Transformerとは? 仕組みやメリットを初心者向けにわかりやすく解説

ChatGPTの登場により、自然言語処理を活用したAIツールは身近なものになりつつあります。こうした急速な技術の進歩の裏にあるのが、「Transformer」というニューラルネットワークの誕生です。この記事では、現代の深層学習モデルの根幹を担うTransformerの概要や成り立ち、仕組み、メリットのほか、Transformerを利用した代表的なモデルや関連する専門用語の意味などを解説していきます。
Transformerとは何か
Transformerとは、深層学習(ディープラーニング)の基礎となる技術である「ニューラルネットワーク」の一種です。Googleの研究者らが2017年に発表した「Attention Is All You Need(アテンションこそすべて)」という論文で初めて登場しました。従来型の深層学習モデルよりも高速かつ高精度な自然言語処理を実現できるのが特徴です。
Transformerの中核をなすのが「Attention」と呼ばれる機構です。文章中の注意(Attention)すべきポイントがどこにあるのかを特定することで、各単語が文章全体の中で担っている役割を把握し、文脈に応じた適切な解釈を可能にしています。また、並列処理が可能で長期記憶が得意な点も、従来型より優れています。
Transformerの成り立ち
Transformerの登場前は「RNN(再帰型ニューラルネットワーク)」という技術をベースとした深層学習モデルが一般的で、文章の文脈は理解できる一方、長期記憶が苦手な上、並列処理もできないという欠点がありました。そのため、Attentionは「RNNと組み合わせて弱点を補うもの」として利用されていましたが、「RNNを使わずAttentionだけを使えば問題を解決できる」という革新的な考えの基で生まれたのがTransformerです。
はじめは機械翻訳などの系列変換タスクに利用される想定だったTransformerでしたが、「GPT」や「BERT」といった言語モデルに利用されたことで、自然言語処理の分野で広く活躍するようになりました。さらに、「CNN(畳み込みニューラルネットワーク)」に続く画像処理技術として「Vision Transformer(ViT)」が登場するなど、自然言語処理以外の分野でも有用性が明らかになっています。
Transformerの主な構成
Transformerを構成する仕組みは主に、入力データを処理する「エンコーダー」と、出力データを生成する「デコーダー」の2つに分けられます。ここでは、それぞれの工程で行われる具体的な処理内容について説明します。
エンコーダー
エンコーダーでは以下のような流れで、入力データを機械で処理できる形式に変換していきます。
- 文章を単語ごとに区切る
- 各単語を数値のベクトルに変換する
- 「Self-Attention」によって各単語とほかの単語との関連性を評価する
- 「FNN(フィードフォワードニューラルネットワーク)」によって特徴量に変換する
- 解析結果をデコーダーに渡す
従来のAttentionは、「どこに注意を向けるか」を判断する材料を外部データから得る必要がありましたが、Transformerは外部データを必要としない「Self-Attention(自己注意機構)」という技術により、手持ちのデータに含まれる単語同士のみの関連性から文脈を捉えることができます。
例えば「犬が元気に走る」という文章なら、1番目の処理で「犬/が/元気/に/走る」のように分けられた後、各単語同士にどのくらい関連性があるのかを判断します。
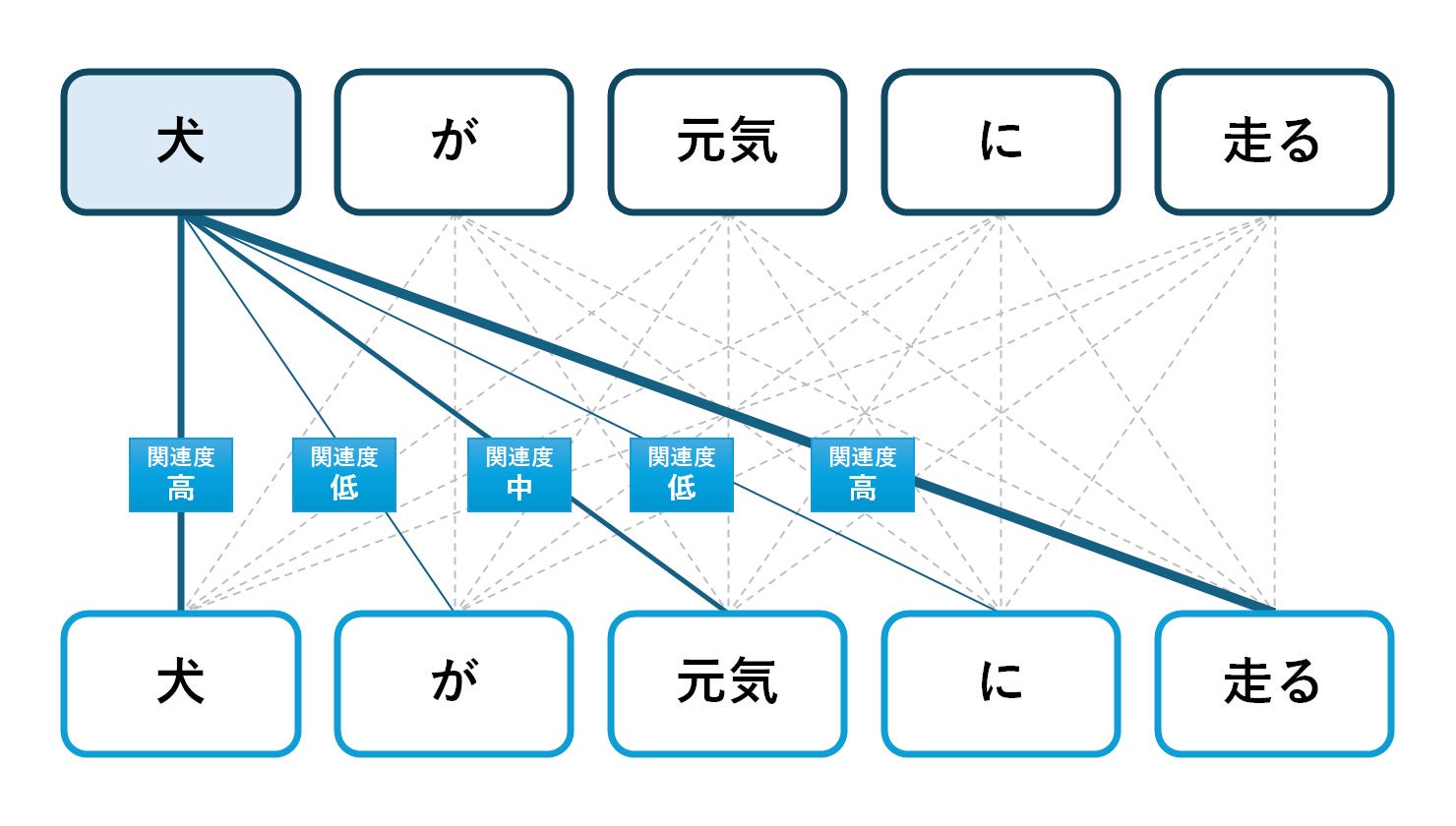
また、「特徴量」は各データの特徴を定量的な数値として表したもののことです。機械学習において予測や分類を行うためには、この特徴量が重要な手掛かりとなります。
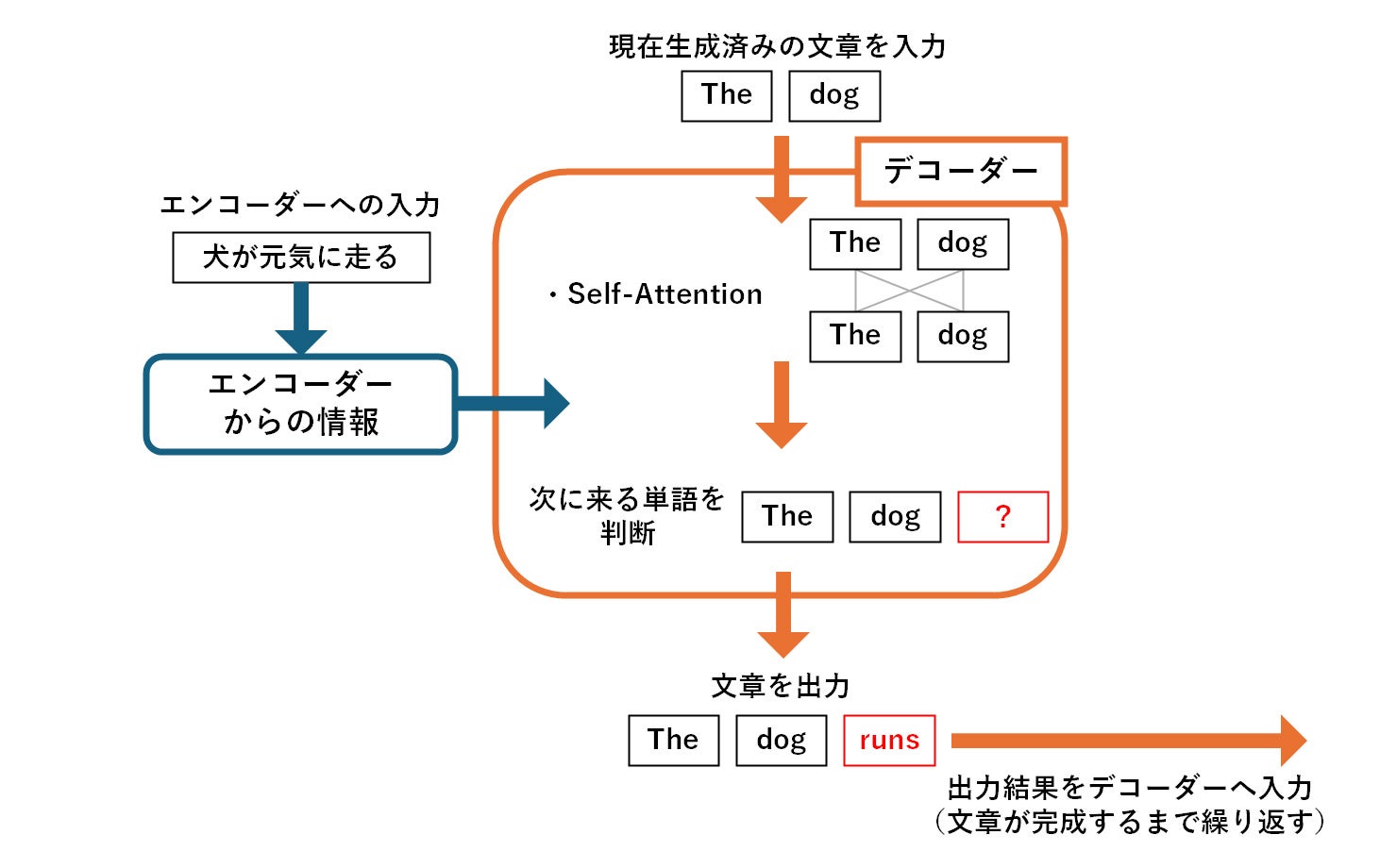
デコーダー
デコーダーは、エンコーダーから受け取った情報と、自身がここまでに生成した単語の情報とを組み合わせながら、次に生成すべき単語の予測を行います。この時、以下のような手順を踏むことで、文脈を踏まえたより自然な文章の生成を実現しています。
- 「Self-Attention」によって生成した単語同士の関連性を計算する
- エンコーダーからの情報と現在生成した単語の状態との関連性を評価する
- 「FNN」によって特徴量を変換する
- ソフトマックス関数を利用して次に来る単語の確率分布を出力する
- 確率分布を基に、生成する単語を決定する
デコーダーは、こうした処理を繰り返すことで関連性をチェックしながら出力結果を生成していく、自己回帰型モデルです。エンコーダー、デコーダーはともにAttention機構がベースとなります。
Transformerを活用するメリット
ここまでにもご紹介したとおり、Transformerは並列処理への対応やAttention機構の採用を通して、迅速かつ高精度な処理を可能にしています。ここでは、Transformerを活用する主なメリットについてより詳しくご紹介していきます。
並列処理によって計算効率が向上する
従来型で採用されていたRNNは、一単語ずつしか処理を行えず、学習を一つひとつ行っていかなければなりませんでした。しかし、Transformerのエンコーダーは複数の単語を同時に処理できるため、計算効率の大幅な向上が見込めます。そのためTransformerは大量のデータセットを使用する学習にも有用です。
高精度の翻訳が実現できる
Transformerは、「Self-Attention」で単語同士の関連性について学習し、文脈をより深く理解した上で翻訳することができます。学習速度が速く、長文であっても文章全体の関係性を捉えられるほか、同音異義語なども文脈に応じて使い分け、自然な翻訳結果を生成することが可能です。
長期的な記憶が可能になる
従来型モデルのもう一つの課題として、「長期記憶が苦手」という特徴がありました。一単語ずつ順番に処理をするRNNは、長い文章を処理していると、途中で最初に出てきた情報を忘れてしまうためです。このような課題も、並列処理によってスピーディーに作業を進めれば解決するため、Transformerなら適切に文章を処理できます。
Transformerを基にしたモデル6選
Transformerをベースとしたモデルは多数開発され、幅広い分野で活用されています。Transformerの主な活躍の場として知られる「言語モデル」を中心に、代表的なものを6つご紹介します。
1.GPT
「GPT」は、ChatGPTに利用されていることでも知られる、OpenAI社が開発した言語生成モデルです。「Generative Pretrained Transformer」の略称で、名前にも「Transformer」が含まれています。
大規模なデータを用いて事前学習を行ったTransformerのデコーダーをベースとしており、文章の前後関係まで考慮して表現を学習しているため、自然な文章の生成が可能です。2018年の登場以来、その技術は年々進化しており、現在では最初期のものよりはるかに大きなパラメーターとデータセットを使用して学習させたモデルが発表されています。
ChatGPTのような対話形式のシステムのほか、文章の作成や要約、分類、文の補完など、さまざまな用途で活用できます。
2.BERT
「BERT(Bidirectional Encoder Representations from Transformers)」は、2018年にGoogle社が開発した、汎用性の高さが特徴の自然言語処理モデルです。BERTはTransformerのエンコーダーによって文章中の単語表現を学習し、質疑応答や感情の分析、文章の分類など、幅広いタスクに対応します。
例えば感情の分析では、対象となる文章が「肯定的」か「否定的」か、どちらの感情で書かれているのかを読み取ることが可能です。そのため、「作品に寄せられたレビューから平均的な評価を分析する」といったタスクも高精度で行えます。BERTは今後、言葉に隠された「暗黙の了解」を読み取るなど、より深い言語理解にも役立つといわれています。
公開されている事前学習済みモデルを活用できる場面が多いため、学習データの準備が不十分でも高い精度を得やすいという利点もあります。
3.PaLM
「PaLM(Pathway Language Model)」は、2022年に発表された言語モデルです。BERTと同様、TransformerをベースとしてGoogle社によって開発されたモデルですが、5,400億のパラメーターを持ち、自然言語処理のほかにもさまざまな処理に対応できるという特徴があります。
PaLMでは言語理解や翻訳のほか、推論やプログラミングコードの作成が可能です。推論によって算数の問題文から答えを導き出したり、ジョークの意味を解説したりといった使い方に成功した事例もあります。プログラミングの分野では、人が文章で指示した内容を受けて、ほかのプログラミング言語への変換やバグの修正などの作業を行えます。
2023年には次世代モデルの「PaLM2」も発表され、より多くの言語を理解できるようになり、推論能力もレベルアップしています。
4.Conformer
「Conformer」は、TransformerとCNNを組み合わせたモデルで、2020年に発表されました。
Transformerは距離の遠い単語間の関係性まで把握でき、長文でも全体の文脈を捉えるのが得意という特徴があるのに対し、CNNは局所的な特徴の抽出を得意としています。そこで、両者を組み合わせて補完し合うことで、特に音声認識の分野で力を発揮できるモデルとして誕生したのがConformerです。RNNをベースにしたモデルと比べて、少ないパラメータでも高精度な音声認識が可能です。
例えば文字起こしなどのタスクでは、CNNが音声データの波形といった細かなパターンを抽出して言葉を特定し、その言葉をTransformerによって文脈を考慮した文章に整える、というような処理を行えます。
5.Deformer
「Deformer」は、Transformerの仕組みをベースに改良を加えたモデルです。具体的には、事前に学習を行ったTransformerベースのモデルに対し、「分解」の要素を取り入れることで、より高速に処理を実行できるようにしています。
Transformerでは通常、文章のすべてにAttentionを実行しますが、実際にはAttentionを実行する必要がない部分もあり、メモリの無駄遣いで処理速度が遅くなるという課題がありました。そこでDeformerでは、文章を分解してAttentionが不要な層を分けて考える仕組みにすることで、使用メモリを削減しました。
Deformerなら、質疑応答などのタスクに短時間で対応でき、大規模なデータセットを用いた学習も効率よく行えます。Transformerを応用できる範囲をさらに広げるものとして、注目を集めているモデルです。
6.T5
「T5(Text-to-Text Transfer Transformer)」は、Google社が2020年に発表したテキスト生成モデルです。Transformerをベースとしていますが、使用するパラメーターやモデルの構造などを調整することで、より精度が高く活用しやすいモデルとなっています。
T5の最大の特徴は、入力と出力の両方をテキストで行う点にあります。どんなタスクもテキストで処理をするよう統一することで、タスクごとに学習をし直す必要がなくなり、一つのモデルでさまざまな場面に対応可能です。
言い換えや質疑応答といった自然言語処理タスクを評価するテストでは、高難易度のテストでも高い精度を達成した実績があり、汎用性だけでなく精度にも優れたモデルとして活躍しています。
Transformerに関連する用語
RNNやCNNをはじめとして、Transformerを語る上で欠かせない専門用語は多々あります。ここでは、特に重要なワードである「RNN」「CNN」「深層学習」「自然言語処理」の概要を解説していきます。
RNN、CNN
RNNやCNNは、ほかの項目でも触れたとおり、Transformerの登場以前から利用されてきたニューラルネットワークの一種です。
RNN(再帰型ニューラルネットワーク)
RNNは「リカレントニューラルネットワーク」の略称です。データが入力から出力まで一方向に流れるのではなく、回帰的・循環的になっていることで、株価の動向などの「時間経過による変化が存在するデータ」を扱えるのが特徴です。また、テキストの文脈を考慮することもできます。
CNN(畳み込みニューラルネットワーク)
CNNは「コンボリューショナルニューラルネットワーク」の略称です。個性的な機能を備えた複数の「層」で構成されているのが特徴で、特に画像認識の分野で活躍しています。生物の脳の視覚野と呼ばれる部位からヒントを得た構造になっており、一部が見えにくくなっている画像を解析することなども可能です。
深層学習(ディープラーニング)
深層学習とは、機械学習の手法の一つで、人間の神経細胞の仕組みをまねて作られた「ニューラルネットワーク」を多層構造にして用いているのが特徴です。音声認識や画像認識、自然言語処理などさまざまな分野で成果を上げています。
認識精度を高めるために膨大な学習データが必要になる点が課題となっていましたが、近年はインターネットの普及でデータの用意がしやすくなったこともあり、急速に進化を遂げています。
学習方法には、明確な正解がある事柄について正解・不正解を示す「教師あり学習」のほか、正解のないデータから法則や特徴を見つけ出す「教師なし学習」などがあります。
自然言語処理(NLP)
人が日常的なやりとりで使用する言葉は、「自然言語」と呼ばれます。自然言語処理とは、この自然言語を処理・分析する技術を指します。自然言語処理機能を搭載したAIは、日本語や英語といった自然言語で書かれたテキストを分析したり、生成したりすることが可能です。
自然言語の中には、同音異義語や、あえて曖昧な言葉を使用しているものなど、機械的に理解するのが難しい表現も存在します。しかし近年は、ビッグデータの活用や深層学習の進化によって、こうした言葉も文脈から理解できるモデルが登場しています。
身近なところでは、検索エンジンでキーワードに沿ったWebサイトを見つけるためのテキストデータの処理や、文字入力時の予測変換、スマートスピーカーでの音声対話などに活用されています。
まとめ
ここまで、自然言語処理モデルの発展に大きな影響を与えた「Transformer」について、成り立ちや構成、メリット、具体的なモデルの例などをご紹介しました。
Transformerをベースとした深層学習モデルは、迅速かつ高精度な処理で幅広い分野に利用できる上に、今後もさらに発展していくことが期待されています。ぜひ、自社の業務への活用を検討してみてください。

