

SKYPCEはSaaSとして提供されるサービスであるため、新規機能開発において、AWSを用いた開発が多く行われています。
今回の機能の構成
今回の機能は、以下のような構成になっています。
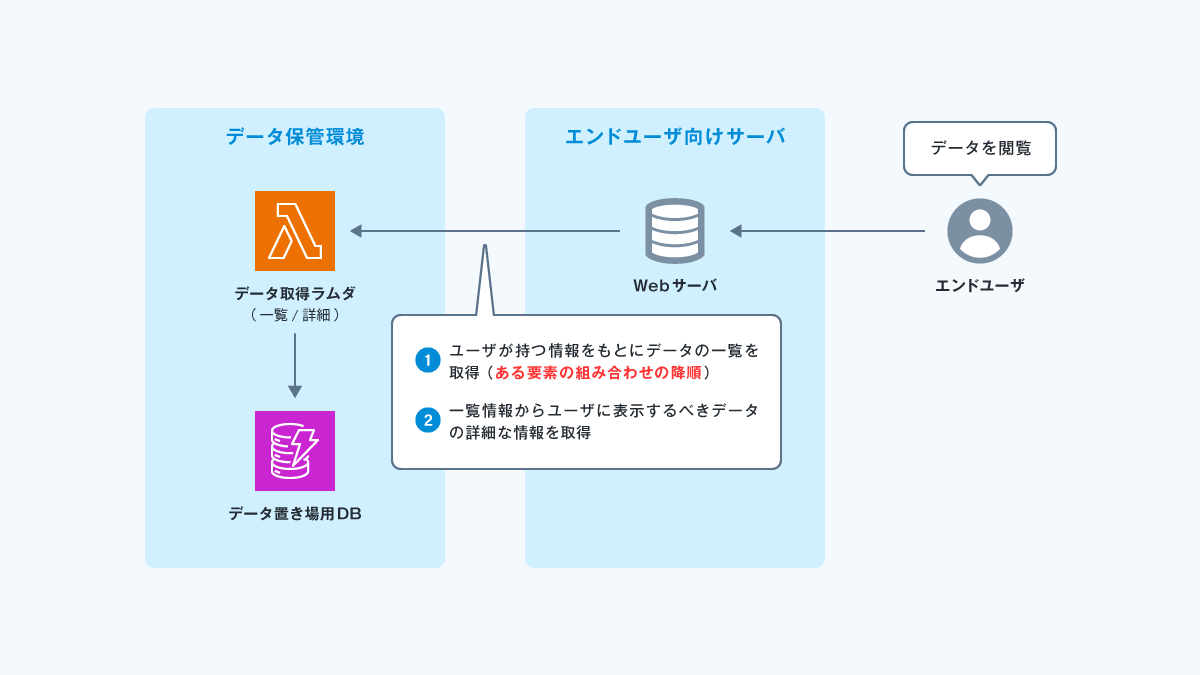
機能の詳細
今回開発する機能では、大量のデータからユーザーのリクエストに応じたデータを検索して画面表示させるために、AWS側でソート、ページングの機能を搭載する必要がありました。
さて、AWS側でソート / ページングするとなると、その機能を持つリソースを使う必要があります。最初に思いついたのは、検索機能が充実している"AWS OpenSearch Service"でした。
AWS OpenSearch Serviceとは
「AWS OpenSearch Service」とは、簡単に言うと、便利な検索が高速にできるものです。もちろん、ソートやページングも余裕でできます(いくつか制限はあります)が、非常に高額であるため、それに見合うような使い方をする必要があります。
今回の要件では、データ中の特定のキーの組み合わせでソート/ページングできれば充足するので、比較的に高額な"AWS OpenSearch Service"を使うほどのものではありません。
コストを抑えたソート / ページング機能の実現
まず「DynamoDB」の存在を思い出しました。
DynamoDBとは、"サーバレスなフルマネージド型のNoSQLデータベースサービス"で、簡単に説明すると「サーバ構築などの必要がない、SQL言語を使わずに使えるDB」です。
データのスキーマを事前に定義する必要がないので、多様なデータに対応できます。主キーさえあればいいので、以下のようなデータを持たせることができます。
| PartitionKey | SortKey | data1 | data2 |
|---|---|---|---|
| 1 | - | XXX | (なし) |
| 2 | - | (なし) | YYY |
| 3 | - | WWW | ZZZ |
※PartitionKeyとSortKeyをあわせてPrimaryKeyと呼び、PrimaryKeyは一意である必要があります(PartitionKeyは必須)。
ただし、弱点もあり、複雑なクエリを実行するのがとても苦手です。データの検索をするにも「フルスキャン」と「クエリ」の2択しかありません。
フルスキャンとクエリ
フルスキャンはその名の通り、テーブル全体を検索して探していく方法で、条件指定をすることで必要なデータを取得しますが、母数が大量のテーブルには不向きです。
クエリはプライマリキー (パーティションキーとソートキー) を指定して特定の範囲のアイテムを検索することができますが、構成を工夫する必要があります(詳しくはコチラ)。
これだけではほとんどやりたいことができないため、DynamoDBではグローバルセカンダリインデックス(GSI)やローカルセカンダリインデックス(LSI)というそれぞれにプライマリキーを持つインデックスを作成することができます。
GSIの活用例
例えば、以下のようなDBがあって、
| PrimaryKey | 部署 | 名前 | 年齢 | 入社年 |
|---|---|---|---|---|
| 1 | 部署1 | A | 22 | 2020 |
| 2 | 部署2 | B | 23 | 2021 |
| 3 | 部署3 | C | 41 | 1990 |
| 4 | 部署1 | D | 42 | 1995 |
| 5 | 部署2 | E | 45 | 2010 |
| 6 | 部署3 | F | 33 | 2013 |
| 7 | 部署1 | G | 31 | 2025 |
| 8 | 部署2 | H | 35 | 2015 |
「部署1だけを取りたい」「部署2をAge順にソートして出したい」という場合はDepartmentをPartitionKey、AgeをSortKeyにしたGSIを構築したうえで、GSIに対して取得したい対象の部署を指定してクエリすることで狙ったデータだけを取ることができます。
※クエリはPartitionKeyを一つしか指定できないため、「部署1と部署2を両方とりたい」という場合は分けてクエリするか、専用のGSIを構築する必要があります。
今回の要件
今回の要件でやりたかったことは、例えば上のデータを例にすると、エンドユーザが指定した「部署」にヒットした人のデータを「年齢+入社年月」の降順に取得することだったので、以下のようにDynamoDBにデータを持たせることで
- 「部署」をPartitionKeyに、「年齢と入社を組み合わせたもの」をSortKeyにしたGSIでクエリして元テーブルの「PrimaryKey」を取得する
- GSIでとれた元テーブルの「PrimaryKey」から本データを取ってくる
というように、2段階でデータを取得するようにしています。
| PrimaryKey(PK) | 部署(GSIのPK) | 名前 | 年齢 | 入社年 | 年齢+入社年(GSIのSK) | その他の情報 |
|---|---|---|---|---|---|---|
| 1 | 部署1 | A | 22 | 2020 | 22#2020 | (data) |
| 2 | 部署2 | B | 23 | 2021 | 23#2021 | (data) |
| 3 | 部署3 | C | 41 | 1990 | 41#1990 | (data) |
| 4 | 部署1 | D | 42 | 1995 | 42#1995 | (data) |
| 5 | 部署2 | E | 45 | 2010 | 45#2010 | (data) |
| 6 | 部署3 | F | 33 | 2013 | 33#2013 | (data) |
| 7 | 部署1 | G | 31 | 2025 | 31#2025 | (data) |
| 8 | 部署2 | H | 35 | 2015 | 35#2015 | (data) |
ページングの実現
「部署」の単位でソートして取ることができることは分かったとして、「ページングはどうするの?」という疑問が残ります。
実は、UI(AWS コンソール)では見えませんが、クエリAPIやスキャンAPIを実行した際に取得上限に達すると、「LastEvaluatedKey」という「次データを取るならココ!」というしおりのようなデータが得られます。
クエリAPIにこのLastEvaluatedKeyを指定して取得すると、なんと続きからデータが得られます(詳しくはコチラ)。
そのため、ページング機能も無事に搭載することができました。
まとめ
今回は、DynamoDBでのソート/ページング方法についてまとめてみました。
DynamoDBは少し扱いづらい部分はありますが、最初に考えたOpenSearch Serviceを使わなくても工夫次第で費用もぐっと抑えることができました。
他の要件でも、「これしかない!」と固執せずに「他に工夫できるところはないか」と模索することでよりよい構成になるのではないかと感じています。
本記事が少しでも皆様のお役に立てれば幸いです。
