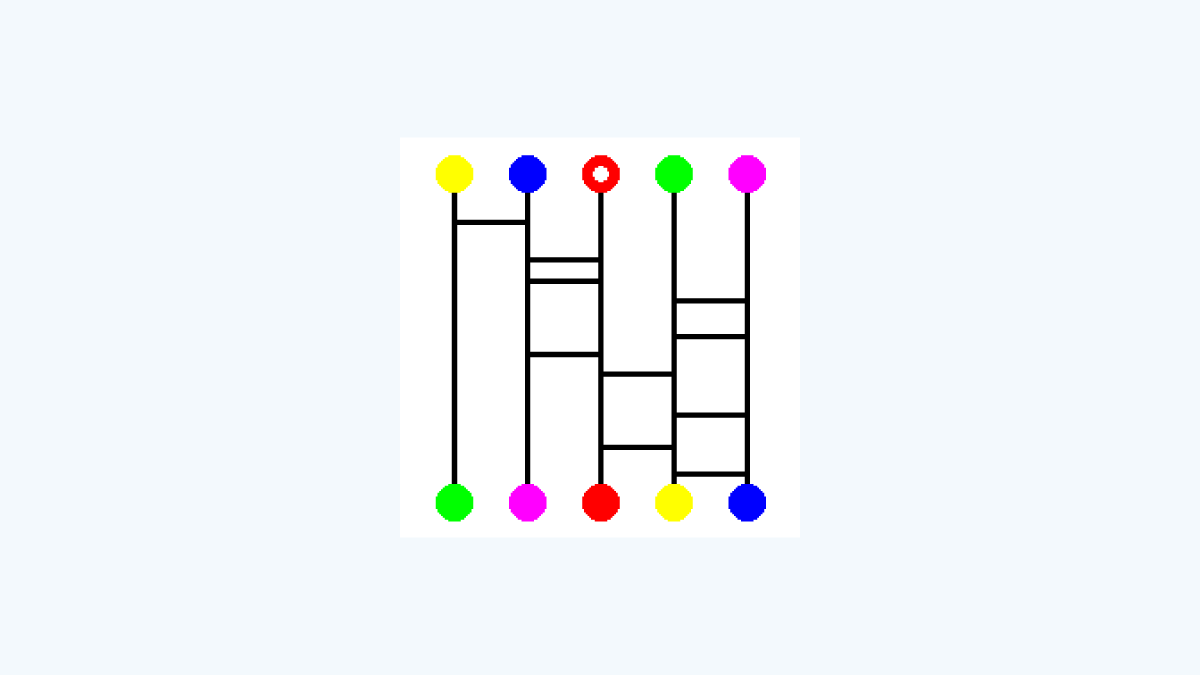
上段の5つの丸のうち、1つだけ白丸が描かれています。
この白丸が描かれた箇所をスタート地点とすると、ゴールは左から2番目のピンクの丸になります。
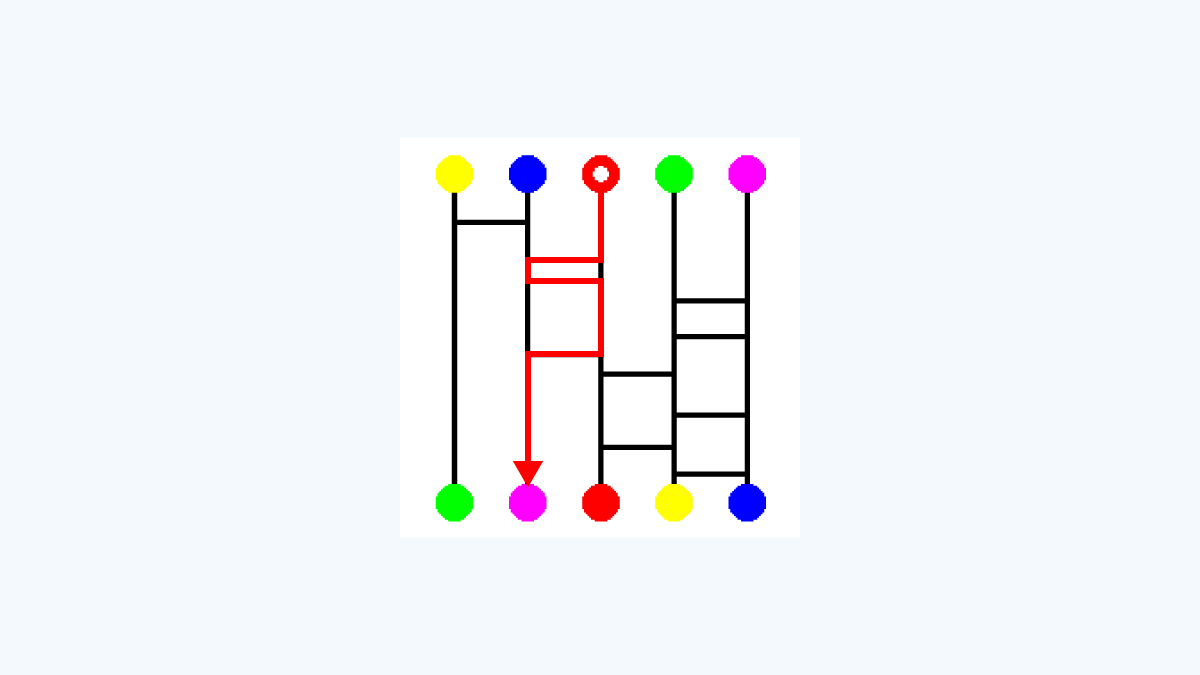
ここまでは、普通のあみだくじです。
今回は、「ワープ付きあみだくじ」を実施します。
つまり、ゴールした後に、同じ色の上段の丸にワープし、
再度スタート地点としてあみだくじを辿り直した際のゴール位置が最終的なゴールとなります。
例えば、前述のようにピンクの丸に辿り着いた場合、
その後は上段のピンクの丸から再スタートします。
その結果、最終的なゴールは「左から3番目の赤丸」になります。
補足ですが、今回はたまたまスタートとゴールの色が一致しておりますが、
必ずしもそうなるとは限らないようにデータセットを作成しています。
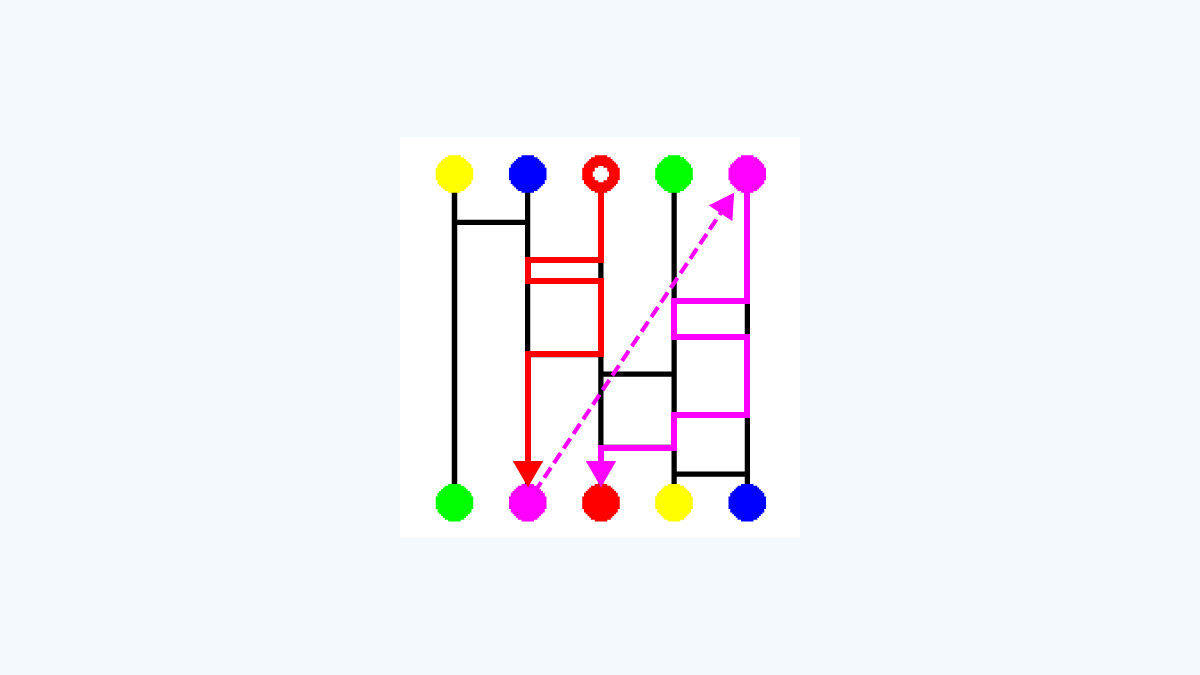
今回は、この「ワープ付きあみだくじ」を以下の2つのAIモデルに学習させて、
その性能を比較することを目的とします。
1.MobileNet(軽量な畳み込みニューラルネットワーク)
2.MobileViT(Vision Transformerを取り入れたモデル)
MobileNetとは?
MobileNetは、スマートフォンやエッジデバイス向けに設計された軽量な畳み込みニューラルネットワーク(CNN)です。
通常のCNNよりも計算量を抑える技術を採用しており、高速かつ省メモリで動作します。
MobileViTとは?
MobileViTは、CNNの特徴とViT(Vision Transformer)の強力な表現力を組み合わせたモデルです。
ViTは画像全体の関係性を学習するのが得意なため、従来のCNNよりも広範囲の特徴を捉えることができます。
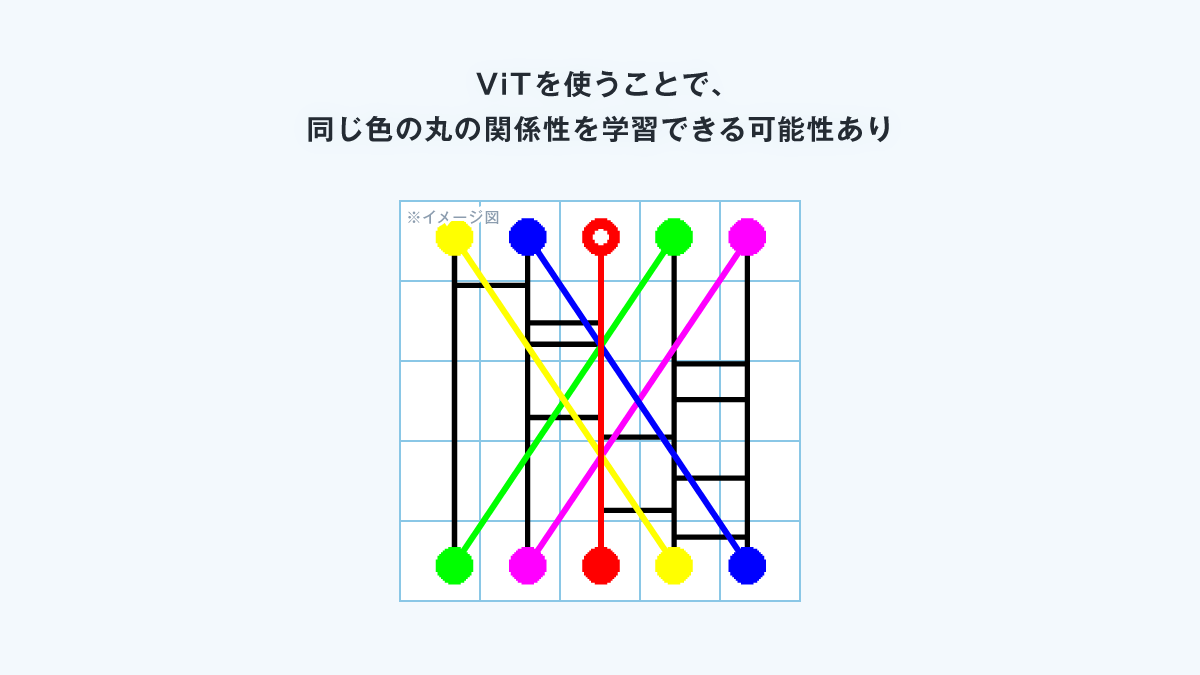
このMobileViTが、ワープ付きあみだくじのような「離れた位置にある上下の同じ色の丸の関係性」を学習できると仮定しました。
つまり、MobileViTはワープのルールを学習できる可能性がある
という仮説のもと、AIを学習させました。
学習方法
今回はいきなりワープ付きあみだくじを学習させるのではなく、段階的に学習させます。
【1. ワープなしのあみだくじを学習】
- データ数 :20,000件
- 目的 :通常のあみだくじのルールを学習
【2. ワープ付きあみだくじでファインチューニング】
- データ数 :50,000件
- 調整方法
- MobileNetは最初の5層を固定
- MobileViTは畳み込み部分(conv_stem, bn1)+Transformerの前半部分を固定
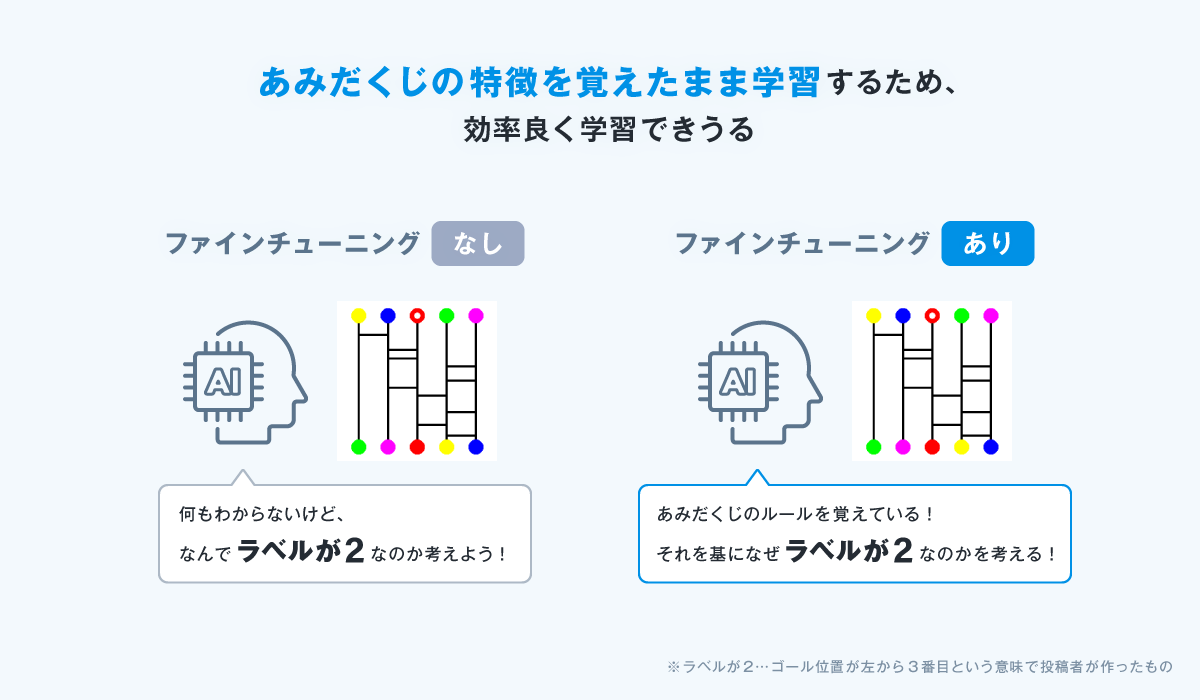
こうすることで、最初にあみだくじの基本的なルールを学習し、
その上でワープの概念を学習できるようにしました。
なお、ゴールの予測は「5クラス分類」(左から0, 1, 2, 3, 4)で行います。
実験結果
【ワープなしあみだくじの精度】
- MobileNet:99.70%
- MobileViT:97.05%
MobileNetの方が2.65%高い結果となりました。
これは、ワープなしのあみだくじでは局所的な特徴のみで推論が可能なため、
広範囲の情報を学習するViTがかえって不利になったと考えられます。
【ワープ付きあみだくじの精度】
- MobileNet:21.30%
- MobileViT:92.72%
MobileNetはほぼ学習できておらず、ランダム推測(20%)に近い結果となりました。
一方、MobileViTは90%以上の精度を達成しました。
時間の関係上、途中で止めてしまいましたが、まだまだ精度は収束していないように感じました。
学習の可視化(Grad-CAMとは?)
学習結果を分析するために、「Grad-CAM」という技術を使いました。
Grad-CAMとは?
Grad-CAM(Gradient-weighted Class Activation Mapping)は、
AIモデルが画像のどの部分に注目しているかを可視化する手法です。
AIが「どこを見て判断したのか?」を視覚的に確認することができます。
例えば、画像分類のAIが猫の写真を見て「耳」や「目」に注目しているのか、
それとも背景を見ているのかを確認できます。
今回は、MobileViTがワープの概念を学習できたかを確かめるために使用しました。
【ワープなしあみだくじ】
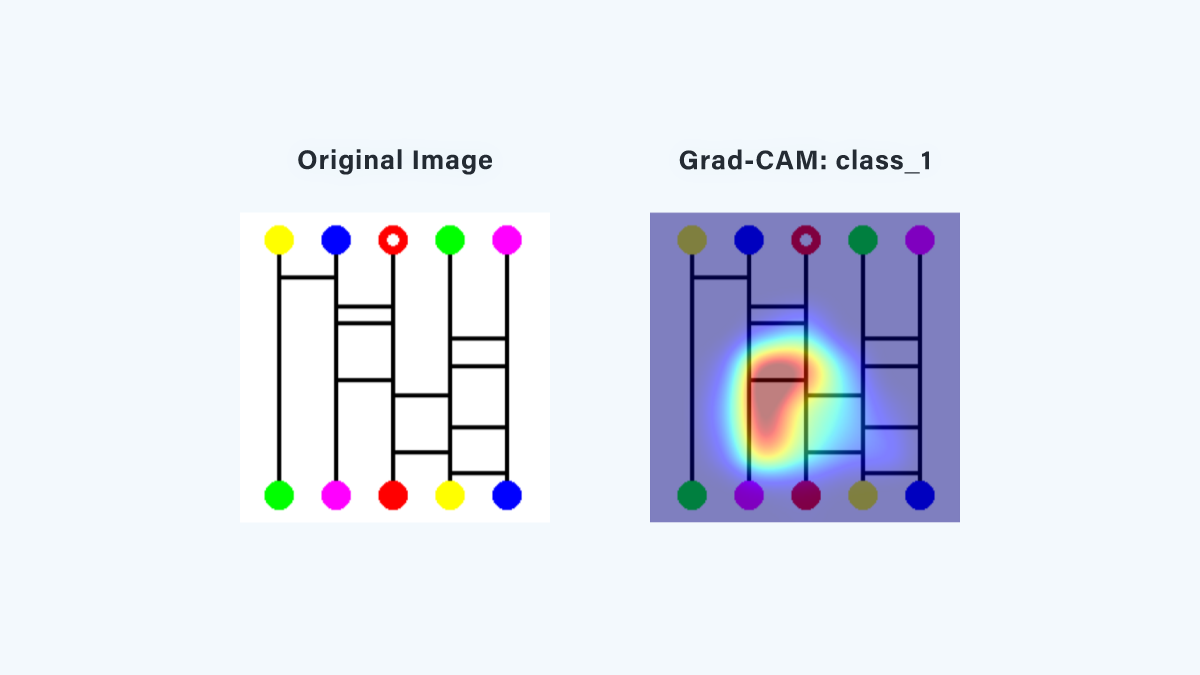
このヒートマップを見ると、実際に通るあみだくじの線(ルート)に注目していることがわかります。 つまり、ルートに注目することで正しくゴールを予測できるということです。
【ワープ付きあみだくじ】
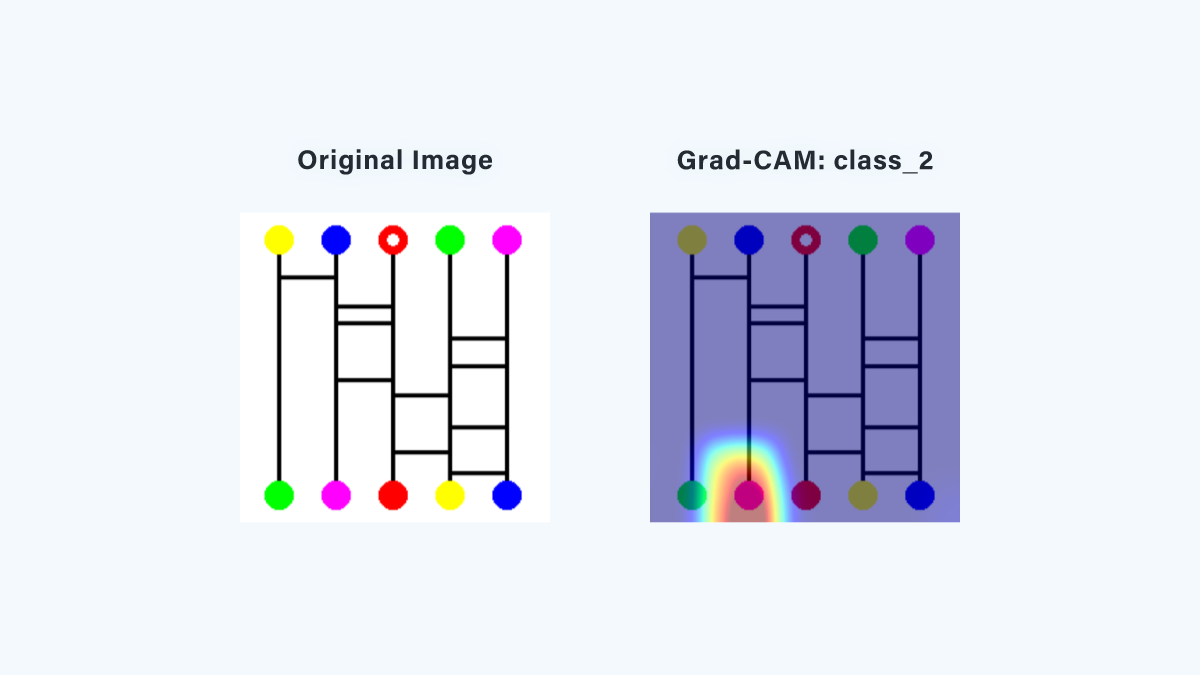
ワープ付きあみだくじでは、下段のピンクの丸に強く注目していることがわかります。
これは、AIが「ワープ後のゴールの情報を学習できた」ことを示唆しています。
具体的には、下段のピンク丸に、上段のピンク丸からのゴール位置の情報が含まれていると考えられます。
この結果は、MobileViTがワープの概念を理解し、ゴールの位置を正しく予測できるようになったことを示しています。
まとめ
今回は、ワープ付きあみだくじをAIモデルに学習させ、MobileViTがルールを理解できるか検証しました。
- MobileNetは局所的な特徴に強いが、ワープのような長距離の関係を学習できない
- MobileViTはTransformerの力を活かし、ワープの関係を学習できた
- Grad-CAMを用いた可視化により、MobileViTがワープの情報を利用して推論していることも確認
今回の実験から、MobileViTは長距離の関係性を学習するのに適していることがわかりました。 これにより、今後のAIモデルの設計において、Transformerベースのアプローチが有効であることが示唆されます。
以上、私の自己学習の投稿でした。 最後まで読んでいただきありがとうございます。
