ファインチューニングとは? 仕組みや実施手順をわかりやすく解説

ChatGPTをはじめとしたAIを業務に活用したいと考えるとき、大きな課題となるのが「自社の業務にどのように適応させるのか」という問題です。一般公開されているモデルの多くは、膨大なデータから学習した汎用性の高さが魅力である反面、専門的なタスクには向かないことも少なくありません。これを解決する手法の一つに、「ファインチューニング」があります。この記事では、ファインチューニングの概要や仕組みといった基礎知識から、実施の手順や学習データ例までをご紹介します。
ファインチューニングとは何か
ファインチューニングとは、機械学習の分野において、事前学習済みのモデルの一部または全部に対して再トレーニングを行い、パラメーターの微調整をすることです。「追加学習」とも呼ばれます。再トレーニングには、事前学習時とは別の新しいデータセットが使用され、これにより新たなタスクへの対応などが可能になります。
特徴
ファインチューニングの特徴は、特定のタスクのためにゼロからモデルをトレーニングする必要がなく、既存のモデルを微調整するだけで新たなタスクに対応できる点にあります。
通常、事前学習済みのモデルはそれぞれのタスクに合わせた専門知識が不足していたり、事前学習時点までの古い情報しか持ち合わせていなかったりするために、実際の業務に取り入れようとすると適応できないケースが少なくありません。しかし、かといってゼロからモデルのトレーニングを行おうとすると、膨大なデータを学習させる手間やコストがかかります。そこでファインチューニングを実施することで、追加で必要になった情報のみを学習させ、手間やコストを抑えながら特定のタスクに対応できるように調整できます。
ほかのアプローチとして、外部情報を都度参照することで回答を生成する「RAG(検索拡張生成)」がありますが、どちらの手法がよいかはタスクの内容や要求される精度により異なります。
仕組み
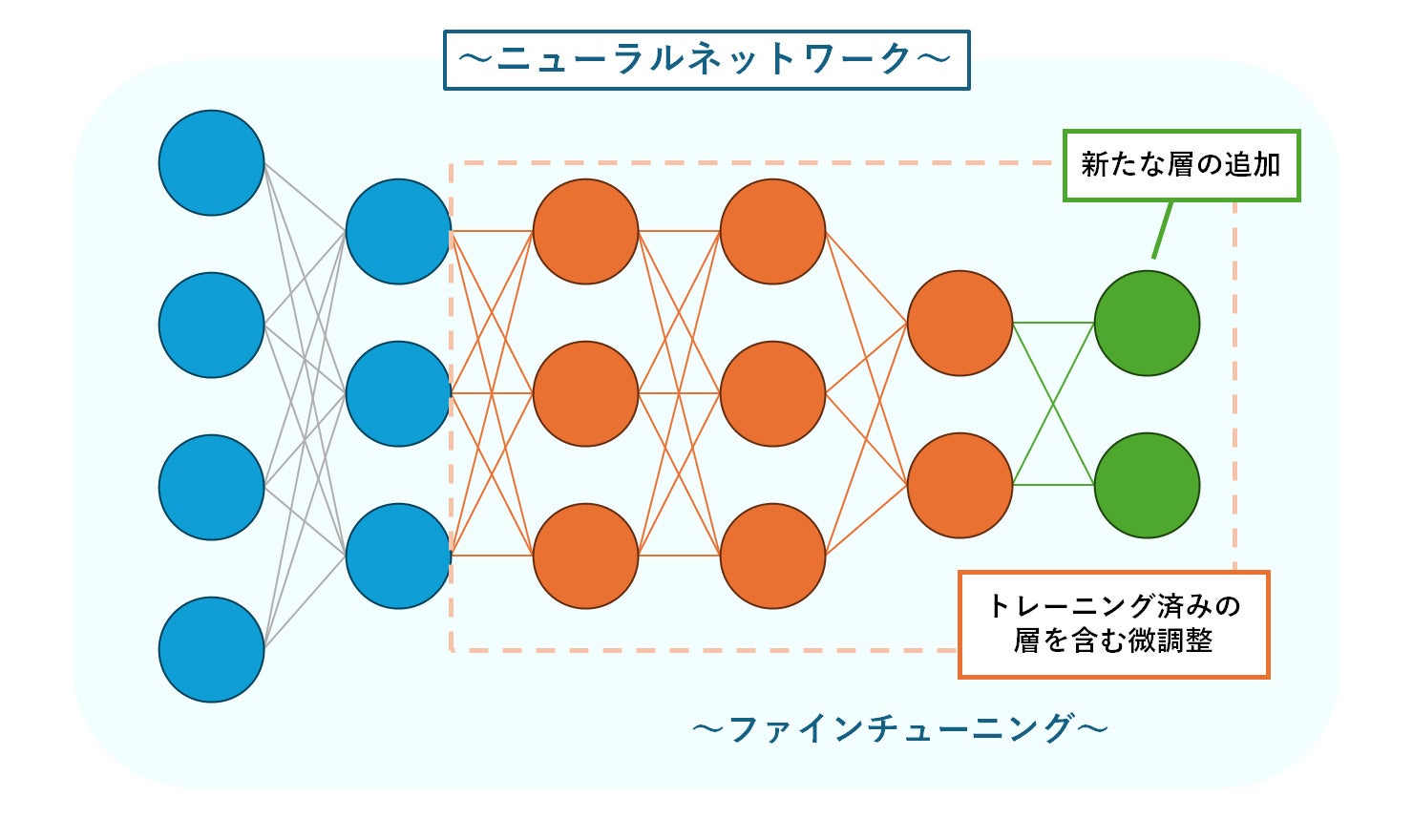
LLM(大規模言語モデル)などのファインチューニングは、すでに大規模なデータセットによるトレーニングを行ったモデルに対し、ニューラルネットワークのパラメーター数をチューニングすることで、新しいデータへの対応力を高める仕組みになっています。
パラメーターとは、機械学習モデルが学習を行う際に最適化する必要のある変数のことです。数が多いほど複雑な学習が可能な反面、リソース不足や過学習のリスクが高まります。そのため、大きければよいというものではなく、適切な数値に設定することが重要です。
ファインチューニングでは、ニューラルネットワークに新しい層を追加したり、トレーニング済みの層も含めて調整を行ったりしながら、タスクの内容に合った最適なパラメーターを見つけ出します。
ファインチューニングが重要な理由
ファインチューニングは前述のような新たなタスクへの対応のほか、ChatGPTなどの自然言語処理モデルの開発段階においても、重要な役割を果たしています。チャットを主体とするAIは、単に回答を生成するだけではなく、ユーザーとの「会話」が成立するように調整しなければならないためです。
たとえば「ドーナツの作り方を教えて」という質問を入力した場合、AIには「ドーナツの作り方を説明する」というアウトプットのほか、「質問の背景を付与する」「より詳しい情報を得るために質問を返す」などの選択肢が生まれます。そこで、高品質なデータを用いたファインチューニングを行うことで、場面ごとによりユーザーが求めている内容に近い選択を取れるようになっていきます。
ファインチューニングの実施手順
ニューラルネットワークのファインチューニングは、本来はコードを書く必要があるものですが、現在は簡単に実行できるよう考慮されているモデルもあります。
ChatGPTのベースにもなっている言語モデル、「GPT」もその一つです。GPTのファインチューニングでは、ニューラルネットワーク内の情報を確認しながら調整が必要な範囲を探ったり、モデルの精度確認をしたりする必要はありません。大まかな流れは、以下の3ステップに分けられます。
1.ファインチューニング用の学習データを準備
入力内容を示す「prompt」と出力結果を示す「completion」をセットにして一行にまとめた学習データを、多数用意します。データを準備する際は事前にタスクを定義し、どのような質問に答えられるAIにしたいのかを明確にした上で、その内容に関連したデータを収集します。データ収集にあたっては、多様性と量を十分に確保することも重要です。
2.OpenAIのWebサイトに準備したデータをアップロード
GPTの開発会社である「OpenAI」のWebサイトに、データをアップロードします。アップロードを行う際は、事前にOpenAI社のウェブページからAPIキーを取得しておきます。
3.ベースモデルのファインチューニングを実行
実行をリクエストすると、「prompt」と「completion」の関係性をモデルが学習します。ファインチューニングはOpenAIのWebサイト上で実行され、ファイルサイズによって数分から数時間程度かかります。
ファインチューニングで学習させるデータの例
AIの回答精度は、学習データの内容に大きく左右されます。ファインチューニングを行いたい場合、主な収集対象となるデータ例には以下のようなものがあります。
社内に存在する非公開データ
一般公開されている事前学習済みのモデルは、インターネット上からデータを収集するケースも多く、開発時点でアクセスできなかった情報については必然的に未学習となります。そのため、企業が独自に管理しているドキュメントやマニュアルなど、インターネット上に公開されていない情報を踏まえたタスクに対応させたい場合は、社内データを使ったファインチューニングを実施しなければなりません。
トレーニングが成功すれば、社内文書の内容についてAIだけで回答できるようになる可能性もあります。ただし、社内データには機密性の高い情報も多くあるため、トレーニングに利用するデータを選ぶ際は、機密性の面で問題がないか十分に確認しておくことが重要です。
専門性が高い分野のデータ
特徴の項目でもご紹介したように、専門性の高い情報が不足していることも、ファインチューニング実施前のモデルの欠点といえます。なかには、「Transformer」という技術をベースにしたLLMなど、LLM単体で推論が行えることを目標としているモデルもありますが、それでも対応しきれない分野は存在します。
高い専門性が求められる例には、法律や医療、金融などの分野があります。医療であれば、患者の病歴や検査データ、薬剤の情報などを追加で学習させ、特定の業務や専門的な情報の抽出を行えるようにするケースが考えられます。また金融機関では、取引データや顧客の財務情報、市場動向などを学習させることで、予測や分析、投資戦略の改善、リスク管理に対応するAIの実現が期待できます。
最近公開されたばかりのデータ
LLMなどのモデルは基本的に、一定の期間にインターネット上から収集した情報を基に事前学習を行って作られています。そのため、インターネット上に公開されたばかりの情報はまだ学習していない場合があります。
最新のデータを使ったファインチューニングが行われていないと、ただ新しい知識が欠けているだけでなく、更新前の情報を参照したために誤った回答を生成してしまう恐れもあります。こうしたリスクを避けるため、インターネットに公開されて間もないデータも収集対象に含めることが推奨されます。最新情報までカバーすることで、よりタイムリーな情報を基にした推論を行うことができ、回答精度の向上にもつながります。
まとめ
正確かつ適切な回答を提供できるAIを実現するためには、ファインチューニングが欠かせません。ファインチューニングをうまく活用できれば、ゼロから機械学習を行う手間をかけずに、優れた既存のモデルをベースとして専門的な業務に対応するAIの導入も目指せます。
急速に成長を続けるAIを業務に取り入れることは、企業としての競争力強化にもつながる可能性があります。自社の業務に合ったモデルを用意したいとお考えの際は、ぜひファインチューニングの活用を検討してみてください。

